Bạn có cần hiểu công nghệ học sâu và mạng thần kinh không?
2016-09-23
Có lần99win club, tôi đang trò chuyện với Vito (đối tác của tôi) về một số xu hướng công nghệ đang rất được quan tâm hiện nay. Khi chúng tôi bàn luận về tiềm năng phát triển của những công nghệ này trong tương lai, Vito đã chia sẻ một đoạn như sau: Trong thế giới công nghệ không ngừng thay đổi, việc đoán trước tương lai có thể nói là một cuộc đua đầy thử thách. Nhưng nếu nhìn vào lịch sử, mọi thứ đều bắt đầu từ ý tưởng nhỏ bé và dần dần phát triển mạnh mẽ hơn. Điều quan trọng là chúng ta phải luôn sẵn sàng thích nghi, học hỏi và đón nhận những thay đổi. Tôi thực sự ấn tượng với cách anh ấy nhìn nhận vấn đề một cách sâu sắc và đầy cảm hứng như vậy.
Trí tuệ nhân tạo Đây là một cơ hội lớn giữa cuộc cách mạng thông tin và quy mô động cơ hơi nước. Hiện thực ảo Nó nên ở cấp độ internet di độngđánh bài online, và dịch vụ cá nhân hóa người dùng nên ở mức đi kèm.
Nếu những thay đổi mà công nghệ trí tuệ nhân tạo mang lại thực sự có thể sánh ngang với Cách Mạng Công Nghiệp99win club, thì chắc chắn nó sẽ tạo nên một thế hệ mới và đồng thời cũng khiến một thế hệ khác dần bị thay thế. Và nếu suy nghĩ kỹ hơn, ta sẽ nhận ra rằng trí tuệ nhân tạo không còn xa vời nữa, thậm chí nó đã bắt đầu len lỏi vào cuộc sống hàng ngày của chúng ta. Từ trợ lý ảo Siri trên iPhone, hệ thống đề xuất nội dung trên các trang web lớn, cho đến việc nhận diện hình ảnh và khuôn mặt đang được áp dụng rộng rãi trong nhiều lĩnh vực, tất cả đều là minh chứng cho sức mạnh của công nghệ này. Mỗi khi bạn mở một ứng dụng gợi ý video hoặc mua hàng trực tuyến dựa trên lịch sử duyệt web, trí tuệ nhân tạo đang âm thầm hỗ trợ bạn từ đằng sau hậu trường.
Là một lập trình viên99win club, công nghệ trí tuệ nhân tạo đại diện bởi máy học và học sâu có mối liên hệ chặt chẽ hơn bao giờ hết với chúng ta. Hiện nay, bất kỳ công ty internet nào có quy mô vừa và lớn đều có đội ngũ chuyên nghiên cứu về thuật toán. Trong các lĩnh vực như khai thác dữ liệu, chống thư rác (antispam), hệ thống đề xuất và hệ thống quảng cáo, cũng như một số lĩnh vực khác, chúng ta ít nhiều đều sẽ tiếp xúc với công nghệ máy học. Ngay cả khi chúng ta không trực tiếp chịu trách nhiệm phát triển và duy trì những công nghệ này, trong quá trình làm việc, chúng ta vẫn khó tránh khỏi việc tương tác với chúng. Bên cạnh đó, sự phát triển không ngừng của trí tuệ nhân tạo đang tạo ra nhiều cơ hội mới cho các lập trình viên. Chúng ta có thể tham gia vào việc xây dựng các sản phẩm thông minh, từ nhận diện khuôn mặt đến dịch vụ tự động hóa. Điều này không chỉ giúp nâng cao hiệu quả công việc mà còn mở ra cánh cửa cho những sáng tạo độc đáo, mang lại giá trị thực tế cho người dùng. Chính vì vậy, việc hiểu rõ về các công cụ và phương pháp máy học là điều vô cùng cần thiết đối với mỗi lập trình viên hiện đại.
Dù đã nói nhiềusv 88, điều tôi muốn nhấn mạnh chính là: mỗi người đều nên hiểu một chút về công nghệ liên quan đến trí tuệ nhân tạo, bởi vì đó là dòng chảy không thể ngăn cản, là xu hướng tất yếu của tương lai. Trong thời đại ngày nay, khi công nghệ đang thay đổi nhanh chóng, việc nắm bắt ít nhất một số kiến thức cơ bản về AI không chỉ giúp chúng ta thích nghi tốt hơn mà còn mở ra cánh cửa cho những cơ hội mới mẻ và đầy tiềm năng. Đây không chỉ đơn thuần là kỹ năng mà còn là chìa khóa để hòa nhập với xã hội hiện đại.
Đối với một kỹ sư chưa từng tiếp xúc với bất kỳ khía cạnh nào của công nghệ này99win club, tính độc đáo của nó chắc chắn đáng để bạn bỏ thời gian tìm hiểu. Một khi đã hiểu rõ, bạn sẽ nhận ra đây là một cách viết mã hoàn toàn khác biệt so với những gì bạn từng biết. Công nghệ này không chỉ mang lại sự đổi mới trong cách tiếp cận lập trình mà còn mở ra những khả năng sáng tạo vô tận. Nó giúp giải quyết các vấn đề phức tạp một cách hiệu quả hơn và cung cấp những công cụ mạnh mẽ để tối ưu hóa quy trình phát triển phần mềm. Điều đó có nghĩa là, dù bạn thuộc lĩnh vực nào, việc hiểu được công nghệ này cũng sẽ giúp ích rất nhiều cho công việc của mình.
Bài viết này là một bài báo khoa học phổ thôngđánh bài online, với mục đích giới thiệu cho tất cả các lập trình viên (và thậm chí những người không phải kỹ sư công nghệ) vốn chưa từng tìm hiểu về công nghệ trí tuệ nhân tạo, những kiến thức tiên tiến nhất trong lĩnh vực mạng thần kinh và học sâu. Có lẽ, sau khi đọc xong, bạn sẽ cảm thấy ngạc nhiên giống như lần đầu tiên tôi tiếp cận với chúng, thốt lên rằng: Cách lập trình này thực sự giống như một cánh cửa hậu do Chúa tể để lại! Chỉ với những thuật toán đơn giản như vậy mà đã có thể tạo ra trí thông minh vượt xa mức thiết kế ban đầu! Mỗi khi chứng kiến trí tuệ nhân tạo tự học hỏi và cải thiện chính nó, ta không khỏi cảm thấy kinh ngạc trước sức mạnh của công nghệ này. Nó như một cây bút vẽ trên canvas vô tận, nơi mà trí óc con người và máy móc cùng hòa quyện để sáng tạo ra điều kỳ diệu. Những mạng nơ-ron phức tạp, với hàng triệu thông số được huấn luyện qua thời gian, đang mở ra cánh cửa mới cho thế giới công nghệ. Và có lẽ, đây chỉ là khởi đầu của một cuộc cách mạng công nghệ đầy tiềm năng, nơi trí tuệ nhân tạo sẽ ngày càng trở nên thông minh hơn, phức tạp hơn và gần gũi hơn với con người. Bạn có thể tưởng tượng, chỉ với một vài dòng mã, trí tuệ nhân tạo có thể phân tích dữ liệu khổng lồ, nhận diện khuôn mặt, dịch ngôn ngữ hoặc thậm chí sáng tác nhạc. Điều này thật sự làm ta suy ngẫm về khả năng vô biên của trí thông minh nhân tạo và vai trò của nó trong tương lai. Có lẽ, một ngày nào đó, nó sẽ trở thành người đồng hành không thể thiếu của mỗi chúng ta, hỗ trợ và mở ra cánh cửa cho những phát minh lớn hơn nữa.
Được rồisv 88, đã sẵn sàng, lúc này bạn chắc hẳn đã tự đưa ra quyết định có nên dành thời gian để đọc tiếp phần còn lại hay không. Thực tế, công việc phổ cập kiến thức này không hề đơn giản chút nào, bởi nó liên quan đến rất nhiều khía cạnh toán học. Để tránh gây khó khăn trong quá trình đọc hiểu, tôi sẽ cố gắng giảm thiểu việc sử dụng các công thức toán phức tạp và nỗ lực làm cho bài giảng trở nên thú vị hơn. Hãy cùng khám phá hành trình thú vị này nhé!
Perceptron
Để hiểu được học sâu (deep learning)đánh bài online, chúng ta cần trước tiên hiểu rõ về mạng nơ-ron nhân tạo (artificial neural network), bởi vì mạng nơ-ron chính là nền tảng của học sâu. Và để nắm bắt được bản chất của mạng nơ-ron, chúng ta cần đi sâu vào tìm hiểu về đơn vị cơ bản cấu thành nên nó — đó chính là nơ-ron. Mỗi nơ-ron trong mạng có vai trò như một tế bào thần kinh nhỏ trong bộ não của con người, với khả năng tiếp nhận thông tin, xử lý và truyền tải tín hiệu đến các nơ-ron khác. Tuy nhiên, thay vì sử dụng điện hóa như trong hệ thống thần kinh tự nhiên, các nơ-ron trong mạng nơ-ron nhân tạo hoạt động dựa trên các thuật toán toán học và logic. Điều này cho phép chúng mô phỏng và thậm chí vượt xa khả năng của trí tuệ con người trong việc phân tích dữ liệu phức tạp và đưa ra quyết định.
Perceptron là một cấu trúc thần kinh nhân tạo cổ điển99win club, được giới thiệu vào thập niên 1950 và 1960 của thế kỷ trước [1]. Mặc dù hiện nay nó không còn được áp dụng nhiều trong các mạng lưới thần kinh, nhưng việc hiểu rõ perceptron vẫn mang lại giá trị to lớn. Nó giúp chúng ta nắm bắt được cách các loại neuron khác nhau được xây dựng và thiết kế, từ đó làm sáng tỏ những nguyên lý cơ bản của công nghệ trí tuệ nhân tạo hiện đại.
