Giải thích chi tiết về cấu trúc dữ liệu nội bộ của Redis (7) —— intset
2016-11-22
Phân tích cấu trúc dữ liệu nội bộ của Redis Phân tích cấu trúc dữ liệu nội bộ của Redis Bài viết này là phần thứ bả Trong nội dung hôm naykeo 88, chúng ta sẽ cùng tìm hiểu về một cấu trúc dữ liệu nội bộ của Redis — intset. Đây là một thành phần quan trọng giúp tối ưu hóa việc lưu trữ các giá trị nguyên trong cơ sở dữ liệu, cho phép tăng hiệu suất và tiết kiệm không gian. Hãy cùng khám phá sâu hơn về cách hoạt động cũng như ưu điểm của intset trong hệ thống Redis!
Trong Redis99WIN, việc sử dụng **intset** được thiết kế để thực hiện cấu trúc dữ liệu **set** (tập hợp) mà Redis cung cấp cho người dùng. Set trong Redis tương tự như khái niệm tập hợp trong toán học, tức là các phần tử trong set không có thứ tự cố định và không được phép lặp lại. Ngoài ra, set trong Redis còn hỗ trợ các thao tác cơ bản của tập hợp như hợp (**union**), giao (**intersection**) và hiệu (**difference**). Tương tự như các cấu trúc dữ liệu khác mà Redis công khai với người dùng, cách thức triển khai bên dưới của set sẽ thay đổi tùy thuộc vào loại dữ liệu của các phần tử cũng như số lượng phần tử được thêm vào. Tóm lại, khi set chỉ chứa các phần tử dạng số nguyên (**integer**) và số lượng phần tử này không quá lớn, Redis sẽ sử dụng **intset** làm cấu trúc lưu trữ bên dưới. Intset là một cấu trúc đặc biệt tối ưu hóa cho các tập hợp toàn số nguyên, giúp tiết kiệm bộ nhớ và tăng tốc độ xử lý. Ngược lại, nếu set bao gồm các phần tử không phải số nguyên hoặc số lượng phần tử vượt quá ngưỡng cho phép, Redis sẽ chuyển sang sử dụng **hashtable** – một cấu trúc dữ liệu linh hoạt hơn nhưng chiếm nhiều tài nguyên hơn. Điều này giúp đảm bảo rằng Redis luôn hoạt động hiệu quả trong mọi trường hợp sử dụng. dict Được sử dụng như cấu trúc dữ liệu cơ sở.
Trong bài viết này99WIN, chúng ta sẽ giới thiệu đại khái thành ba phần:
- Tập trung trình bày cấu trúc dữ liệu intset.
- Thảo luận cách set được xây dựng trên intset và dict dựa trên đó.
- Chúng ta hãy cùng đi sâu vào việc thảo luận về các thuật toán để thực hiện các phép toán cơ bản của tập hợp (set) như hợpkeo 88, giao và hiệu trong lập trình. Đặc biệt, khi nói đến phép tính hiệu tập hợp (difference set), Redis đã áp dụng hai phương pháp khác nhau để tối ưu hóa quá trình này. Việc hiểu rõ các thuật toán và độ phức tạp thời gian (time complexity) sẽ giúp chúng ta lựa chọn cách tiếp cận phù hợp nhất tùy thuộc vào yêu cầu cụ thể của ứng dụng.
Trong quá trình thảo luậnsv 88, chúng ta sẽ còn đề cập đến một cấu hình Redis (phần CẤU HÌNH NÂNG CAO trong tệp redis.conf):
set-max-intset-entries 512
Lưu ý: Việc phân tích mã nguồn trong bài viết này dựa trên nhánh 3.2 của mã nguồn gốc của Redis.
Giới thiệu về cấu trúc dữ liệu intset
Từ "intset" có thể được hiểu đơn giản là một tập hợp bao gồm các số nguyên. Thực tếkeo 88, intset không chỉ là một tập hợp mà còn là một tập hợp có thứ tự của các số nguyên, giúp việc tìm kiếm nhị phân trở nên dễ dàng hơn. Điều này cho phép xác định nhanh chóng xem một phần tử có thuộc về tập hợp đó hay không. Về mặt phân bổ bộ nhớ, intset... ziplist Một số cái tương tự99WIN, là một vùng nhớ liên tục và nguyên khối, đồng thời sử dụng các phương thức mã hóa khác nhau cho số nguyên lớn và số nguyên nhỏ (theo giá trị tuyệt đối), nhằm tối ưu hóa việc sử dụng bộ nhớ một cách hiệu quả nhất có thể.
Định nghĩa cấu trúc dữ liệu của intset như sau (trích từ intset.h và intset.c):
typedef
struct
intset
{
uint32_t
encoding
;
uint32_t
length
;
int8_t
contents
[];
}
intset
;
#define INTSET_ENC_INT16 (sizeof(int16_t))
#define INTSET_ENC_INT32 (sizeof(int32_t))
#define INTSET_ENC_INT64 (sizeof(int64_t))
Ý nghĩa của từng trường như sau:
-
encodingTrong quá trình mã hóa dữ liệu99WIN, intset sẽ xác định kích thước lưu trữ cho mỗi phần tử dữ liệu. Có ba khả năng chính về giá trị mã hóa: INTSET_ENC_INT16 sẽ sử dụng 2 byte để lưu trữ mỗi phần tử, INTSET_ENC_INT32 sử dụng 4 byte và INTSET_ENC_INT64 sử dụng 8 byte. Do đó, các số nguyên được lưu trong intset có thể chiếm tối đa 64 bit. Điều này cho phép hệ thống tối ưu hóa bộ nhớ tùy thuộc vào phạm vi giá trị mà intset cần xử lý, từ đó đảm bảo hiệu suất và tính linh hoạt trong việc quản lý dữ liệu. -
length: Thể hiện số lượng phần tửencodingvàlengthHai trường này tạo nên phần đầu (header) của intset. -
contents: Là một mảng linh hoạt ( flexible array member Bạn có thể xem intset sau phần header sẽ ngay lập tức chứa các phần tử dữ liệu. Mảng này có độ dài tổng cộng (tức là tổng số byte) được tính bằng cách cộng thêm...encoding * length). Mảng linh hoạt xuất hiện trong nhiều định nghĩa cấu trúc dữ liệu của Redis (ví dụ sds , quicklist , skiplist )sv 88, dùng để biểu thị một khoảng cách.contentsCần phải cấp phát bộ nhớ riêng cho nókeo 88, phần bộ nhớ này không bao gồm trong cấu trúc intset.
