Những điều thay đổi và không thay đổi trong sự thay đổi công nghệ: Làm thế nào để tạo ra token nhanh hơn?
2024-06-02
Tương lai sẽ đến khi nào phụ thuộc vào tốc độ chúng ta có thể tạo ra token nhanh như thế nào.
Với sự phát triển không ngừng của trí tuệ nhân tạo thế hệ mới (GenAI)tai ban ca, chúng ta đang bước vào một kỷ nguyên công nghệ hoàn toàn mới. Tuy nhiên, do quy mô tham số khổng lồ của các mô hình ngôn ngữ lớn (LLM), hiệu suất suy luận (inference) trong các hệ thống AI hiện đại đã trở thành một vấn đề kỹ thuật đặc biệt quan trọng. Việc cải thiện hiệu suất suy luận của LLM không chỉ giúp tạo ra các token nhanh hơn mà còn đồng nghĩa với việc giảm thiểu chi phí vận hành. Hơn nữa, việc tối ưu hóa hiệu suất này cũng mở ra nhiều cơ hội để phát triển các ứng dụng sáng tạo và mạnh mẽ hơn. Khi các mô hình AI có thể xử lý thông tin nhanh chóng và chính xác, chúng ta có thể kỳ vọng một tương lai nơi công nghệ hỗ trợ con người ở mọi khía cạnh cuộc sống. Điều này không chỉ mang lại lợi ích về mặt kinh tế mà còn thúc đẩy khả năng sáng tạo và đổi mới trong nhiều lĩnh vực khác nhau.
Trong bài viết nàybxh ngoai hang anh, chúng ta sẽ thảo luận về các vấn đề hiệu suất của dịch vụ suy luận LLM từ một số khía cạnh sau đây:
- Trước tiêntỷ lệ kèo bóng đá trực tiếp, từ góc nhìn bên ngoài hệ thống, chúng ta nên Làm thế nào để đo lường hệ thống? Chúng ta nên chú ý đến những chỉ số hiệu suất nào? So với các hệ thống truyền thốngtỷ lệ kèo bóng đá trực tiếp, chúng có điểm gì giống và khác biệt? Câu trả lời cho vấn đề này sẽ định hình mục tiêu thiết kế của hệ thống và cũng xác định hướng đi tiếp theo mà chúng ta cần suy ngẫm. Hơn nữa, việc hiểu rõ những khác biệt này không chỉ giúp tối ưu hóa hiệu quả làm việc mà còn mở ra cơ hội cải tiến toàn diện cho hệ thống.
- Từ góc độ hiệu năngtai ban ca, làm thế nào để hiểu bản chất của hệ thống? Chúng ta hướng tới những điều cốt lõi — những nguyên tắc không thay đổi theo sự tiến hóa của công nghệ. Điều này đòi hỏi chúng ta phải nhìn xuyên qua bề mặt đa dạng và biến đổi không ngừng của hệ thống. Hãy tưởng tượng rằng một hệ thống không khác gì một tòa nhà kiến trúc phức tạp. Khi bên ngoài có thể thay đổi hình dáng với các thiết kế mới mẻ, thì nền móng và cấu trúc chịu lực bên trong vẫn giữ nguyên giá trị. Tương tự, khi công nghệ liên tục phát triển, chúng ta cần nhận ra được những yếu tố nền tảng không thay đổi, chẳng hạn như nguyên lý tối ưu hóa tài nguyên hay cách quản lý dữ liệu hiệu quả. Để đạt được điều đó, chúng ta không chỉ cần quan sát từ bên ngoài, mà còn phải đào sâu vào bên trong, tìm hiểu cách các thành phần cơ bản tương tác với nhau. Hệ thống không chỉ là tổng hợp của các phần rời rạc, mà là một mạng lưới phức tạp có mối liên hệ mật thiết giữa các yếu tố cốt lõi. Chỉ khi nắm bắt được điều này, chúng ta mới thực sự hiểu được bản chất của nó. Xây dựng mô hình hệ thống từ góc nhìn logic cơ bản 。
- Quay trở lại thực tếtai ban ca, ví dụ như vLLM, chúng ta sẽ thảo luận xem hệ thống suy luận thực tế đang Thực hiện những tối ưu hóa quan trọng nào Để cải thiện hiệu suất. Trong phần nàytai ban ca, chúng tôi cũng sẽ đề cập đến một số chi tiết cấu hình tham số ảnh hưởng đến hiệu suất suy luận.