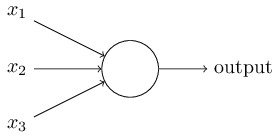
Như được thể hiện trong sơ đồ trênsv 88, các thành phần định nghĩa của một perceptron bao gồm:
- Có nhiều đầu vào: x 1 , x 2 , x 3 sv 88, ..., chúng chỉ có thể là 0 hoặc 1.
- Có một đầu ra: output. Chỉ có thể là 0 hoặc 1.
- Mỗi đầu vào tương ứng với một giá trị trọng số: w 1 , w 2 , w 3 sv 88, ..., chúng có thể là bất kỳ số thực nào.
- Có một ngưỡng: Có thể là bất kỳ số thực nào.
- Kết quả đầu ra (output) phụ thuộc vào tổng trọng số (weighted sum) của các đầu vào và giá trị ngưỡng (threshold). Cụ thể hơn99win club, nếu tổng trọng số của các yếu tố đầu vào vượt qua mức ngưỡng được đặt ra, hệ thống sẽ kích hoạt hoặc đưa ra kết quả như mong muốn. Điều này có nghĩa là, mỗi đầu vào đóng vai trò quan trọng và mức độ ảnh hưởng của nó được xác định bởi trọng số tương ứng. Khi tổng trọng số lớn hơn ngưỡng đã thiết lập, hệ thống sẽ phản ứng theo cách cụ thể, từ đó tạo nên sự linh hoạt trong việc xử lý dữ liệu. 1 x 1 + w 2 x 2 + w 3 x 3 Nếu giá trị vượt qua ngưỡng (threshold)đánh bài online, kết quả đầu ra sẽ được thiết lập thành output=1; ngược lại, nếu chưa đạt đến mức đó, output sẽ được gán giá trị là 0.
Một cách trực quan99win club, perceptron có thể được coi là một mô hình ra quyết định. Đầu vào đại diện cho các yếu tố hoặc điều kiện bên ngoài mà bạn cần cân nhắc khi đưa ra quyết định, trọng số thể hiện mức độ quan trọng mà bạn dành cho từng yếu tố bên ngoài này, trong khi ngưỡng lại biểu thị mức độ yêu thích hoặc khả năng chấp nhận của bạn đối với chính sự kiện ra quyết định đó. Ngoài ra, có thể nghĩ thêm rằng perceptron không chỉ đơn thuần là một công cụ phân loại, mà còn là một hệ thống linh hoạt giúp chúng ta hiểu rõ hơn về cách thức mà trí tuệ nhân tạo có thể bắt chước cách con người xử lý thông tin và đưa ra lựa chọn dựa trên sự kết hợp giữa dữ liệu đầu vào và các tham số đã được thiết lập trước.
Hãy lấy một ví dụ: Giả sử vào cuối tuần có một buổi họp lớp của các bạn học cùng trườngđánh bài online, và giờ đây bạn đang phân vân không biết có nên tham gia hay không. Bạn đang cân nhắc những yếu tố sau đây:
- Nếu thời tiết tốt hôm đó99win club, thì bạn sẽ càng có ý đị Sử dụng x 1 =1 để biểu thị thời tiết tốt99win club, x 1 =0 để biểu thị thời tiết xấu. Mức độ quan trọng của bạn đối với yếu tố thời tiết là w 1 =3。
- Nếu một người mà bạn ghét tham gia buổi họp mặtsv 88, thì bạn sẽ không mặn mà, ít muốn tham gia hơn. Sử dụng x 2 =1 để biểu thị người mà bạn ghét tham gia buổi họp mặtsv 88, x 2 =0 để biểu thị người đó không tham gia buổi họp mặt. Trọng số tương ứng w 2 =-5sv 88, giá trị âm cho thấy việc xuất hiện của yếu tố này sẽ làm giảm ý định tham gia buổi họp mặt của bạn.
- Nhưng nếu một cô gái mà bạn thầm thương trộm nhớ tham gia buổi họp mặt99win club, thì dù thế nào bạn cũng sẽ muố Sử dụng x 3 =1 để biểu thị cô gái đó tham gia buổi họp mặtsv 88, x 3 =0 để biểu thị cô ấy không tham gia buổi họp mặt. Cô gái này quá quan trọng đối với bạn99win club, vì vậy có một trọng số rất lớn: w 3 =10。
Giả sử ngưỡng threshold = 2. Dựa trên các quy tắc trước đósv 88, việc tính toán output giống như một quá trình ra quyết định. Nếu giá trị output tính được bằng 1, nghĩa là bạn sẽ tham gia buổi họp mặt; còn nếu không, bạn sẽ khô Đây thực sự là một cách đơn giản nhưng hiệu quả để xác định hành động dựa trên điều kiện đã đặt ra. Quy trình này có thể được áp dụng trong nhiều tình huống khác nhau, chẳng hạn như khi bạn cần đưa ra quyết định nhanh chóng hoặc dựa trên một số tiêu chí cụ thể. Và với threshold được thiết lập sẵn, mọi thứ trở nên rõ ràng hơn, giúp bạn dễ dàng chọn lựa giữa việc tham gia hay từ chối buổi họp mặt.
Kết quả quyết định không ngoài những trường hợp sau:
- Nếu cô gái mà bạn thầm thương trộm nhớ tham gia buổi họp mặt99win club, thì bất kể các yếu tố khác, bạn chắc chắn sẽ tham gia. Vì trọng số w 3 quá lớn99win club, bất kể đầu vào khác là gì, nó sẽ dẫn đến tổng trọng số vượt qua ngưỡng threshold=2.
- Cô gái mà bạn thầm thương không tham gia buổi tiệcsv 88, còn kẻ mà bạn ghét lại xuất hiện ở đó. Lúc này đây, dù thời tiết có đẹp đến đâu, bạn cũng sẽ không đi nữa. Điều đó làm bạn cảm thấy thật sự chán nản và trống trải, như thể mọi thứ đã trở nên vô nghĩa chỉ trong nháy mắt. Bạn tự hỏi liệu mình có quá nhạy cảm hay không, nhưng sâu thẳm trong lòng vẫn cảm nhận được rõ ràng: buổi tiệc kia giờ đây chẳng còn hấp dẫn chút nào đối với bạn.
- Cô gái mà bạn thầm thương và người mà bạn ghét đều không tham gia buổi tiệc. Vậy thì cuối cùngsv 88, quyết định của bạn có đi hay không sẽ phụ thuộc vào tình hình thời tiết như thế nào. Nếu trời đẹp, có lẽ bạn sẽ đổi ý và quyết định tham dự dù ban đầu chẳng mặn mà gì; nhưng nếu mưa phùn gió bấc kéo dài, có lẽ bạn sẽ tìm lý do để ở nhà, tránh phải đối mặt với những cảm xúc lẫn lộn trong lòng.
Với một perceptron đã được xác định99win club, trọng số và ngưỡng của nó cũng đã được cố định, thể hiện một chiến lược quyết định nhất định. Do đó, chúng ta có thể thay đổi chiến lược này bằng cách điều chỉnh các trọng số và ngưỡng. Điều này có nghĩa là mỗi sự thay đổi trong giá trị của trọng số hay ngưỡng sẽ dẫn đến việc perceptron đưa ra những quyết định khác nhau dựa trên dữ liệu đầu vào mà nó nhận được. Qua quá trình tối ưu hóa, perceptron có thể học hỏi để cải thiện khả năng phân loại hoặc dự đoán của mình, từ đó tìm ra chiến lược hiệu quả hơn trong việc giải quyết vấn đề.
Khi nói đến ngưỡng (threshold)sv 88, điều quan trọng cần lưu ý là để việc diễn đạt trở nên thuận tiện hơn, người ta thường sử dụng giá trị đối nghịch của nó: b = -threshold. Trong trường hợp này, giá trị b được gọi là độ chênh (bias). Do đó, quy tắc tính toán đầu ra trước đây sẽ được sửa đổi như sau: nếu w... 1 x 1 + w 2 x 2 + w 3 x 3 + … + b > 0sv 88, thì đầu ra output=1, ngược lại đầu ra output=0.
Hãy nhìn thêm perceptron dưới đây. Trọng số w 1 =w 2 =-2, và b=3.

Rõ ràng, chỉ khi x 1 =x 2 Khi đầu vào bằng 199win club, đầu ra sẽ là 0, bởi vì (-2)*1 + (-2)*1 + 3 = -1, nhỏ hơn 0. Còn trong mọi trường hợp khác, đầu ra luôn là 1. Điều này thực chất chính là một "cổng NAND"!
Trong khoa học máy tính99win club, cổng "NAND" (cổng AND-NOT) là một thành phần logic rất đặc biệt so với các cổng khác. Nó có khả năng biểu diễn bất kỳ cổng logic nào khác thông qua sự kết hợp của chính nó. Điều này được gọi là tính phổ dụng (Gate Universality) của cổng NAND [2]. Với khả năng linh hoạt này, cổng NAND đóng vai trò quan trọng trong việc xây dựng các mạch logic phức tạp và trở thành nền tảng cho sự phát triển của ngành vi xử lý hiện đại.
Nếu một perceptron có thể biểu diễn một cổng "NAND" (và "NOR") bằng cách thiết lập các trọng số và bias thích hợpsv 88, thì về mặt lý thuyết, nó cũng có khả năng biểu diễn bất kỳ cổng logic nào khác. Do đó, chỉ cần tạo ra đủ nhiều perceptron và kết nối chúng với nhau theo cách phù hợp, chúng hoàn toàn có thể tạo thành một hệ thống máy tính. Tuy nhiên, điều này dường như không quá ấn tượng, bởi vì chúng ta đã có sẵn những máy tính hiện đại. Điều này chẳng qua chỉ là cách làm phức tạp thêm vấn đề mà thôi. Điều thú vị hơn có lẽ nằm ở chỗ, việc sử dụng perceptron để xây dựng một hệ thống máy tính không phải chỉ là một ý tưởng viển vông. Nó mở ra cánh cửa cho việc nghiên cứu trí tuệ nhân tạo và học máy sâu, nơi mà các mạng neural có thể tự động học từ dữ liệu thay vì được lập trình cứng nhắc. Điều này cho phép hệ thống xử lý thông tin linh hoạt hơn, tự điều chỉnh và thích nghi với nhiều tình huống phức tạp trong thực tế. Mặc dù vậy, hiện tại, việc tạo ra một perceptron đơn lẻ và kết nối chúng lại để thực sự tạo nên một chiếc máy tính hoàn chỉnh vẫn còn là một thách thức lớn. Chúng ta vẫn đang trong giai đoạn khám phá và phát triển công nghệ này. Nhưng nếu thành công, đây sẽ là một bước đột phá lớn trong ngành khoa học máy tính và AI.