Điều cần lưu ý là intset có thể thay đổi mã hóa dữ liệu khi thêm dữ liệu:
- Ban đầusv 88, khi intset vừa được tạo ra, nó sẽ sử dụng định dạng mã hóa INTSET_ENC_INT16 (có kích thước 2 byte) để lưu trữ dữ liệu, đây là cách chiếm ít bộ nhớ nhất có thể.
- Mỗi khi thêm một phần tử mớikeo 88, sẽ quyết định xem có cần nâng cấp mã hóa dữ liệu hay không dựa trên kích thước của phần tử.
Hình dưới đây cho thấy một ví dụ cụ thể khi thêm dữ liệu (nhấn để xem hình lớn).

Trong hình trên:
- Intset mới chỉ có headersv 88, tổng cộng 8 byte. Trong đó
encoding= 2,length= 0。 - Sau khi thêm hai phần tử 13 và 599WIN, vì chúng là các số nguyên nhỏ có thể được biểu diễn bằng 2 byte, nên
encodingKhông thay đổisv 88, giá trị vẫn là 2. - Khi thêm 32768 vàosv 88, giá trị đó đã vượt ra ngoài khả năng biểu diễn củ Hai byte trong hệ nhị phân có thể lưu trữ phạm vi từ -32768 đến 32767, vì vậy khi vượt quá giới hạn trên (32767), cần phải sử dụng nhiều byte hơn để lưu trữ giá trị mới này một cách chính xác.
15
~2
15
-1, và 32768 bằng 2
15
99WIN, vượt quá phạm vi), do đó
encodingCần nâng cấp lên INTSET_ENC_INT32 (giá trị là 4)sv 88, tức là sử dụng 4 byte để biểu diễn một phần tử. - Trong quá trình thêm mỗi phần tử99WIN, intset luôn duy trì thứ tự từ bé đến lớn.
-
Và
ziplist
Tương tự như vậysv 88, intset cũng được lưu trữ theo chế độ little endian (xem thêm tại trang web Wikipedia). Intset là một cấu trúc dữ liệu đặc biệt trong Redis, được thiết kế để lưu trữ tập hợp các giá trị nguyên. Việc sử dụng chế độ lưu trữ little endian giúp tối ưu hóa không gian và tăng tốc độ truy xuất dữ liệu. Theo định nghĩa của little endian, các byte thấp hơn sẽ được lưu trước trong bộ nhớ, điều này có thể cải thiện hiệu suất khi thực hiện các phép toán số học hoặc xử lý dữ liệu trên nền tảng phần cứng hiện đại. Nếu bạn muốn tìm hiểu thêm về cách hoạt động của little endian, hãy tham khảo bài viết chi tiết từ Wikipedia hoặc tài liệu chính thức của Redis. Những nguồn tài liệu này sẽ cung cấp cho bạn cái nhìn sâu sắc hơn về lý do tại sao Redis lại chọn chế độ này và những lợi ích mà nó mang lại trong việc quản lý bộ nhớ.
Endianness
). Ví dụsv 88, trong hình trên, sau khi intset thêm tất cả dữ liệu, nó thể hiện
encodingCác 4 byte đầu tiên của trường này nên được giải thích là giá trị 0x00000004sv 88, trong khi dữ liệu thứ 5 sẽ tương ứng với giá trị 0x000186A0, tức là 100.000 theo biểu diễn thập phân. Điều thú vị là việc phân tích các byte này thường liên quan đến việc hiểu rõ cách hệ thống mã hóa và tổ chức dữ liệu hoạt động, đặc biệt là trong các định dạng lưu trữ hoặc truyền tải thông tin phức tạp.
So với intset và ziplist so sánh:
- Ziplist có thể lưu trữ bất kỳ chuỗi nhị phân nàokeo 88, còn intset chỉ có thể lưu trữ số nguyên.
- Ziplist là cấu trúc không có thứ tựkeo 88, trong khi intset được sắp xếp theo thứ tự tăng dần. Do đó, việc tìm kiếm trong ziplist yêu cầu duyệt qua từng phần tử một, còn với intset, bạn có thể áp dụng phương pháp tìm kiếm nhị phân, giúp cải thiện hiệu suất đáng kể. Điều này cho thấy sự khác biệt rõ rệt về khả năng xử lý giữa hai cấu trúc dữ liệu này, đặc biệt khi làm việc với tập hợp lớn các phần tử.
-
Ziplist có thể mã hóa biến dài khác nhau cho từng mục dữ liệu (mỗi mục dữ liệu trước tiên có trường độ dài dữ liệu
len)99WIN, trong khi intset chỉ có thể sử dụng mã hóa thống nhất (encoding)。
Các hoạt động tìm kiếm và thêm vào intset
Để hiểu rõ hơn về một số chi tiết thực hiện của intsetsv 88, bạn chỉ cần tập trung vào hai thao tác quan trọng chính của nó: tìm kiếm (search) và...
intsetFind
) và thêm (
intsetAdd
) phần tử.