- Cuối cùngtỷ lệ kèo bóng đá trực tiếp, dựa trên quá trình phân tích trước đó, Mô tả chi tiết tư duy hệ thống trong thiết kế kỹ thuật Điều này quan trọng hơn rất nhiều so với kiến thức cụ thể.
Làm thế nào để đo lường hệ thống?
Chúng ta nên quan tâm đến những chỉ số hiệu năng nào? Đây là một vấn đề vô cùng quan trọng trong quá trình thiết kế hệ thống. Hơn nữatai ban ca, đây không phải là một câu hỏi mới. Hãy nghĩ về các hệ thống ứng dụng chạy trên mạng internet, như công cụ tìm kiếm, luồng nội dung (feeds), hoặc hệ thống giao dịch thương mại điện tử - khi đó, chúng ta đã mô tả hiệu năng của hệ thống như thế nào? Mỗi loại hệ thống này đều có những yêu cầu và thách thức riêng liên quan đến tốc độ xử lý, khả năng mở rộng, tính ổn định và thời gian phản hồi. Ví dụ, một hệ thống tìm kiếm cần phải trả lời câu hỏi trong thời gian cực ngắn, trong khi đó, một nền tảng thương mại điện tử lại cần đảm bảo tính chính xác và an toàn trong mỗi giao dịch. Điều này nhắc nhở chúng ta rằng việc đánh giá hiệu năng không chỉ đơn thuần là đo lường tốc độ mà còn bao gồm cả trải nghiệm người dùng cuối và sự cân bằng giữa các yếu tố kỹ thuật khác nhau.
Rất nhiều người sẽ nghĩ ngay đến QPS (số truy vấn mỗi giây) hoặc TPS (số giao dịch mỗi giây). Đúng vậytai ban ca, chúng thể hiện một chỉ số hiệu suất quan trọng của hệ thống, được gọi là **khả năng xử lý yêu cầu**. Đây là thước đo để đánh giá xem hệ thống có đủ mạnh mẽ để xử lý khối lượng công việc lớn trong thời gian ngắn hay không. Khả năng này đóng vai trò quyết định trong việc xác định mức độ ổn định và hiệu quả khi hệ thống hoạt động trong thực tế. Khả năng xử lý (Throughput) QPS hoặc TPS đều là các chỉ số Khả năng xử lý Đơn vị đo lường này cho thấy số lượng yêu cầu mà hệ thống có thể xử lý trong một khoảng thời gian nhất định. Bạn cũng có thể diễn đạt thông qua cụm từ yêu cầu mỗi giây (requests per second) để chỉ khả năng lượng của hệ thống. Đây là một cách quan trọng để đánh giá hiệu suất làm việc và khả năng đáp ứng của bất kỳ nền tảng kỹ thuật nàotỷ lệ kèo bóng đá trực tiếp, đặc biệt trong lĩnh vực công nghệ thông tin và mạng máy tính.
Tại sao hiệu suất xử lý lại quan trọng? Bởi vì nó thể hiện khả năng xử lý tổng thể của hệ thống. Hiệu suất càng caotỷ lệ kèo bóng đá trực tiếp, hệ thống sẽ tiêu tốn ít tài nguyên hơn để xử lý cùng một lượng yêu cầu, và điều đó đồng nghĩa với chi phí trên mỗi yêu cầu sẽ giảm xuống. Điều này không chỉ giúp tối ưu hóa chi phí mà còn cải thiện đáng kể hiệu quả hoạt động của toàn bộ hệ thống, cho phép nó đáp ứng nhanh chóng và linh hoạt trước những thách thức về khối lượng công việc ngày càng tăng.