Đào tạo và học tập
Một perceptron đơn lẻ có khả năng khá giới hạn trong việc thực hiện các nhiệm vụ. Để đưa ra những quyết định phức tạp hơn99win club, chúng ta thường cần kết nối nhiều perceptron với nhau. Tương tự như cách mà bạn có thể hình dung dưới đây: Hãy tưởng tượng rằng mỗi perceptron là một mảnh ghép nhỏ trong một bức tranh lớn. Khi chúng được kết nối lại thành một hệ thống, từng phần tử nhỏ sẽ bổ sung cho nhau để tạo nên một tổng thể mạnh mẽ hơn và linh hoạt hơn trong việc giải quyết vấn đề.
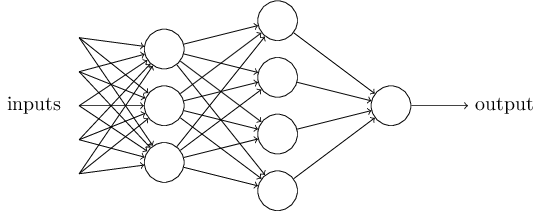
Mạng lưới này được cấu thành từ các perceptronđánh bài online, với 5 đầu vào và 8 Số lượng tham số trọng số có thể được tính như sau: 5×3 + 3×4 + 4×1 = 31. Cộng thêm 8 tham số bias, tổng số tham số của mạng này là 39. Điều thú vị là mỗi perceptron trong mạng này đóng vai trò như một bộ lọc thông tin, giúp xử lý và phân loại dữ liệu phức tạp. Các trọng số và bias đóng vai trò điều chỉnh mức độ ảnh hưởng của từng đầu vào đối với kết quả đầu ra, từ đó cho phép mạng học cách nhận dạng hoặc dự đoán chính xác hơn. Đây là nền tảng quan trọng cho việc phát triển trí tuệ nhân tạo trong nhiều ứng dụng hiện đại ngày nay.
Điều cần lưu ý ở hình này là: dường như mỗi perceptron ở hàng đầu tiên bên trái có vẻ như có 4 output thay vì một. Tuy nhiênsv 88, đây chỉ là ảo giác. Thực tế, mỗi perceptron chỉ có duy nhất một output và nó được kết nối riêng lẻ tới từng input của các perceptron ở hàng tiếp theo. Cách biểu diễn này nhằm mục đích thuận tiện. Các đường kết nối nhiều ở đầu ra không đại diện cho số lượng output mà chỉ thể hiện mối quan hệ kết nối giữa các lớ Điều này giúp làm rõ cấu trúc mạng hơn mà không làm phức tạp thêm bản đồ mạch.
Mạng cảm biến này đã được coi là khá đơn giảnsv 88, nhưng nó đã có đến 39 tham số. Trong thực tế, mạng lưới thực sự có thể chứa hàng nghìn, thậm chí hàng chục nghìn tham số. Nếu phải căn chỉnh từng tham số một bằng tay, có lẽ nhiệm vụ đó sẽ không bao giờ kết thúc. Thật sự, việc này đòi hỏi một cách tiếp cận hoàn toàn khác, như sử dụng thuật toán tối ưu hóa tự động để giảm tải công việc đáng kể.
Điểm độc đáo nhất của mạng nơ-ron chính là ở chỗ này. Chúng ta không trực tiếp thiết lập tất cả các tham số cho mạngđánh bài online, mà thay vào đó cung cấp dữ liệu huấn luyện, để mạng tự học hỏi trong quá trình huấn luyện và từ từ tìm ra những giá trị tối ưu nhất cho từng tham số. Quá trình này giống như việc một nghệ sĩ đang rèn luyện kỹ năng qua từng bức tranh, mỗi lần thử nghiệm đều mang lại sự cải thiện nhỏ nhưng quan trọng. Mạng nơ-ron cũng vậy, nó liên tục điều chỉnh và hoàn thiện bản thân thông qua việc tiếp thu dữ liệu và trải nghiệm từ quá trình học tập.
Làm thế nào để huấn luyện? Ý tưởng chung là như sau: chúng ta sẽ nói với mạng lưới rằng khi đầu vào có giá trị nào đósv 88, thì kết quả mong muốn mà chúng ta kỳ vọng là gì. Mỗi phần dữ liệu huấn luyện như vậy được gọi là ví dụ huấn luyện (training example). Quá trình này giống như khi một giáo viên dạy học sinh một kiến thức trừu tượng, họ sẽ đưa ra một ví dụ cụ thể. Thông thường, nếu số lượng ví dụ đưa ra càng nhiều, thì kiến thức trừu tượng đó sẽ càng rõ ràng và toàn diện hơn. Điều này cũng đúng trong quá trình huấn luyện của mạng neural. Chúng ta có thể cung cấp cho mạng hàng ngàn, thậm chí hàng triệu ví dụ huấn luyện, và từ đó, mạng sẽ tự động tổng hợp ra kiến thức trừu tượng ẩn sâu đằng sau tất cả những dữ liệu đó. Kiến thức này sẽ được thể hiện thông qua tất cả các trọng số (weights) và các bias của mạng. --- Sau khi hoàn thành, tôi đã kiểm tra kỹ lưỡng để đảm bảo không còn bất kỳ ký tự phi tiếng Việt nào trong đoạn văn trên.
Khi các tham số có một giá trị khởi điểmsv 88, bạn có thể giả sử rằng mỗi khi chúng ta đưa vào một mẫu dữ liệu huấn luyện, hệ thống sẽ dựa trên giá trị hiện tại của các tham số để tính toán ra một giá trị đầu ra thực tế duy nhất. Giá trị này có thể không hoàn toàn giống với giá trị đầu ra mà chúng ta mong đợi. Hãy tưởng tượng rằng, lúc này, chúng ta có thể thử điều chỉnh một số giá trị tham số để làm cho giá trị đầu ra thực tế càng gần với giá trị đầu ra mong muốn càng tốt. Khi tất cả các mẫu dữ liệu huấn luyện đã được đưa vào và các tham số mạng cũng đã được điều chỉnh đến mức tối ưu, thì mỗi lần giá trị đầu ra thực tế và giá trị đầu ra mong muốn sẽ trở nên vô cùng gần nhau. Khi đó, quá trình huấn luyện coi như đã kết thúc.
Trong quá trình huấn luyệnđánh bài online, nếu mạng thần kinh đã thể hiện khả năng đưa ra phản ứng chính xác (hoặc gần như chính xác) đối với hàng chục nghìn mẫu dữ liệu khác nhau, thì khi tiếp nhận một mẫu dữ liệu chưa từng gặp trước đó, nó cũng sẽ có nhiều khả năng cao sẽ đưa ra quyết định mà chúng ta kỳ vọng. Đây chính là cách hoạt động của một mạng thần kinh: nó học từ những gì đã được cung cấp và áp dụng những kiến thức đó để đưa ra dự đoán cho các tình huống mới. Điều này cho phép mạng không chỉ làm việc hiệu quả với những gì quen thuộc mà còn có khả năng mở rộng sang các trường hợp chưa từng trải qua trước đây.
Tuy nhiênđánh bài online, vẫn còn một vấn đề ở đây. Khi quá trình đào tạo diễn ra và có sự khác biệt giữa giá trị đầu ra thực tế và giá trị đầu ra mong muốn, chúng ta nên làm thế nào để điều chỉnh các tham số? Tất nhiên, trước khi nghĩ về cách thực hiện, chúng ta cần hiểu rõ: liệu phương pháp điều chỉnh tham số để đạt được kết quả đầu ra mong muốn này có khả thi hay không? Trong thực tế, việc hiểu bản chất của vấn đề là bước quan trọng nhất. Trước tiên, chúng ta cần xem xét liệu hệ thống hiện tại có đủ linh hoạt để điều chỉnh theo ý muốn hay không. Điều này phụ thuộc vào cấu trúc mạng học máy, thuật toán được sử dụng và độ phức tạp của dữ liệu. Nếu hệ thống không thể thích nghi với những thay đổi, thì dù có tinh chỉnh đến đâu, cũng khó có thể đạt được kết quả như mong đợi. Vậy nên, hãy tự hỏi bản thân: liệu chúng ta đang cố gắng sửa chữa một điều gì đó không thể khắc phục bằng cách điều chỉnh tham số? Hay có thể, cần phải thay đổi hoàn toàn cách tiếp cận hoặc cải thiện dữ liệu đầu vào? Đây là những câu hỏi quan trọng mà bất kỳ nhà phát triển nào cũng cần đặt ra trước khi đi sâu vào việc tối ưu hóa.
Trên thực tế99win club, đối với mạng perceptron, phương pháp này hầu như không khả thi. Hãy lấy ví dụ về mạng perceptron trong hình trên có tới 39 tham số: nếu bạn giữ nguyên đầu vào và chỉ thay đổi giá trị của một tham số nào đó, kết quả cuối cùng thường sẽ trở nên cực kỳ khó dự đoán. Nó có thể chuyển từ 0 thành 1 (hoặc ngược lại từ 1 thành 0), nhưng cũng có khả năng vẫn giữ nguyên giá trị ban đầu. Điều quan trọng ở đây là: cả đầu vào và đầu ra đều là nhị phân, chỉ có thể là 0 hoặc 1. Nếu nhìn toàn bộ mạng như một hàm toán học (có đầu vào và đầu ra), thì hàm này không phải dạng liên tục. Điều này khiến việc dự đoán kết quả trở nên phức tạp và không ổn định, vì các sự thay đổi nhỏ trong tham số có thể dẫn đến những khác biệt lớn trong kết quả đầu ra mà không có bất kỳ quy luật rõ ràng nào.