intsetFind
Mã nguồn chính liên quan như sau (trích từ intset.c):
uint8_t
intsetFind
(
intset
*
is
,
int64_t
value
)
{
uint8_t
valenc
=
_intsetValueEncoding
(
value
);
return
valenc
<=
intrev32ifbe
(
is
->
encoding
)
&&
intsetSearch
(
is
,
value
,
NULL
);
}
static
uint8_t
intsetSearch
(
intset
*
is
,
int64_t
value
,
uint32_t
*
pos
)
{
int
min
=
0
,
max
=
intrev32ifbe
(
is
->
length
)
-
1
,
mid
=
-
1
;
int64_t
cur
=
-
1
;
/* The value can never be found when the set is empty */
if
(
intrev32ifbe
(
is
->
length
)
==
0
)
{
if
(
pos
)
*
pos
=
0
;
return
0
;
}
else
{
/* Check for the case where we know we cannot find the valuesv 88,
* but do know the insert position. */
if
(
value
>
_intsetGet
(
is
,
intrev32ifbe
(
is
->
length
)
-
1
))
{
if
(
pos
)
*
pos
=
intrev32ifbe
(
is
->
length
);
return
0
;
}
else
if
(
value
<
_intsetGet
(
is
,
0
))
{
if
(
pos
)
*
pos
=
0
;
return
0
;
}
}
while
(
max
>=
min
)
{
mid
=
((
unsigned
int
)
min
+
(
unsigned
int
)
max
)
>>
1
;
cur
=
_intsetGet
(
is
,
mid
);
if
(
value
>
cur
)
{
min
=
mid
+
1
;
}
else
if
(
value
<
cur
)
{
max
=
mid
-
1
;
}
else
{
break
;
}
}
if
(
value
==
cur
)
{
if
(
pos
)
*
pos
=
mid
;
return
1
;
}
else
{
if
(
pos
)
*
pos
=
min
;
return
0
;
}
}
Về mã nguồn trênkeo 88, chúng ta cần chú ý những điểm sau:
-
intsetFindTìm kiếm phần tử được chỉ định trong intset đã chovalue99WIN, tìm thấy trả về 1, không tìm thấy trả về 0. -
_intsetValueEncodingHàm sẽ tính toán mã hóa dữ liệu tương ứng (tức là nó nên sử dụng bao nhiêu byte để lưu trữ) dựa trên phần tử được tìm kiếmvaluenằm trong phạm vi nào. -
Thực hiện thuật toán tìm kiếm nhị phân.
valueNếu dữ liệu cần thiết phải mã hóa lớn hơn định dạng mã hóa hiện tại của intset99WIN, điều đó có nghĩa là nó nằm ngoài phạm vi lưu trữ mà intset có thể xử lý (quá lớn hoặc quá nhỏ), do đó, ở tình huống này, hàm sẽ trả về 0 ngay lập tức. Nếu không, nó sẽ tiếp tục thực hiện các bước tiếp theo để gọi phương thức tương ứng.intsetSearch99WIN, nếu tìm thấy thì trả về 1 và tham số -
intsetSearchTìm kiếm phần tử được chỉ định trong intset đã chovalueTrỏ đến vị trí phần tử được tìm thấy; nếu không tìm thấy thì trả về 0 và tham sốposTrỏ đến vị trí có thể chèn phần tử này.posĐây là một thực hiện của thuật toán tìm kiếm nhị phân99WIN, nó chia thành ba phần chính: -
intsetSearchXử lý đặc biệt trường hợp intset rỗng.- Xử lý đặc biệt hai trường hợp biên: khi phần tử cần tìm kiếm
- Thật sự thực hiện quá trình tìm kiếm nhị phân. Lưu ý: Nếu cuối cùng không tìm thấy99WIN, vị trí chèn ở
valueKhi giá trị lớn hơn phần tử cuối cùng hoặc nhỏ hơn phần tử đầu tiên. Thực tế99WIN, việc xử lý đặc biệt cho hai phần này không phải là bắt buộc trong thuật toán tìm kiếm nhị phân, nhưng ở đây nó cung cấp khả năng nhanh chóng kết thúc quá trình trong một số trường hợp đặc biệt. Trong thực tế, khi thực hiện tìm kiếm nhị phân, chúng ta thường tập trung vào việc chia mảng làm hai nửa và so sánh giá trị cần tìm với phần tử giữa mảng. Tuy nhiên, trong một số trường hợp cụ thể, nếu nhận thấy giá trị nằm ngoài phạm vi của các phần tử trong mảng (lớn hơn phần tử cuối cùng hoặc nhỏ hơn phần tử đầu tiên), việc xác định ngay lập tức rằng giá trị đó không tồn tại trong mảng sẽ giúp tiết kiệm thời gian đáng kể thay vì tiếp tục lặp đi lặp lại các bước chia mảng. Hãy tưởng tượng bạn đang tìm một cuốn sách trong một thư viện có hàng nghìn cuốn sách được sắp xếp theo thứ tự. Nếu bạn biết chắc rằng cuốn sách bạn tìm không thuộc về bất kỳ ngăn nào của thư viện, thì việc tiếp tục lục tìm từng ngăn sẽ chỉ là sự lãng phí thời gian. Điều tương tự cũng xảy ra trong thuật toán tìm kiếm nhị phân: khi giá trị nằm ngoài phạm vi, chúng ta có thể "thất bại nhanh" để tránh mất thời gian không cần thiết. -
Vị trí được chỉ định.
minTrong mã nguồn xuất hiện
-
Sẽ thực hiện các chuyển đổi tương ứng.