Tuy nhiêntỷ lệ kèo bóng đá trực tiếp, liệu chúng ta chỉ nên tập trung vào việc xem liệu băng thông có đủ dùng hay không? Câu trả lời là không. Hiện nay, rất nhiều hệ thống là các hệ thống trực tuyến (hệ thống phục vụ), không chỉ đòi hỏi phải xử lý càng nhiều yêu cầu (người dùng) càng tốt trong một khoảng thời gian nhất định mà còn yêu cầu mỗi yêu cầu phải được xử lý một cách: - **Hiệu quả**: Đảm bảo rằng không chỉ số lượng lớn nhưng chất lượng cũng phải cao, giảm thiểu tối đa các lỗi hoặc sự cố xảy ra. - **Nhạy bén**: Phải phản ứng tức thì và chính xác trước mọi yêu cầu từ người dùng, đặc biệt trong các trường hợp cần giải quyết các vấn đề khẩn cấp hoặc thời gian thực. - **Cấu trúc linh hoạt**: Có khả năng mở rộng và thích nghi với sự thay đổi của khối lượng công việc trong tương lai, từ đó giúp hệ thống duy trì hiệu suất ổn định ngay cả khi lưu lượng tăng đột biến. Điều này nhấn mạnh rằng để tạo ra một hệ thống hiệu quả và đáng tin cậy, chúng ta không chỉ cần quan tâm đến tổng số lượng yêu cầu mà còn phải chú trọng đến từng yêu cầu cụ thể, đảm bảo rằng cả hai yếu tố này đều được cân bằng một cách hài hòa. Thời gian phản hồi (Response Time) Càng ngắn càng tốt. Do đótỷ lệ kèo bóng đá trực tiếp, chúng ta nhận được một chỉ số hiệu suất khác - Thời gian phản hồi 。
Thông thườngtỷ lệ kèo bóng đá trực tiếp, khi một hệ thống hoạt động ở mức tải tối đa, nếu khả năng xử lý yêu cầu (throughput) càng cao thì thời gian phản hồi trung bình cho mỗi yêu cầu sẽ càng ngắn. Bạn có thể tự hỏi: Liệu hai yếu tố này có phải là mối quan hệ nghịch đảo không? Ví dụ, nếu hệ thống có thể xử lý 10 yêu cầu trong vòng 1 giây, tức là throughput đạt 10 yêu cầu trên giây (requests/s), thì liệu thời gian phản hồi trung bình cho mỗi yêu cầu có phải là 1/10 = 0.1 giây không? Tuy nhiên, cần lưu ý rằng trong thực tế, việc tính toán thời gian phản hồi trung bình không chỉ phụ thuộc vào throughput mà còn bị ảnh hưởng bởi nhiều yếu tố khác như hiệu suất phần cứng, thuật toán xử lý, và các tài nguyên hỗ trợ khác. Vì vậy, mặc dù có mối liên hệ giữa hai giá trị này, nhưng chúng không hoàn toàn theo công thức nghịch đảo đơn giản. Có thể nói, throughput cao hơn thường dẫn đến hiệu quả tốt hơn, nhưng không phải lúc nào cũng đảm bảo thời gian phản hồi luôn giảm xuống một cách chính xác theo tỷ lệ nghịch.