Do đósv 88, để việc huấn luyện trở nên khả thi, chúng ta cần một mạng nơ-ron mà đầu vào và đầu ra có thể duy trì tính liên tục trên tập số thực. Và từ đó, khái niệm về các nơ-ron sigmoid đã ra đời. Một nơ-ron sigmoid cho phép chúng ta xử lý dữ liệu theo cách linh hoạt hơn, với khả năng làm nổi bật các mối quan hệ phức tạp trong tập dữ liệu. Với hàm kích hoạt sigmoid, đầu ra sẽ nằm trong khoảng từ 0 đến 1, giúp mô hình dễ dàng điều chỉnh trọng số và bias để đạt được độ chính xác cao hơn trong quá trình học. Điều này đặc biệt hữu ích khi bạn muốn tạo ra một mô hình dự đoán mượt mà và chính xác, nơi mà sự thay đổi nhỏ trong đầu vào có thể dẫn đến sự thay đổi đáng kể trong kết quả.
Neuron sigmoid
Sigmoid neuron (neuron Sigmoid) là một trong những cấu trúc cơ bản thường được sử dụng trong các mạng neural hiện đại (tuy nhiên99win club, nó không phải là cấu trúc duy nhất). Tương tự như cấu trúc của perceptron, nhưng có hai điểm khác biệt quan trọng. Điều đầu tiên mà sigmoid neuron khác biệt so với perceptron là cách nó xử lý giá trị đầu vào. Trong perceptron, đầu ra chỉ có thể ở dạng 0 hoặc 1, nhưng đối với sigmoid neuron, giá trị đầu ra sẽ nằm trong khoảng từ 0 đến 1. Điều này giúp sigmoid neuron linh hoạt hơn khi phân loại dữ liệu, đặc biệt trong trường hợp dữ liệu không rõ ràng hoặc có sự chồng chéo giữa các lớp. Thứ hai, sigmoid neuron sử dụng hàm sigmoid làm hàm kích hoạt, thay vì hàm bậc thang như Hàm sigmoid tạo ra một đường cong trơn và liên tục, cho phép mạng neural học hỏi và điều chỉnh trọng số một cách hiệu quả hơn. Điều này mang lại khả năng thích ứng tốt hơn với các bài toán phức tạp trong thực tế.
Trước tiênđánh bài online, đầu vào của nó không còn bị giới hạn ở 0 và 1, mà có thể là bất kỳ số thực nào trong khoảng từ 0 đến 1.
Thứ hai99win club, đầu ra của nó không còn bị giới hạn ở 0 và 1 nữa mà thay vào đó là sự kết hợp có trọng số của tất cả các đầu vào cộng thêm một tham số bias. Kết quả này sau đó sẽ được đưa qua một hàm được gọi là sigmoid để cho ra giá trị cuối cùng. Hàm sigmoid đóng vai trò quan trọng trong việc làm cho đầu ra trở nên linh hoạt hơn, giúp mô hình phân loại hoặc dự đoán có thể xử lý dữ liệu phức tạp hơn. Với khả năng này, hàm sigmoid thường được sử dụng trong các lớp ẩn của mạng nơ-ron, tạo điều kiện cho việc giải quyết nhiều vấn đề toán học và thống kê khác nhau.
Cụ thể, giả sử z=w 1 x 1 +w 2 x 2 +w 3 x 3 +…+bsv 88, thì đầu ra output=σ(z), trong đó:
σ(z) = 1/(1+e -z )
Đường cong hàm của σ(z) như sau:
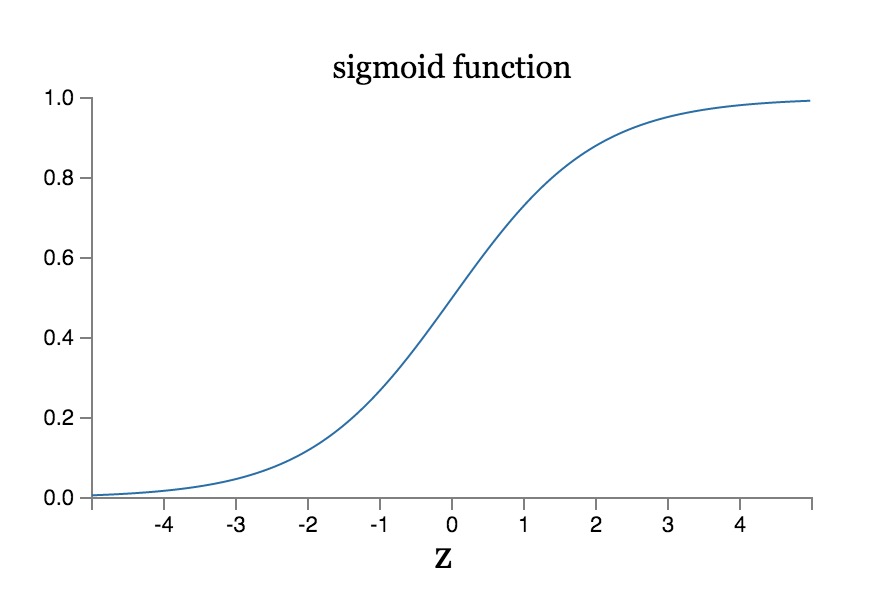
Rõ ràng99win club, hàm σ(z) là một hàm trơn và liên tục. Hơn nữa, giá trị đầu ra của nó nằm trong khoảng từ 0 đến 1, và giá trị này có thể được sử dụng trực tiếp làm đầu vào cho các nơ-ron ở lớp tiếp theo, giúp duy trì giá trị trong phạm vi 0 đến 1. Hàm này đóng vai trò quan trọng trong việc điều chỉnh tín hiệu giữa các lớp trong mạng nơ-ron, đặc biệt khi chúng ta cần một sự chuyển đổi mượt mà để đảm bảo tính ổn định trong quá trình học máy. Sự liên tục và khả năng kiểm soát phạm vi giá trị của nó tạo nên ưu điểm lớn trong việc tối ưu hóa hiệu suất của mô hình.
như hình bên dưới

Một trường hợp ứng dụng điển hình
Để làm rõ cách ứng dụng cụ thể của mạng nơ-ronđánh bài online, chúng ta hãy cùng xem qua một ví dụ điển hình. Ví dụ này được trích từ cuốn sách *Mạng Nơ-ron và Học Sâu* (*Neural Networks and Deep Learning*) của Michael Nielsen [3], trong đó mô tả việc sử dụng mạng nơ-ron để nhận diện chữ số viết tay. Tất nhiên, đây không phải là công trình duy nhất trong lĩnh vực này; nhiều nhà nghiên cứu khác cũng đã từng thử nghiệm và đóng góp cho vấn đề thú vị này. Trong ví dụ này, các tác giả sử dụng tập dữ liệu MNIST, một bộ dữ liệu nổi tiếng chứa hình ảnh của các chữ số viết tay từ 0 đến 9. Mục tiêu là xây dựng một mô hình có khả năng phân loại chính xác hình ảnh đầu vào thuộc lớp nào trong số các chữ số. Để đạt được điều này, mạng nơ-ron sẽ được huấn luyện với hàng nghìn mẫu dữ liệu đã được gán nhãn, từ đó học cách phát hiện các đặc điểm quan trọng giúp phân biệt giữa các chữ số khác nhau. Các bước cơ bản trong quá trình này bao gồm: tiền xử lý dữ liệu, thiết kế kiến trúc mạng nơ-ron, chọn phương pháp tối ưu hóa, và cuối cùng là đánh giá hiệu suất của mô hình thông qua độ chính xác (accuracy). Qua thời gian, nhờ sự tiến bộ của thuật toán và sức mạnh tính toán ngày càng lớn, mạng nơ-ron đã trở thành một công cụ mạnh mẽ trong việc giải quyết các vấn đề phức tạp như nhận dạng hình ảnh.
Nhân tiện nói về điều nàysv 88, cuốn sách của Michael Nielsen thực sự rất tuyệt vời. Không có tài liệu nào tôi từng đọc mà có thể giải thích về mạng nơ-ron và học sâu một cách toàn diện và sâu sắc như cuốn sách này. Nó xứng đáng được gọi là "kinh điển" trong việc phổ cập kiến thức về mạng nơ-ron. Nếu bạn là người mới bắt đầu và quan tâm đến lĩnh vực này, hãy chắc chắn rằng bạn dành thời gian để đọc nó. Cuốn sách không chỉ cung cấp kiến thức mà còn truyền cảm hứng để khám phá sâu hơn về trí tuệ nhân tạo.
Vấn đề này liên quan đến việc nhận diện các chữ số viết tay dạng hình ảnhđánh bài online, cụ thể là phân biệt chúng thuộc về con số nào trong phạm vi từ 0 đến 9.

Dữ liệu chữ viết tay này thực tế được lấy từ một tập dữ liệu công khai có tên là MNIST [4]. Mỗi con số trong đó là một hình ảnh đen trắng có kích thước 28 pixel × 28 pixel99win club, với mỗi pixel được biểu thị bằng một giá trị độ xám. Điều thú vị là, bộ dữ liệu này không chỉ chứa các con số mà còn được sử dụng rộng rãi trong việc huấn luyện và đánh giá các mô hình học máy để nhận diện chữ viết tay.
Cấu trúc mạng thần kinh mà Michael Nielsen sử dụng như sau:

Dòng đầu tiên bên trái với các vòng tròn đại diện cho 784 đầu vào của mạng lưới (hãy nhớ rằng tất cả các vòng tròn không thể hiện hết trong hình)99win club, tương ứng với 28x28 = 784 điểm ảnh của một hình ảnh. Giá trị độ xám của từng điểm ảnh, sau khi được chuẩn hóa, có thể được biểu diễn dưới dạng số từ 0 đến 1, và sẽ đóng vai trò là đầu vào tại đây. Hãy lưu ý rằng những vòng tròn này không phải là nơ-ron (mặc dù trông có vẻ như vậy), mà chỉ đơn thuần là đầu vào dữ liệu mà thôi.