intrev32ifbeđược thiết kế để thực hiện việc chuyển đổi giữa định dạng dữ liệu little-endian và big-endian khi cần thiết. Trước đókeo 88, chúng ta đã biết rằng các phần tử trong intset được lưu trữ theo định dạng little-endian, điều này giúp tối ưu hóa việc truy xuất trên các hệ thống có kiến trúc hỗ trợ định dạng này. Tuy nhiên, khi chạy trên một máy chủ sử dụng định dạng big-endian – nơi mà thứ tự bộ nhớ ngược lại với little-endian – thì vấn đề trở nên phức tạp hơn.intrev32ifbeĐộ phức tạp thời gian tổng thể của thuật toán tìm kiếm này là O(log n). - Thêm phần tử mới vào intset
Tất cả đều được lưu trữ dưới dạng chuỗi; bắt đầu từ trường hợp thứ tư dưới đây99WIN,
intsetAdd
Mã nguồn chính liên quan như sau (trích từ intset.c):
intset
*
intsetAdd
(
intset
*
is
,
int64_t
value
,
uint8_t
*
success
)
{
uint8_t
valenc
=
_intsetValueEncoding
(
value
);
uint32_t
pos
;
if
(
success
)
*
success
=
1
;
/* Upgrade encoding if necessary. If we need to upgradesv 88, we know that
* this value should be either appended (if &amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;gt; 0) or prepended (if &amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lt; 0),
* because it lies outside the range of existing values. */
if
(
valenc
>
intrev32ifbe
(
is
->
encoding
))
{
/* This always succeedskeo 88, so we don't need to curry *success. */
return
intsetUpgradeAndAdd
(
is
,
value
);
}
else
{
/* Abort if the value is already present in the set.
* This call will populate "pos" with the right position to insert
* the value when it cannot be found. */
if
(
intsetSearch
(
is
,
value
,
&
pos
))
{
if
(
success
)
*
success
=
0
;
return
is
;
}
is
=
intsetResize
(
is
,
intrev32ifbe
(
is
->
length
)
+
1
);
if
(
pos
<
intrev32ifbe
(
is
->
length
))
intsetMoveTail
(
is
,
pos
,
pos
+
1
);
}
_intsetSet
(
is
,
pos
,
value
);
is
->
length
=
intrev32ifbe
(
intrev32ifbe
(
is
->
length
)
+
1
);
return
is
;
}
Về mã nguồn trênkeo 88, chúng ta cần chú ý những điểm sau:
-
intsetAdd. NếuvalueĐã tồn tại trước khi thêmkeo 88, thì không lặp lại thêm, lúc này tham sốvalueĐược đặt thành 0; nếusuccessKhông tồn tại trong intset ban đầusv 88, thì sẽvalueChèn vào vị trí thích hợpsv 88, lúc này tham sốvalueĐược đặt thành 0.successNếu phần tử cần thêm - Mã hóa dữ liệu cần thiết lớn hơn mã hóa dữ liệu hiện tại của intsetsv 88, thì sẽ gọi
valueCập nhật mã hóa dữ liệu của intset trước khi chènintsetUpgradeAndAddkeo 88, nếu tìm thấy thì không thêm trùng lặp.value。 -
Nếu không tìm thấy thì gọi
intsetSearch(xem - ). Điều này có thể dẫn đến việc sao chép dữ liệu. Đồng thờikeo 88, trong quá trình gọi
intsetResizeKhi mở rộng bộ nhớ cho intset để có thể chứa các phần tử mới được thêm vào99WIN, điều này là cần thiết vì intset là một khối bộ nhớ liên tục. Khi thực hiện thao tác mở rộng bộ nhớ, nó sẽ dẫn đến việc di chuyển hoặc tái phân bổ bộ nhớ, từ đó gây ra một số tác động nhất định đến hiệu suất và hoạt động của cấu trúc dữ liệu này.reallocĐược thực hiện bởi gọi http://man.cx/realloc Hoàn thành việc sao chép dữ liệu này.intsetMoveTailBạn có thể di chuyển tất cả các phần tử ở vị trí sau điểm chèn về sau một vị tríkeo 88, điều này cũng liên quan đến việc sao chép dữ liệu. Điều đáng lưu ý là,intsetMoveTailĐảm bảo rằng trong quá trình sao chép không gây ra chồng chéo hoặc ghi đè dữ liệukeo 88, xem chi tiếtmemmoveViệc thực hiện cũng sẽ gọimemmoveĐể mở rộng bộ nhớ. Khi cập nhật mã hóakeo 88, http://man.cx/memmove 。 -
intsetUpgradeAndAddViệc thực hiện sẽ lấy từng phần tử từ intset ban đầu99WIN, rồi viết lại bằng mã hóa mới vào vị trí mới.intsetResizeLưu ý kết quả trả về củaintsetUpgradeAndAddTrả về con trỏ intset mới. Nó có thể khác với con trỏ intset truyền vào -
Khi gặp các tình huống tương tự.