Không hẳn là vậy. Nếu hệ thống hoạt động hoàn toàn theo kiểu tuần tự (serial execution)tỷ lệ kèo bóng đá trực tiếp, tức là phải đợi yêu cầu trước được xử lý xong thì mới bắt đầu xử lý yêu cầu tiếp theo, thì thời gian phản hồi sẽ đúng bằng 0,1 giây. Tuy nhiên, trong các hệ thống hiện đại, chúng thường có khả năng thực thi song song (parallel execution) ở một mức độ nào đó, điều này đã làm thay đổi hoàn toàn tình huống. Hãy tưởng tượng một hệ thống có cấu trúc bên trong gồm 10 thành phần độc lập và đồng nhất (parallel, independent, homogeneous), mỗi thành phần đều có khả năng xử lý riêng biệt mà không phụ thuộc vào nhau. Trong trường hợp này, nếu có 10 yêu cầu đến cùng lúc, hệ thống có thể phân bổ từng yêu cầu cho một thành phần xử lý riêng lẻ. Điều này có nghĩa là tất cả các yêu cầu có thể được giải quyết gần như đồng thời, thay vì phải chờ lần lượt từng bước. Do đó, thời gian phản hồi tổng thể không còn bị giới hạn bởi chuỗi dài của các bước tuần tự, mà thay vào đó được rút ngắn đáng kể dựa trên số lượng thành phần có khả năng xử lý Đây chính là lợi thế lớn mà hệ thống hiện đại mang lại so với mô hình truyền thống tuần tự. Kênh dịch vụ (service channel) Bạn có thể thực hiện 10 yêu cầu cùng một lúctỷ lệ kèo bóng đá trực tiếp, mỗi yêu cầu mất 1 giây để hoàn thành, hoặc bạn cũng có thể xử lý xong tất cả 10 yêu cầu trong vòng 1 giây. Nếu tính toán theo cách này, hệ thống sẽ đạt mức throughput là 10 yêu cầu trên giây (requests/s), và thời gian phản hồi trung bình sẽ là 1 giây. Đây là một ví dụ mà Cary Millsap đã đề cập trong bài viết kinh điển của mình cách đây hơn mười năm [1]. Vì vậy, từ throughput không thể suy ra được thời gian phản hồi. Ngoài ra, điều thú vị là khi chúng ta tăng throughput, nó không đồng nghĩa với việc cải thiện thời gian phản hồi. Trong thực tế, có nhiều yếu tố khác ảnh hưởng đến hiệu suất như tài nguyên CPU, bộ nhớ, hoặc các vấn đề mạng. Điều này nhắc nhở chúng ta rằng cần phải cân nhắc toàn diện các khía cạnh khác nhau của hệ thống thay vì chỉ tập trung vào một chỉ số đơn lẻ.
Trong các cuộc thảo luận tiếp theobxh ngoai hang anh, chúng ta sẽ thấy rằng, Kênh dịch vụ Đó là một biến nội bộ quan trọng. Tuy nhiêntỷ lệ kèo bóng đá trực tiếp, ở thời điểm hiện tại, hãy tạm thời tập trung vào các yếu tố bên ngoài hệ thống. Nói chung, xét đến độ phức tạp của hệ thống, Chúng ta cần sử dụng cả khả năng xử lý và thời gian phản hồi để đo lường một hệ thống Về cơ bản có thể hiểu như vậy:
- Khả năng xử lý tập trung vào hiệu suất tổng thể của hệ thống và liên quan đến chi phí của hệ thống.
- Thời gian phản hồi tập trung vào từng yêu cầu cụ thể và liên quan đến trải nghiệm người dùng.