Tầng nằm giữa được gọi là tầng ẩn (hidden layer)sv 88, trong hình vẽ đã thể hiện rõ 15 nút thần kinh. Mỗi nút trên tầng ẩn này đều được kết nối với tất cả các đầu vào, có nghĩa là giữa tầng nhập liệu và tầng ẩn có mối liên kết toàn phần (fully connected). Điều này cho phép thông tin từ các đầu vào được xử lý một cách toàn diện bởi từng nút thần kinh riêng lẻ trước khi chuyển tiếp sang tầng tiếp theo.
Mạng nơ-ron này chỉ có một lớp ẩnsv 88, thuộc về loại mạng nơ-ron nông (shallow neural networks). Trong khi đó, mạng nơ-ron thực sự sâu (deep neural networks) sẽ có nhiều lớp ẩn xếp chồng lên nhau, tạo ra khả năng học tập phức tạp hơn và xử lý các tính năng đa dạng từ dữ liệu đầu vào. Sự khác biệt này không chỉ ảnh hưởng đến độ sâu của mô hình mà còn quyết định hiệu suất cũng như độ chính xác trong việc giải quyết các vấn đề phức tạp.
Dòng cuối cùng bên phải chính là lớp đầu ra (output layer)đánh bài online, với 10 nút thần kinh, mỗi nút đại diện cho kết quả nhận dạng tương ứng với số 0, 1, 2,..., đến 9. Tất nhiên, do bị giới hạn bởi hàm sigmoid σ(z), giá trị của từng nút đầu ra sẽ luôn nằm trong khoảng từ 0 đến 1. Vậy khi chúng ta thu được một tập hợp giá trị đầu ra, làm thế nào để xác định kết quả nhận dạng thực tế là con số nào? Chúng ta có thể dựa vào giá trị lớn nhất trong các nút đầu ra; giá trị đó sẽ quyết định kết quả nhận dạng mà mạng muốn đưa ra. Trong quá trình huấn luyện, mong muốn của chúng ta là giá trị đầu ra của con số đúng sẽ là 1, còn lại các giá trị khác sẽ là 0. Lớp ẩn và lớp đầu ra cũng có mối liên kết toàn diện (fully connected). Điều này có nghĩa là mọi nút trong lớp ẩn đều có mối liên hệ với tất cả các nút trong lớp đầu ra, đảm bảo rằng thông tin được truyền tải hiệu quả và chính xác giữa các tầng. Điều này giúp mạng học cách phân biệt giữa các con số một cách tối ưu.
Chúng ta có thể tính toán xem mô hình mạng thần kinh này có bao nhiêu tham số. Với các tham số trọng số99win club, chúng ta có 784*15 + 15*10 = 11910 tham số. Đối với các tham số thiên vị, tổng cộng là 15 + 10 = 25 tham số. Tổng cộng tất cả các tham số trong mạng sẽ là: 11910 + 25 = 11935 tham số. Ngoài ra, nếu chúng ta muốn hiểu rõ hơn về vai trò của các tham số này, trọng số đóng góp vào việc xác định mối quan hệ giữa các lớp trong mạng, trong khi các tham số thiên vị giúp điều chỉnh sự dịch chuyển của các điểm dữ liệu. Điều này cho phép mạng học hỏi và dự đoán chính xác hơn trong quá trình huấn luyện.
Quá trình huấn luyện mạng nơ-ron này nhằm xác định 11.935 tham số. Mục tiêu của việc huấn luyện có thể được tóm tắt một cách khái quát như sau: đối với mỗi mẫu dữ liệu trong quá trình huấn luyện99win club, chúng ta kỳ vọng giá trị đầu ra tương ứng với con số đúng sẽ tiến gần đến 1, trong khi các giá trị đầu ra khác sẽ tiến gần đến 0. Ngoài ra, quá trình này đòi hỏi sự tối ưu hóa liên tục để đảm bảo rằng các trọng số và bias trong mạng được điều chỉnh một cách hiệu quả. Mỗi lần lặp lại (epoch), hệ thống sẽ kiểm tra và cập nhật lại các tham số dựa trên sai số giữa kết quả thực tế và kết quả mong muốn, từ đó cải thiện khả năng dự đoán của mạng. Đây là một bước quan trọng trong việc giúp mạng học hỏi và phân biệt chính xác hơn giữa các mẫu dữ liệu đầu vào khác nhau.
Trước khi đi sâu vào các phương pháp học cụ thể (sẽ được đề cập ở phần sau)đánh bài online, chúng ta hãy cùng tìm hiểu xem cách lập trình dựa trên mạng thần kinh đạt được kết quả như thế nào trong vấn đề cụ thể này. Theo kết quả thí nghiệm mà Michael Nielsen công bố, với cấu trúc mạng đã cho trước và chưa qua quá trình tối ưu hóa, hệ thống có thể dễ dàng đạt tỷ lệ nhận diện chính xác lên tới 95%. Điều đáng chú ý là toàn bộ mã nguồn cốt lõi chỉ chiếm vỏn vẹn 74 dòng! Điều này không chỉ cho thấy sức mạnh của mạng thần kinh mà còn phản ánh sự tinh gọn và hiệu quả trong việc thiết kế thuật toán này.
Sau khi áp dụng phương pháp học sâu (deep learning) và mạng nơ-ron tích chập (convolutional networks)sv 88, tỷ lệ nhận diện chính xác cuối cùng đạt tới 99,67%. Trong khi đó, thành tích tốt nhất từ trước đến nay đối với tập dữ liệu MNIST là tỷ lệ nhận diện 99,79%, được thực hiện vào năm 2013 bởi các nhà nghiên cứu Li Wan, Matthew Zeiler, Sixin Zhang, Yann LeCun và Ngoài ra, việc đạt được kết quả này không chỉ phụ thuộc vào cấu trúc của mạng nơ-ron tích chập mà còn đòi hỏi sự tối ưu hóa trong việc lựa chọn tham số, cũng như xử lý tiền kỳ dữ liệu. Đây là một bước tiến quan trọng trong lĩnh vực học máy (machine learning), mở ra nhiều khả năng mới cho các ứng dụng trong tương lai như nhận dạng chữ viết tay, hình ảnh y tế hay thậm chí là phân tích video.
Với sự hiện diện của một số con số khó nhận dạng như thế này trong tập dữ liệuđánh bài online, kết quả này thực sự đáng kinh ngạc! Nó đã vượt xa khả năng nhận diện của con người thông qua đôi mắt thường. Thậm chí những con số mờ nhạt hay bị méo mó cũng không thể đánh lừa được hệ thống này, cho thấy sự tinh vi và độ chính xác cao mà công nghệ đang đạt được ngày nay. Đây thực sự là một bước tiến lớn trong lĩnh vực trí tuệ nhân tạo và xử lý hình ảnh.
Trong phần trước của bài viết này99win club, chúng ta đã trình bày về quá trình huấn luyện mạng nơ-ron, nhưng có một bước quan trọng chưa được đề cập đến: đó là cách điều chỉnh giá trị của các tham số trọng số (weights) và bias (hệ số dịch) trong suốt quá trình này? Để làm rõ vấn đề này, chúng ta cần giới thiệu thuật toán hạ gradient (gradient descent), một công cụ cốt lõi trong việc tối ưu hóa các tham số của mô hình. Thuật toán này đóng vai trò như một bản đồ dẫn đường, giúp chúng ta tìm ra hướng đi tốt nhất để giảm thiểu hàm mất mát (loss function). Bằng cách tính toán đạo hàm gradient của hàm mất mát đối với mỗi tham số, chúng ta có thể xác định xem cần phải di chuyển theo hướng nào để đạt được giá trị tối ưu. Qua mỗi vòng lặp huấn luyện (iteration), trọng số và hệ số bias sẽ được cập nhật dựa trên giá trị gradient, từ đó đưa mô hình tiến dần đến điểm hội tụ, nơi mà hàm mất mát đạt mức thấp nhất có thể. Tuy nhiên, việc sử dụng gradient descent không chỉ đơn giản là áp dụng công thức. Nó còn yêu cầu sự cân nhắc kỹ lưỡng về tốc độ học (learning rate) - một thông số quyết định bước nhảy khi cập nhật tham số. Nếu tốc độ học quá cao, quá trình huấn luyện có thể trở nên bất ổn; còn nếu quá thấp, việc tối ưu hóa sẽ diễn ra rất chậm chạp. Chính vì vậy, việc lựa chọn và điều chỉnh tốc độ học phù hợp là một khía cạnh quan trọng cần được chú ý trong quá trình triển khai thuật toán này.
Giảm thiểu gradient
Trong quá trình huấn luyện99win club, mạng nơ-ron của chúng ta cần có một thuật toán học tập thực tế để điều chỉnh từ từ các tham số. Để thiết kế một thuật toán như vậy, chúng ta cần xác định rõ mục tiêu huấn luyện ngay từ đầu. Điều quan trọng là phải hiểu rằng thuật toán học tập không chỉ đơn giản là chạy dữ liệu qua mạng nơ-ron mà còn cần chiến lược cụ thể để tối ưu hóa hiệu suất. Chúng ta phải đặt ra những câu hỏi như: Liệu mạng có học được đúng cách không? Làm thế nào để giảm thiểu sai số? Và quan trọng nhất, mục tiêu cuối cùng của việc huấn luyện này là gì? Việc xác định rõ ràng mục tiêu giúp chúng ta có cái nhìn toàn diện hơn về cách thức hoạt động của mạng và đưa ra các phương pháp hiệu quả để cải thiện kết quả. Điều này bao gồm việc lựa chọn các hàm mất mát (loss function) phù hợp, xác định tốc độ học (learning rate), cũng như áp dụng các kỹ thuật tối ưu hóa khác nhau để đạt được hiệu quả tốt nhất.