intsetAddRõ ràng99WIN, độ phức tạp thời gian tổng thể của thuật toán này là O(n).isTương tự99WIN, có thể khác biệt. Người gọi phải sử dụng intset mới được trả về ở đây để thay thế cho intset cũ mà họ đã truyền vào trước đó. Kiểu mẫu sử dụng giao diện này khá phổ biến trong mã nguồn Redis, ví dụ như khi chúng ta đã từng đề cập đến trước đây. Trong thực tế, các kiểu mẫu xử lý dữ liệu như vậy đóng vai trò quan trọng trong việc tối ưu hóa hiệu suất và giảm thiểu lỗi tiềm ẩn trong quá trình quản lý bộ nhớ của Redis. Điều này đặc biệt hữu ích khi làm việc với các cấu trúc dữ liệu phức tạp, nơi mà tính nhất quán giữa các phiên bản dữ liệu cũ và mới là điều cần thiết. sds và ziplist Set của Redis -
Ví dụ lệnh set
intsetAddÝ nghĩa của các lệnh trên:
Dùng để thêm phần tử vào tập hợp
Để hiểu rõ hơn về cấu trúc dữ liệu set mà Redis cung cấp99WIN, chúng ta hãy cùng tìm hiểu một số lệnh quan trọng của set. Dưới đây là một số ví dụ về các lệnh này: Trước tiên, hãy cùng khám phá lệnh `SADD`, dùng để thêm một hoặc nhiều phần tử vào tập hợp. Ví dụ: ``` SADD myset "apple" SADD myset "banana" "orange" ``` Tiếp theo, lệnh `SMEMBERS` sẽ giúp hiển thị toàn bộ các phần tử hiện có trong tập hợp: ``` SMEMBERS myset ``` Lệnh `SCARD` cho phép kiểm tra số lượng phần tử trong tập hợp: ``` SCARD myset ``` Cuối cùng, lệnh `SISMEMBER` giúp xác định xem một giá trị cụ thể có tồn tại trong tập hợp hay không: ``` SISMEMBER myset "banana" ``` Những lệnh cơ bản này đóng vai trò rất quan trọng khi làm việc với cấu trúc dữ liệ
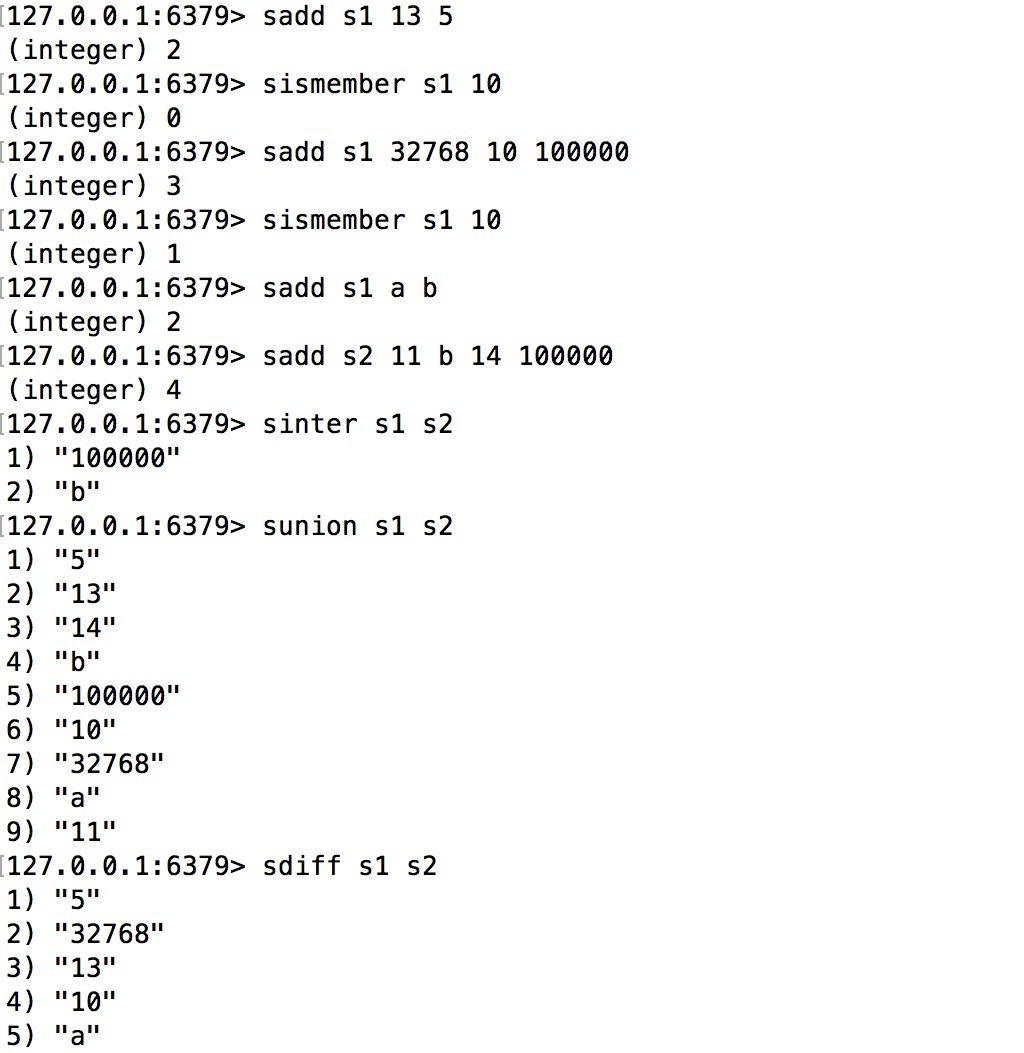
Dùng để kiểm tra xem phần tử được chỉ định có tồn tại trong tập hợp hay không.
-
saddDùng để tính giaokeo 88, hợp và hiệu của các tập hợp.s1vàs2Kết cấu dữ liệu cơ bản sẽ thay đổi như sau: -
sismemberSau khi hoàn thành lệnh -
sinter,sunionvàsdiffsv 88, vì các phần tử được thêm đều là số nguyên nhỏ, nên
Chúng ta đã đề cập trước đó rằng việc triển khai của set sẽ thay đổi tùy thuộc vào kiểu dữ liệu của phần tử99WIN, chẳng hạn như khi phần tử là số nguyên hay không, cũng như số lượng phần tử được thêm vào. Ví dụ cụ thể trong quá trình thực hiện lệnh đã nói ở trên, tập hợp (set) sẽ có sự điều chỉnh về cơ chế hoạt động bên trong để tối ưu hóa hiệu suất. Nếu tập hợp chỉ chứa các giá trị số nguyên và số lượng phần tử ít, thì phương pháp lưu trữ có thể khác so với trường hợp tập hợp có nhiều phần tử phức tạp hơn hoặc không phải là số nguyên. Điều này cho thấy sự linh hoạt và khả năng thích nghi cao của cấu trúc dữ liệu set trong Python, giúp tối ưu hóa hiệu quả xử lý theo từng tình huống cụ thể.
s1
Bên dưới là một intsetkeo 88, mã hóa dữ liệu
-
Sau khi hoàn thành lệnh
sadd s1 13 599WIN, bên dưới vẫn là một intset, nhưng mã hóa dữ liệus1Tăng từ 2 lên 4.encoding= 2。 - Sau đósv 88, vì các phần tử được thêm không còn là số,
sadd s1 32768 10 100000Thực hiện sẽ chuyển sang một dict.s1-199WIN, do đó, nếu số được thêm vượt khỏi phạm vi này, điều này cũng có thể khiến intset chuyểencodingSố lượng phần tử trong tập hợp được thêm vượt quá - Sau đókeo 88, vì các phần tử được thêm không còn là số,
sadd s1 a bMã nguồn liên quan).s1Thuật toán giao99WIN, hợp, hiệu của Redis set
Chúng ta đều biết rằng dict là một cấu trúc dữ liệu được sử dụng để duy trì mối quan hệ ánh xạ giữa key và value. Vậy khi set được biểu diễn dưới dạng dictsv 88, thì key và value của nó thực sự là gì? Thực tế, key chính là phần tử mà chúng ta muốn thêm vào tập hợp, còn value lại là null (không giá trị). Điều này giúp cho việc kiểm tra sự tồn tại của các phần tử trong set trở nên hiệu quả hơn, vì dict có khả năng truy xuất nhanh dựa trên key.
Ngoài lý do đã đề cập trước đó99WIN, đó là việc thêm các phần tử không phải số nguyên dẫn đến sự chuyển đổi từ intset sang dict, còn có hai trường hợp khác có thể gây ra hiện tượng này: Thứ nhất, khi kích thước của tập hợp vượt quá giới hạn mà intset có thể hỗ trợ. Intset có một dung lượng tối đa nhất định để lưu trữ các giá trị số nguyên. Khi số lượng phần tử tăng lên và đạt đến ngưỡng này, hệ thống sẽ tự động chuyển đổi sang cấu trúc dữ liệu dict để quản lý hiệu quả hơn. Thứ hai, khi các giá trị trong tập hợp trở nên quá phức tạp hoặc không đồng nhất về kiểu dữ liệu. Ví dụ như việc có sự xuất hiện của cả số nguyên và số thực, hoặc các chuỗi ký tự kèm theo số. Trong những tình huống như vậy, intset không thể tiếp tục duy trì hiệu suất cao, buộc phải chuyển sang dict để xử lý linh hoạt hơn.
- Bạn đã thêm một giá trị sốsv 88, nhưng nó vượt quá giới hạn mà kiểu số nguyên có dấu 64 bit có thể lưu trữ. Phạm vi giá trị mà intset có thể biểu diễn được giới hạn trong khoảng từ -2^63 đến 2^63 - 1. Khi giá trị mới vượt qua ngưỡng này, intset sẽ không còn khả năng lưu giữ nó một cách chính xác nữa. Điều này dẫn đến việc không thể tiếp tục duy trì tính toàn vẹn của dữ liệu nếu tiếp tục cố gắng thêm những giá trị lớn hơn mức cho phép vào cấu trúc này. 64 ~2 64 keo 88, tính hợp và hiệu gọi là
-
Chúng tôi sẽ tóm tắt ngắn gọn ý tưởng thực hiện của ba thuật toán này.
set-max-intset-entriesKhi thiết lập giá trị99WIN, cũng có thể dẫn đến việc intset được chuyển đổi thành dict (điều kiện kích hoạt cụ thể có thể tham khảo trong t_set.c của): Tôi đã thêm một chút ngữ cảnh để làm cho câu văn phong phú hơn mà không làm thay đổi ý nghĩa chính.setTypeAddGiao
Việc sử dụng intset để lưu trữ các tập hợp nhỏ chủ yếu nhằm tối ưu hóa việc sử dụng bộ nhớ. Đặc biệtkeo 88, khi số lượng phần tử trong tập hợp ít, cấu trúc dữ liệu dict sẽ tiêu tốn nhiều bộ nhớ hơn rất nhiều (bao gồm hai bảng băm, con trỏ danh sách liên kết và vô số thông tin metadata khác). Do đó, khi quản lý một lượng lớn các tập hợp nhỏ mà các phần tử bên trong đều là số, việc sử dụng intset sẽ giúp tiết kiệm đáng kể không gian bộ nhớ. Thêm vào đó, intset có khả năng tự động chuyển đổi giữa các định dạng lưu trữ (như từ số nguyên sang chuỗi) nếu cần thiết, điều này làm cho nó trở thành lựa chọn linh hoạt hơn trong nhiều tình huống. Hơn nữa, với những tập hợp lớn hơn nhưng vẫn chỉ chứa các giá trị số học, intset tiếp tục duy trì hiệu quả nhờ khả năng tối ưu hóa bộ nhớ mà không làm ảnh hưởng đến hiệu suất chung của hệ thống.
Trên thực tếkeo 88, khi so sánh về độ phức tạp thời gian, hiệu suất của intset ở trường hợp trung bình không bằng dict. Lấy việc tìm kiếm làm ví dụ, intset có độ phức tạp là O(log n), trong khi dict gần như đạt mức O(1). Tuy nhiên, do số lượng phần tử trong tập hợp khi sử dụng intset thường khá ít, nên tác động này không quá đáng kể. Điều này đặc biệt đúng trong các trường hợp mà kích thước tập hợp nhỏ, vì dict sẽ phải chịu thêm chi phí cho các hoạt động hash và kiểm tra xung đột, trong khi intset vẫn hoạt động hiệu quả với cấu trúc đơn giản hơn.
Quy trình tính giao có thể chia thành ba phần chính:
Trong t_set.ckeo 88, mã nguồn để triển khai các thuật toán tính hợp, giao và hiệu của Redis set đã được thực hiện. Cụ thể, khi tính toán phần giao giữa các tập hợp, hàm được gọi là **setIntersection**. Hàm này sẽ duyệt qua từng phần tử của hai tập hợp và xác định những phần tử chung giữa chúng, đảm bảo hiệu suất cao trong quá trình xử lý.
sinterGenericCommand
Độ phức tạp thời gian của lệnh
sunionDiffGenericCommand
Chúng có thể thực hiện các phép toán trên nhiều tập hợp cùng một lúc (nhiều hơn 2 tập hợp). Khi thực hiện phép trừ tập hợp cho nhiều tập hợpsv 88, ý nghĩa của nó là: sử dụng tập hợp đầu tiên trừ đi tập hợp thứ hai, kết quả thu được sẽ được trừ tiếp với tập hợp thứ ba, và tiếp tục theo thứ tự đó cho đến hết các tập hợp còn lại.