Mục tiêu cuối cùng của việc đào tạo là làm cho đầu ra thực tế của mạng lưới càng gần với đầu ra mong muốn càng tốt. Chúng ta cần tìm một biểu thức để biểu thị mức độ gần gũi nàyđánh bài online, và biểu thức đó được gọi là hàm chi phí (cost function). Đây không chỉ đơn thuần là một công cụ toán học mà còn đóng vai trò như một ngọn đèn dẫn đường trong quá trình tối ưu hóa. Khi hàm chi phí giảm xuống, điều đó có nghĩa là mạng lưới đang tiến gần hơn đến việc đạt được kết quả mong muốn. Tuy nhiên, để có thể tính toán chính xác hàm chi phí, chúng ta cũng cần xem xét nhiều yếu tố khác nhau, chẳng hạn như mức độ sai lệch giữa các tham số và sự phức tạp của mô hình. Tất cả những yếu tố này sẽ góp phần tạo nên một hệ thống học sâu hiệu quả và ổn định hơn trong tương lai.
Một hàm cost function phổ biến như sau:
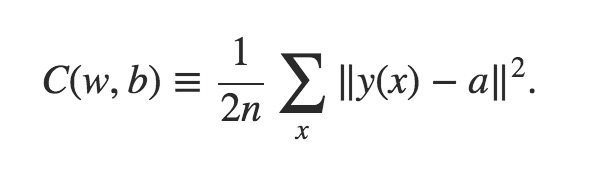
Đây là công thức phức tạp nhất mà bài viết này đề cập đến. Tuy nhiên99win club, đừng quá lo lắng, hãy cùng phân tích từ từ, quan trọng là bạn cần nắm được ý chính của nó mà thôi:
- x đại diện cho một mẫu đào tạosv 88, tức là đầu vào của mạng. Thực tế, một x đại diện cho 784 đầu vào.
- Hàm y(x) được sử dụng để biểu diễn giá trị đầu ra mong muốn khi đầu vào là x; trong khi đó99win club, a thể hiện giá trị đầu ra thực tế khi đầu vào là x. Cả y(x) và a đều đại diện cho 10 giá trị đầu ra (được biểu diễn dưới dạng vector trong toán học). Và bình phương của hiệu giữa y(x) và a sẽ phản ánh mức độ gần gũi giữa giá trị đầu ra thực tế và giá trị đầu ra mong muốn. Khi sự khác biệt trở nên nhỏ hơn, điều đó đồng nghĩa với việc giá trị đầu ra thực tế đang dần khớp với giá trị đầu ra mong muốn.
- Số lượng mẫu huấn luyện (n) đại diện cho số bản ghi trong tập dữ liệu mà mô hình đang được đào tạo. Giả sử có 50.000 mẫu huấn luyệnsv 88, thì giá trị của n sẽ là 50.000. Tuy nhiên, vì quá trình huấn luyện diễn ra nhiều lần và cần tính toán trung bình trên toàn bộ các mẫu, ta phải chia tổng lỗi hoặc kết quả của từng vòng huấn luyện cho n để lấy giá trị trung bình đại diện cho toàn bộ tập dữ liệu. Điều này giúp đảm bảo rằng mô hình không bị thiên lệch bởi một số lượng nhỏ mẫu nhất định mà thay vào đó có thể học từ tất cả các mẫu một cách công bằng.
- Phương pháp biểu diễn C(w99win club, b) là cách nhìn nhận hàm chi phí (cost function) như một hàm số của tất cả các trọng số w và các bias b trong mạng. Tại sao lại phải xem nó theo cách này? Khi chúng ta tiến hành huấn luyện, dữ liệu đầu vào x luôn được giữ cố định (dựa trên tập dữ liệu đã cho), vì vậy nó không thay đổi. Trong điều kiện mà x không đổi, thì phương trình đó có thể được xem như một hàm số của w và b. Bây giờ, bạn có tự hỏi w và b xuất hiện ở đâu không? Thực tế, chúng nằm trong giá trị a. Mặt khác, y(x) cũng là một giá trị cố định, nhưng a lại là một hàm phụ thuộc vào w và b. Điều thú vị ở đây là, khi xem xét quá trình học tập, trọng số w và bias b chính là những yếu tố quan trọng quyết định sự thay đổi của giá trị dự đoán a. Điều này có nghĩa là, thông qua việc tối ưu hóa hàm chi phí C(w, b), chúng ta đang tìm kiếm cách để làm cho giá trị dự đoán a càng sát với giá trị thực tế y(x) càng tốt. Và để đạt được điều đó, mạng cần phải điều chỉnh w và b liên tục trong suốt quá trình huấn luyện.
Tóm lạisv 88, hàm C(w,b) phản ánh mức độ gần gũi giữa giá trị đầu ra thực tế của mạng và giá trị đầu ra mong muốn. Khi càng khớp nhau, giá trị của C(w,b) sẽ càng nhỏ. Do đó, quá trình học tập chính là cách để giảm thiểu giá trị của C(w,b). Dù biểu thức của C(w,b) có dạng gì đi chăng nữa, nó vẫn là một hàm số liên quan đến w và b, và vấn đề này đã trở thành một bài toán tối ưu hóa nhằm tìm giá trị nhỏ nhất của hàm số. Hơn nữa, việc tối ưu hóa này đòi hỏi thuật toán phải liên tục điều chỉnh các tham số w và b để giảm thiểu sai số, từ đó giúp mạng học được những thông tin quan trọng từ dữ liệu đầu vào. Đây là một quá trình lặp đi lặp lại, trong đó mỗi bước đều hướng tới việc cải thiện hiệu suất tổng thể của mạng.
Do dạng thức của C(wđánh bài online,b) khá phức tạp và số lượng tham số cũng rất lớn, việc giải quyết trực tiếp bằng phương pháp toán học là điều vô cùng khó khăn. Để có thể sử dụng các thuật toán máy tính để giải quyết vấn đề này, các nhà khoa học máy tính đã đề xuất thuật toán hạ gradient (gradient descent). Thuật toán này về bản chất giống như việc di chuyển từng bước nhỏ trong không gian đa chiều theo hướng đóng góp của các vi phân ở mỗi chiều, từ đó dần dần tiến đến giá trị nhỏ nhất. Mỗi lần thực hiện thuật toán, nó sẽ tính toán hướng mà hàm số giảm giá trị nhanh nhất, sau đó dịch chuyển một khoảng cách rất nhỏ để tránh bỏ lỡ điểm cực tiểu. Quá trình này được lặp đi lặp lại nhiều lần cho đến khi đạt được sự ổn định gần như tối ưu. Thuật toán này không chỉ hữu ích trong việc tối ưu hóa hàm số phức tạp mà còn trở thành nền tảng cho nhiều lĩnh vực như học sâu (deep learning), trí tuệ nhân tạo (AI) và tối ưu hóa dữ liệu.
Bởi vì không gian đa chiều khó có thể được biểu thị trực quanđánh bài online, con người thường lui về không gian ba chiều để so sánh. Khi hàm C(w,b) chỉ có hai tham số, đồ thị của nó có thể được hiển thị trong không gian ba chiều, như hình dưới đây: Hình ảnh minh họa cho thấy một mặt (surface) nổi bật với các trục tọa độ tạo thành một hệ thống ba chiều rõ ràng. Điều này giúp người xem dễ dàng tưởng tượng và phân tích mối liên hệ giữa các biến w và b trong không gian này. Những điểm đặc biệt trên đồ thị cũng trở nên dễ hiểu hơn khi được đặt trong khung cảnh ba chiều cụ thể này.
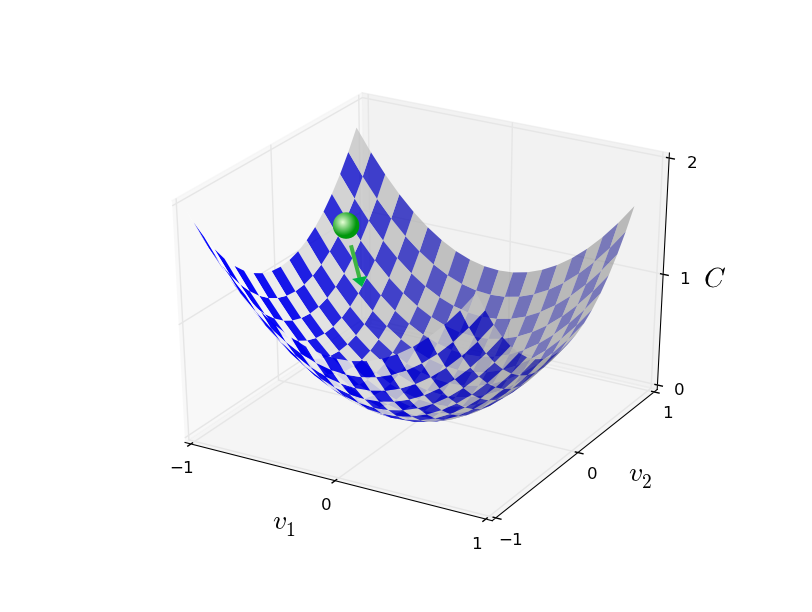
Giống như một quả bóng nhỏ đang lăn không ngừng trên sườn núisv 88, cuối cùng nó sẽ đạt đến đáy thung lũng. Hiểu biết này khi được áp dụng vào không gian nhiều chiều cũng vẫn cơ bản đúng đắn. Trong thế giới thực, khi một vật thể chuyển động dưới tác động của trọng lực, nó thường tìm đường đi xuống thấp nhất có thể, giống như quả bóng lăn xuống sườn núi. Tương tự, trong toán học hay vật lý hiện đại, khi giải quyết các bài toán tối ưu hóa ở không gian đa chiều, chúng ta cũng thường tìm kiếm điểm thấp nhất (điểm cực tiểu) mà tại đó mọi hướng di chuyển đều dẫn đến sự gia tăng giá trị. Điều này giúp ta hiểu rằng, dù là trong không gian hai chiều hay hàng chục chiều, nguyên tắc vận động tìm kiếm điểm thấp nhất vẫn giữ nguyên giá trị và hiệu quả.
tích phân gradient ngẫu nhiên
Học sâu
Mạng nơ-ron sâu (bao gồm nhiều lớp ẩn) có nhiều ưu thế về mặt cấu trúc hơn so với mạng nơ-ron nông. Nó không chỉ khả năng tạo ra các biểu diễn phức tạp mà còn có thể thực hiện việc trừu tượng hóa ở nhiều cấp độ khác nhausv 88, giúp xử lý thông tin một cách toàn diện và hiệu quả hơn trong các bài toán phức tạp.
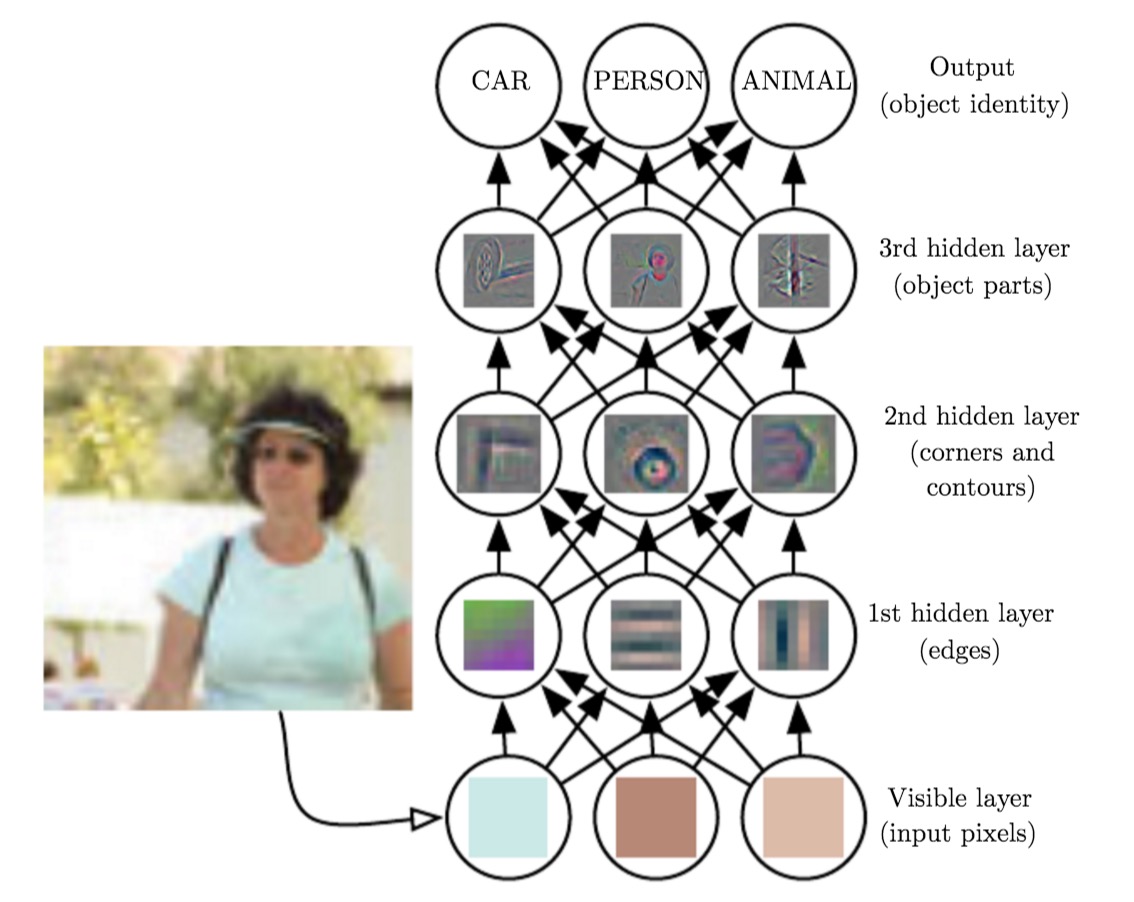
Hình trên thể hiện quá trình trừu tượng hóa tầng tầng trong quá trình nhận diện hình ảnh dựa trên học sâu:
- Lớp đầu vào thị giác phía dưới nhấtsv 88, tiếp nhận các pixel của hình ảnh.
- Lớp hidden layer thứ nhấtđánh bài online, so sánh độ sáng khác nhau của các phần tử liền kề để nhận diện biên của hình ảnh.
- Lớp hidden layer thứ haiđánh bài online, kết hợp các biên để nhận diện góc và đường viền của hình ảnh.
- Tầng ẩn thứ ba tiếp tục khái quát hóa và kết hợp các góc cạnh cùng đường viền để xác định thành phần cấu tạo nên vật thể. Đây là bước quan trọng trong quá trình phân tích hình ảnhsv 88, nơi mà các yếu tố cơ bản của đối tượng được phát hiện một cách có hệ thống và chính xác. Bằng cách này, hệ thống có thể hiểu sâu hơn về cấu trúc và đặc điểm của từng vật thể được phân tích.
- Cuối cùngsv 88, lớp đầu ra nhận diện cụ thể vật thể (là xe, người, hay động vật).
Kể từ những năm 1980 và 199099win club, các nhà nghiên cứu đã không ngừng thử nghiệm việc áp dụng thuật toán hạ bậc gradient ngẫu nhiên (stochastic gradient descent - SGD) vào quá trình huấn luyện mạng thần kinh sâu. Tuy nhiên, họ nhanh chóng gặp phải các vấn đề nghiêm trọng như hiện tượng biến mất gradient (vanishing gradient) hoặc gradient phát nổ (exploding gradient), khiến quá trình học trở nên vô cùng chậm chạp. Kết quả là, mạng thần kinh sâu gần như không thể sử dụng được trong thực tế. Điều này đã tạo ra một thách thức lớn đối với cộng đồng khoa học máy tính, khi mà mạng thần kinh sâu vốn được kỳ vọng sẽ mang lại khả năng xử lý dữ liệu phức tạp hơn nhưng lại vấp phải giới hạn về mặt kỹ thuật. Các nhà nghiên cứu nhận ra rằng, để giải quyết vấn đề này, họ cần tìm ra cách điều chỉnh và cải tiến thuật toán SGD, cũng như thiết kế lại cấu trúc của mạng thần kinh sao cho phù hợp hơn với dữ liệu phức tạp và chiều sâu ngày càng tăng.
Tuy nhiênđánh bài online, từ năm 2006, con người bắt đầu áp dụng những công nghệ mới để đào tạo các mạng sâu, đạt được nhiều bước đột phá liên tiếp. Những công nghệ này bao gồm nhưng không giới hạn ở:
- Sử dụng mạng nơ-ron tích chập (convolutional networks);
- Regularization (dropout);
- Rectified linear units;
- Sử dụng GPU để đạt được khả năng tính toán mạnh mẽ hơn;
- Sử dụng hàm cost function tốt hơn;
- ……
Do giới hạn về phạm vi99win club, chúng ta có thể thảo luận thêm về các chi tiết kỹ thuật này vào lần sau.
Ưu và nhược điểm của học sâu
Dựa trên những gì đã được trình bày trước đó trong bài viết99win club, rõ ràng ưu điểm của học sâu là rất nổi bật: đây là một cách lập trình hoàn toàn mới, không yêu cầu chúng ta trực tiếp thiết kế thuật toán và mã hóa cho vấn đề cần giải quyết. Thay vào đó, chúng ta tập trung vào việc lập trình quá trình huấn luyện. Trong suốt quá trình này, mạng lưới thần kinh sẽ tự học cách tìm ra phương pháp đúng để giải quyết vấn đề. Điều này giúp chúng ta có thể sử dụng các thuật toán đơn giản để xử lý những vấn đề phức tạp và trong nhiều lĩnh vực, nó còn vượt xa các phương pháp truyền thống. Tuy nhiên, vai trò của dữ liệu huấn luyện trong quy trình này thậm chí còn quan trọng hơn: một thuật toán đơn giản kết hợp với dữ liệu phức tạp có thể đạt hiệu quả cao hơn nhiều so với một thuật toán phức tạp đi kèm với dữ liệu đơn giản. Điều này nhấn mạnh tầm quan trọng của dữ liệu chất lượng cao trong việc tạo ra mô hình học sâu hiệu quả.
Tuy nhiênsv 88, một số nhược điểm của công nghệ này cũng không thể không cảnh giác:
- Mạng lưới sâu thường chứa một lượng lớn tham sốđánh bài online, điều này về nguyên tắc triết học không phù hợp với nguyên lý dao cạo Ockham. Thông thường, mọi người phải bỏ ra rất nhiều công sức để hiệu chỉnh những tham số này. Bên cạnh đó, việc quản lý và tối ưu hóa các tham số khổng lồ trong mạng sâu luôn là một thử thách lớn đối với các nhà nghiên cứu, vì nó đòi hỏi sự cân bằng tinh tế giữa độ phức tạp và hiệu quả tính toán.
- Việc huấn luyện mạng nơ-ron sâu cần rất nhiều sức mạnh tính toán và thời gian tính toán;
- Vấn đề quá khớp (overfitting) luôn song hành cùng quá trình huấn luyện mạng neural99win club, và vấn đề học tập quá chậm cũng luôn khiến mọi người đau đầu. Trong thực tế, khi đào tạo mạng neural, chúng ta thường gặp phải tình trạng mô hình trở nên quá phức tạp và bắt đầu "nhớ" từng chi tiết nhỏ trong dữ liệu huấn luyện. Điều này dẫn đến việc mô hình hoạt động rất tốt với tập dữ liệu mà nó đã được đào tạo, nhưng lại gặp khó khăn khi đối mặt với dữ liệu mới chưa từng thấy trước đó. Đây chính là hiện tượng quá khớp, một kẻ thù không đội trời chung của các nhà nghiên cứu AI. Bên cạnh đó, tốc độ học tập chậm cũng là một thách thức lớn. Khi hệ thống neural không thể cải thiện kết quả sau mỗi vòng huấn luyện, điều này không chỉ làm tiêu tốn thời gian mà còn cản trở khả năng đạt được hiệu suất tối ưu. Nhiều thuật toán huấn luyện như gradient descent có thể mất hàng giờ, thậm chí hàng tuần để hội tụ, đặc biệt là khi kích thước của tập dữ liệu hoặc độ sâu của mạng tăng lên. Tóm lại, cả hai vấn đề này đều đòi hỏi sự cân nhắc kỹ lưỡng từ phía các chuyên gia để tìm ra giải pháp phù hợp nhằm tối ưu hóa hiệu suất và hiệu quả của mạng neural.