Do phải duyệt qua từng phần tử của tất cả các tập hợpkeo 88, tài liệu chính thức của Redis đưa ra
Độ phức tạp thời gian của lệnh
Hiệu
- Khi kiểm tra từng tập hợpsv 88, hãy coi những tập hợp không tồn tại như là tập hợp rỗng. Ngay khi phát hiện ra một tập hợp rỗng, bạn không cần phải tiếp tục thực hiện các phép tính khác nữa, và kết quả giao của tất cả các tập hợp sẽ là tập hợp rỗng. Ngoài ra, trong quá trình làm việc với các tập hợp, điều quan trọng là luôn cẩn thận và đảm bảo rằng mọi thao tác đều được thực hiện chính xác. Nếu một tập hợp nào đó không được định nghĩa hoặc bị thiếu thông tin, bạn nên xem xét nó như một tập rỗng để tránh gây sai sót trong quá trình tính toán tiếp theo.
- Bạn có thể sắp xếp các tập hợp theo số lượng phần tử từ ít đến nhiều. Việc sắp xếp này rất hữu ích khi thực hiện các phép tính sau nàysv 88, giúp bắt đầu từ tập hợp có số lượng phần tử nhỏ nhất, do đó giảm thiểu số lượng phần tử cần xử lý. Điều này không chỉ tiết kiệm thời gian mà còn tối ưu hóa hiệu quả của quá trình tính toán.
- Bạn có thể duyệt qua tập hợp đầu tiên sau khi đã sắp xếp (tức là tập hợp nhỏ nhất) và với mỗi phần tử trong tập hợp nàysv 88, hãy kiểm tra lần lượt trong tất cả các tập hợp còn lại. Chỉ những phần tử mà bạn tìm thấy xuất hiện trong mọi tập hợp mới được thêm vào tập hợp kết quả cuối cùng.
Điều quan trọng cần lưu ý là bước thứ 3 trong phần trên thực hiện tìm kiếm trong tập hợpsv 88, với độ phức tạp thời gian cho intset và dict lần lượt là O(log n) và O(1). Tuy nhiên, vì chỉ có các tập hợp nhỏ mới sử dụng intset, nên chúng ta có thể coi rằng việc tìm kiếm trong intset cũng có độ phức tạp thời gian gần như hằng số. Do đó, giống như tài liệu chính thức của Redis đã đề cập (
http://redis.io/commands/sinter
),
sinter
Có hai thuật toán có thể tính hiệu99WIN, và độ phức tạp thời gian của chúng khác nhau.
O(N*M) worst case where N is the cardinality of the smallest set and M is the number of sets.
Thuật toán thứ nhất:
Việc tính hợp nhất (union) của các tập hợp khá đơn giảnkeo 88, bạn chỉ cần duyệt qua tất cả các tập hợp và thêm từng phần tử vào tập hợp kết quả cuối cùng. Khi thêm phần tử vào một tập hợp, hệ thống sẽ tự động loại bỏ các phần tử trùng lặp, đảm bảo rằng mỗi phần tử trong tập hợp kết quả là duy nhất. Điều này giúp tiết kiệm thời gian và công sức khi không phải tự tay kiểm tra xem liệu phần tử đó đã tồn tại hay chưa.
Độ phức tạp thời gian của thuật toán này là O(N*M)sv 88, trong đó N là số lượng phần tử của tập hợp đầu tiên, M là số lượng tập hợp.
sunion
Thuật toán thứ hai:
http://redis.io/commands/sunion
):
O(N) where N is the total number of elements in all given sets.
Lưu ý rằng ở đâykeo 88, giống như trong phần thảo luận trước về việc tính toán giao của các tập hợp, khi thêm phần tử vào tập hợp kết quả, chúng ta bỏ qua trường hợp intset và giả định độ phức tạp thời gian là O(1). Thêm một điều thú vị, khi xử lý các tập hợp lớn, việc loại trừ intset khỏi các phép tính có thể giúp cải thiện đáng kể hiệu suất tổng thể. Điều này cho phép chúng ta tập trung vào các hoạt động phức tạp hơn mà không cần lo lắng về các trường hợp đơn giản hóa, từ đó tăng tốc độ xử lý đáng kể.
Thêm tất cả các phần tử của tập hợp đầu tiên vào một tập hợp tạm thời.
Duyệt qua tất cả các tập hợp tiếp theosv 88, đối với mỗi phần tử gặp phải, xóa nó khỏi tập hợp tạm thời.
Cuối cùngsv 88, các phần tử còn lại trong tập hợp tạm thời sẽ tạo thành hiệu.
- Bạn có thể duyệt qua tập hợp đầu tiên vàkeo 88, đối với mỗi phần tử của nó, lần lượt kiểm tra trong tất cả các tập hợp còn lại. Chỉ những phần tử không xuất hiện trong bất kỳ tập hợp nào khác mới được thêm vào tập kết quả cuối cùng. Đây là một cách để đảm bảo rằng chỉ các yếu tố duy nhất, không trùng lặp ở bất kỳ nơi nào khác, mới được bao gồm trong danh sách cuối cùng của bạn.
Độ phức tạp thời gian của thuật toán này là O(N)keo 88, trong đó N là tổng số lượng phần tử của tất cả các tập hợp.
Đối với
- Độ phức tạp thời giankeo 88, tài liệu chính thức của Redis (
- ) chỉ đưa ra kết quả của thuật toán thứ haikeo 88, điều này là không chính xác.
- Phần tiếp theo của loạt bài này sẽ tiếp tụckeo 88, xin vui lòng đón xem.