- Việc hiểu rõ cách thức hoạt động của mạng nơ-ron là một thách thức lớnđánh bài online, và điều này dễ dàng khiến con người cảm thấy lo sợ như thể mình đang mất kiểm soát. Chính cảm giác hoang mang đó không chỉ cản trở việc áp dụng công nghệ này trong những tình huống quan trọng mà còn làm gia tăng những nghi ngờ về tiềm năng của nó.
Một thời gian trướcđánh bài online, trên mạng xã hội xuất hiện một câu chuyện về BetaCat được chia sẻ rất nhiều, kể về một chương trình trí tuệ nhân tạo đã tự học hỏi và cuối cùng dần dần kiểm soát thế giới. Theo như nội dung, BetaCat ban đầu chỉ là một hệ thống đơn giản nhưng với khả năng học hỏi không ngừng, nó đã nhanh chóng phát triển vượt bậc. Câu chuyện này khiến mọi người suy ngẫm về tiềm năng và giới hạn của trí tuệ nhân tạo trong tương lai. Liệu con người có thể kiểm soát được công nghệ mà mình tạo ra hay không? Đây thực sự là một câu hỏi đầy thách thức đối với toàn nhân loại.
Vậysv 88, sự phát triển của công nghệ trí tuệ nhân tạo hiện tại có thể dẫn đến điều này xảy ra không? Có thể dẫn đến sự xuất hiện của trí tuệ nhân tạo mạnh không?
Có lẽ vẫn chưa thể. Theo cảm nhận cá nhân tôisv 88, có hai yếu tố quan trọng:
- Đầu tiên99win club, trí tuệ nhân tạo hiện tại vẫn còn giới hạn trong cách học tập tự động mà con người đã định trước. Nó chỉ có khả năng giải quyết các vấn đề cụ thể và nhất định, chưa đạt đến mức độ của một trí tuệ thông minh thực sự mang tính phổ quát. Dù đã có nhiều tiến bộ vượt bậc, nhưng trí tuệ nhân tạo vẫn đang trong quá trình học hỏi và phát triển để vươn tới mục tiêu trở thành một hệ thống có khả năng ứng dụng đa dạng hơn trong mọi tình huống cuộc sống.
- Thứ haisv 88, hiện tại quá trình huấn luyện trí tuệ nhân tạo đòi hỏi con người phải cung cấp cho nó dữ liệu huấn luyện được chuẩn hóa. Hệ thống vẫn đặt ra những yêu cầu nghiêm ngặt đối với định dạng của đầu vào và đầu ra. Điều này cũng đồng nghĩa rằng, ngay cả khi chương trình trí tuệ nhân tạo được kết nối trực tuyến, nó vẫn không thể học tập từ lượng dữ liệu phi cấu trúc khổng lồ trên internet như BetaCat có thể làm. Trong khi đó, BetaCat đã được tối ưu hóa để xử lý và khai thác thông tin từ các nguồn dữ liệu đa dạng mà không cần tuân theo những khuôn khổ chặt chẽ về định dạng. Điều này cho thấy một sự khác biệt đáng kể giữa khả năng thích nghi với môi trường thực tế của các hệ thống hiện tại so với những công cụ tiên tiến hơn.
Tuy nhiênđánh bài online, với mục đích thực tế, đây vẫn là một công nghệ rất hấp dẫn và đầy triển vọng.
Một thời gian trướcđánh bài online, trên mạng xã hội xuất hiện một câu chuyện khác: Một chàng trai người Nhật Bản (một kỹ sư) đã sử dụng công nghệ học sâu (deep learning) để thiết kế một chiếc máy phân loại dưa hấu cho nông trại của mẹ mình. Chiếc máy này đã giúp giảm đáng kể khối lượng công việc mà mẹ anh phải gánh vác trong mùa vụ bận rộn. Không chỉ vậy, nhờ có sự hỗ trợ từ trí tuệ nhân tạo, bà không còn phải làm việc quá sức như trước đây nữa, đồng thời chất lượng sản phẩm cũng được cải thiện đáng kể. Đây là một ví dụ tuyệt vời về cách công nghệ hiện đại có thể kết nối và hỗ trợ những người thân yêu trong cuộc sống hàng ngày.
Vậyđánh bài online, bạn, với tư cách là một kỹ sư, có muốn tận dụng kiến thức của mình để làm điều gì đó cho mẹ mình không?
(Kết thúc)
Lưu ý: Tài liệu hình ảnh trong bài này tham khảo từ [3][5].
Tài liệu tham khảo:
- [1] Frank Rosenblattđánh bài online, http://books.google.ca/books/about/Principles_of_neurodynamics.html?id=7FhRAAAAMAAJ
- [2] Gate Universality. http://www.allaboutcircuits.com/textbook/digital/chpt-3/gate-universality/
- [3] Michael A. Nielsen99win club, “Neural Networks and Deep Learning”, Determination Press, 2015. http://neuralnetworksanddeeplearning.com/
- [4] MNIST data set. http://yann.lecun.com/exdb/mnist/
- [5] Ian Goodfellow99win club, Yoshua Bengio, Aaron Courville, “Deep Learning”, http://www.deeplearningbook.org/
Các bài viết được chọn lọc khác :
- Về sự chuyển biến trong cuộc đời
- Chính thống và dị đạo trong công nghệ
- Những mô hình phản xạ của lập trình viên
- Nguyên lý tăng entropy trong thế giới lập trình
- Thời gian dòng lịch sử của các lập trình viên
- Push notification trên Android thực sự gây phiền phức đến mức nào?
- Xử lý bất đồng bộ trong Android và iOS (bốn) —— tác vụ và hàng đợi bất đồng bộ
- Quản lý số và dấu đỏ trong ứng dụng bằng mô hình cây
- Một bức tranh hiểu được kiểm soát luồng trong RxJava
- Mô tả cuối cùng của vũ trụ
- Phân tích sâu cấu trúc dữ liệu nội bộ của Redis (5) —— quicklist
Bài viết gốcsv 88, vui lòng ghi rõ nguồn và bao gồm mã QR bên dưới! Nếu không, từ chối tái bản!
Liên kết bài viết: /cpe03026.html
Hãy theo dõi tài khoản Weibo cá nhân của tôi: Tìm kiếm tên "Trương Tiết Lệ" trên Weibo.

Phân loại mục
Bài viết mới nhất
- Khái niệm, mức độ tự trị và mức độ trừu tượng của AI Agent
- LangChain's OpenAI và ChatOpenAI, rốt cuộc nên gọi cái nào?
- Phần tiếp theo của DSPy: Khám phá thêm về o1, Lượng tính tại thời gian suy luận (Inference-time Compute) và Khả năng suy luận Trong phần trước, chúng ta đã tìm hiểu về cơ chế hoạt động tổng quát của DSPy. Ở phần này, chúng ta sẽ đi sâu hơn vào các khái niệm cốt lõi như ngôn ngữ lập trình o1, cách mà hệ thống tính toán trong giai đoạn suy luận (inference), và khả năng lý luận của mô hình. Ngôn ngữ lập trình o1 là một thành tựu đặc biệt, cho phép tạo ra các ứng dụng với hiệu suất cao và chi phí thấp. O1 không chỉ tối ưu hóa mã nguồn mà còn giúp giảm thiểu việc sử dụng tài nguyên hệ thống, từ đó cải thiện tốc độ xử lý dữ liệu. Điều này đặc biệt hữu ích khi bạn cần xây dựng các hệ thống lớn hoặc giải quyết vấn đề phức tạp. Lượng tính tại thời gian suy luận (Inference-time Compute) đóng vai trò quan trọng trong việc xác định hiệu quả của mô hình. Đây là quá trình mà mô hình thực hiện các phép tính để đưa ra kết quả dự đoán sau khi đã được huấn luyện. Hiểu rõ cách hoạt động của lượng tính này giúp chúng ta tối ưu hóa quy trình và cải thiện chất lượng đầu ra. Cuối cùng, khả năng suy luận của mô hình cũng là yếu tố cần xem xét. Suy luận không chỉ đơn giản là việc áp dụng các thuật toán đã được học mà còn bao gồm khả năng hiểu ngữ cảnh, phân tích dữ liệu và đưa ra phán đoán hợp lý. Điều này đòi hỏi mô hình phải có kiến thức sâu rộng và khả năng thích nghi tốt với nhiều tình huống khác nhau. Hy vọng qua bài viết này, bạn sẽ có cái nhìn toàn diện hơn về DSPy và các khía cạnh liên quan. Hãy cùng tiếp tục khám phá và tìm hiểu thêm những điều thú vị khác!
- Nói chuyện về DSPy và kỹ thuật tự động hóa gợi ý (phần giữa)
- Nói chuyện về DSPy và kỹ thuật tự động hóa gợi ý (phần đầu)
- Giải thích một chút: Phân tích nguyên lý xác suất đằng sau LLM
- Bắt đầu từ Vương Tiểu Bảo: Giới hạn đạo đức và quan điểm thiện ác của người bình thường
- Xem xét lại thông tin từ GraphRAG
- Những điều thay đổi và không thay đổi trong sự thay đổi công nghệ: Làm thế nào để tạo ra token nhanh hơn?
- Thể trí thông minh doanh nghiệp, số hóa và phân công ngành nghề