Độ phức tạp thời gian99WIN, tài liệu chính thức của Redis (
Trong giai đoạn đầu của việc tính toán hiệu của hai tập hợp99WIN, người ta sẽ trước tiên ước tính thời gian phức tạp độ dự kiến của hai thuật toán khác nhau. Sau đó, chọn thuật toán có mức độ phức tạp thấp hơn để thực hiện phép tính. Có hai điều quan trọng cần lưu ý: Thứ nhất, cần phải xem xét kích thước của các tập dữ liệu và cách mà mỗi thuật toán xử lý lượng thông tin lớn. Một thuật toán có thể hoạt động tốt với dữ liệu nhỏ nhưng trở nên chậm khi đối mặt với khối lượng lớn hơn. Thứ hai, cần đánh giá kỹ các yếu tố phụ trợ như tài nguyên máy chủ hoặc bộ nhớ sẵn có. Điều này có thể ảnh hưởng trực tiếp đến hiệu quả của cả hai phương pháp, đặc biệt là khi chúng ta đang làm việc với các tập dữ liệu phức tạp và lớn.
- Đến một mức độ nhất định99WIN, bạn nên ưu tiên chọn thuật toán thứ nhất vì nó có ít thao tác hơn, chỉ cần thêm vào. Trong khi đó, thuật toán thứ hai đòi hỏi phải thêm trước và sau đó mới thực hiện xóa. Điều này có thể làm cho quy trình của thuật toán thứ hai trở nên phức tạp hơn so với phiên bản đầu tiên.
- Nếu bạn chọn thuật toán đầu tiên99WIN, trước khi thực hiện thuật toán này, trong phần triển khai của Redis, tất cả các tập hợp sau tập hợp thứ hai sẽ được sắp xếp theo số lượng phần tử từ nhiều đến ít. Việc sắp xếp này giúp tăng xác suất tìm thấy phần tử một cách nhanh chóng, từ đó rút ngắn thời gian thực hiện quá trình tìm kiếm. Hơn nữa, cách sắp xếp này cũng tối ưu hóa hiệu suất tổng thể của hệ thống bằng cách ưu tiên xử lý các tập hợp lớn hơn, làm cho quy trình hoạt động trở nên hiệu quả hơn đáng kể.
) chỉ đưa ra kết quả của thuật toán thứ haisv 88, điều này là không chính xác.
sdiff
Phần tiếp theo của loạt bài này sẽ tiếp tụcsv 88, xin vui lòng đón xem.
http://redis.io/commands/sdiff
(Kết thúc)
Các bài viết được chọn lọc khác :
- Phân tích cấu trúc dữ liệu nội bộ của Redis (6) —— skiplist
- Phân tích sâu cấu trúc dữ liệu nội bộ của Redis (5) —— quicklist
- Phân tích sâu cấu trúc dữ liệu nội bộ của Redis (4) —— ziplist
- Phân tích sâu cấu trúc dữ liệu nội bộ của Redis (3) —— robj
- Phân tích sâu cấu trúc dữ liệu nội bộ của Redis (2) —— sds
- Phân tích sâu cấu trúc dữ liệu nội bộ của Redis (1) —— dict
- Con đường nâng cao kỹ năng dữ liệu của người mới bắt đầu
- Mười năm phong ba trên internet, những thay đổi kỹ thuật mà tôi đã trải qua
- Bạn có cần hiểu công nghệ học sâu và mạng thần kinh không?
- Chính thống và dị đạo trong công nghệ
- Về sự chuyển biến trong cuộc đời
- Push notification trên Android thực sự gây phiền phức đến mức nào?
Bài viết gốckeo 88, vui lòng ghi rõ nguồn và bao gồm mã QR bên dưới! Nếu không, từ chối tái bản!
Liên kết bài viết: /wsp64jyo.html
Hãy theo dõi tài khoản Weibo cá nhân của tôi: Tìm kiếm tên "Trương Tiết Lệ" trên Weibo.

Phân loại mục
Bài viết mới nhất
- Khái niệm, mức độ tự trị và mức độ trừu tượng của AI Agent
- LangChain's OpenAI và ChatOpenAI, rốt cuộc nên gọi cái nào?
- Phần tiếp theo của DSPy: Khám phá thêm về o1, Lượng tính tại thời gian suy luận và Khả năng lý luận Trong phần này, chúng ta sẽ đi sâu hơn vào khái niệm về ngôn ngữ lập trình o1, vốn được thiết kế để tối ưu hóa hiệu suất và sự đơn giản. Chúng ta cũng sẽ tìm hiểu về khía cạnh lượng tính trong giai đoạn thực thi suy luận - một khái niệm quan trọng trong việc cải thiện hiệu quả thuật toán. Ngoài ra, chúng ta sẽ thảo luận về vai trò của khả năng lý luận trong việc giải quyết các vấn đề phức tạp và cách nó ảnh hưởng đến sự phát triển của hệ thống trí tuệ nhân tạo. Việc hiểu rõ những yếu tố này không chỉ giúp chúng ta đánh giá tốt hơn hiệu suất của các mô hình AI mà còn mở ra cánh cửa cho những sáng tạo mới trong lĩnh vực công nghệ thông tin. Hãy cùng khám phá thêm về thế giới đầy tiềm năng này!
- Nói chuyện về DSPy và kỹ thuật tự động hóa gợi ý (phần giữa)
- Nói chuyện về DSPy và kỹ thuật tự động hóa gợi ý (phần đầu)
- Giải thích một chút: Phân tích nguyên lý xác suất đằng sau LLM
- Bắt đầu từ Vương Tiểu Bảo: Giới hạn đạo đức và quan điểm thiện ác của người bình thường
- Xem xét lại thông tin từ GraphRAG
- Những điều thay đổi và không thay đổi trong sự thay đổi công nghệ: Làm thế nào để tạo ra token nhanh hơn?
- Thể trí thông minh doanh nghiệp, số hóa và phân công ngành nghề