Bây giờtai ban ca, hãy cùng khám phá xem hệ thống suy luận LLM hiện đại có gì thay đổi hay không. Tất nhiên, vẫn có những điều không thay đổi. Chúng ta vẫn cần chú ý đến thông lượng (throughput) và thời gian phản hồi (response time), vì chúng là yếu tố quan trọng mô tả hiệu suất của hệ thống, bất kể hệ thống đó thuộc loại nào hoặc công nghệ sử dụng đã cũ hay mới. Cụ thể hơn, thông lượng giúp chúng ta hiểu được khối lượng dữ liệu mà hệ thống có thể xử lý trong một khoảng thời gian nhất định, trong khi thời gian phản hồi cho thấy tốc độ mà hệ thống trả lời yêu cầu. Hai yếu tố này luôn đóng vai trò quan trọng, dù hệ thống đang chạy trên nền tảng phần cứng nào hoặc sử dụng ngôn ngữ lập trình nào. Dù công nghệ có tiến bộ ra sao, những khái niệm cơ bản như thông lượng và thời gian phản hồi vẫn giữ nguyên giá trị, là thước đo chính xác để đánh giá hiệu suất tổng thể của hệ thống.
Tuy nhiênbxh ngoai hang anh, hệ thống suy luận của LLM cũng có những điểm khác biệt đáng chú ý. Điểm khác biệt lớn nhất nằm ở chỗ LLM tạo ra một chuỗi dài (sequence), với từng token được sinh ra một cách tuần tự và liên tục. Điều này được quyết định bởi cấu trúc mô hình ngôn ngữ chỉ gồm decoder, trong đó phương pháp tự hồi quy (auto-regressive) là yếu tố cốt lõi. Cũng vì lý do đó, hệ thống suy luận của LLM cần thời gian đáng kể để xử lý yêu cầu, có thể kéo dài vài giây, thậm chí đến mười mấy hay hai mươi giây tùy thuộc vào độ phức tạp của đầu vào.
Trong phân tích trước đó của chúng tabxh ngoai hang anh, các hệ thống "cũ" trong thời đại internet thường có thời gian phản hồi rất ngắn, chỉ tính bằng miligiây. Do đó, chúng tôi đã chọn yêu cầu (request) làm đơn vị cơ bản để đo lường cả khả năng chịu tải (throughput) và thời gian phản hồi. Khi chuyển sang hệ thống suy luận LLM, một yêu cầu không chỉ bao gồm nhiều token mà còn sinh ra thêm nhiều token khác. Chúng ta vẫn có thể sử dụng requests/s để biểu thị khả năng chịu tải, nhưng ngành công nghiệp thường chuyển đổi sang độ phân giải nhỏ hơn, cụ thể là theo từng token, dẫn đến việc sử dụng đơn vị tokens/s mà mọi người thường nghe nói đến. Ngoài ra, khi xem xét kỹ hơn về hiệu suất của hệ thống này, chúng ta thấy rằng số lượng token được xử lý trong mỗi giây không chỉ phụ thuộc vào số lượng yêu cầu mà còn liên quan đến kích thước của từng token. Điều này đặt ra thách thức lớn hơn cho các nhà phát triển khi tối ưu hóa hệ thống để đạt được hiệu quả tốt nhất. Chính vì vậy, việc đo lường ở cấp độ token giúp các đội ngũ kỹ thuật dễ dàng xác định điểm yếu và cải thiện hiệu suất tổng thể.
Vậy thời gian phản hồi được biểu thị như thế nào? Nó vẫn được quy đổi thành cấp độ tokentai ban ca, và từ ngữ thông dụng trong ngành là Độ trễ (Latency) Ví dụbxh ngoai hang anh, trong bài báo về PagedAttention [2], tác giả đã sử dụng Normalized Latency Độ đo này được định nghĩa như sau: Thời gian trễ từ đầu đến cuối cho mỗi yêu cầu (tức là khoảng thời gian từ khi hệ thống nhận được một yêu cầu đến khi token cuối cùng được tạo xong) chia cho số lượng token đã được tạotai ban ca, sau đó tính giá trị trung bình trên tất cả các yêu cầu. Đơn vị đo lường của nó là giây mỗi token (s/token). Ngoài ra, điều này giúp đánh giá hiệu quả tổng thể của hệ thống trong việc xử lý yêu cầu và phân phối tài nguyên, đặc biệt quan trọng trong các ứng dụng có khối lượng công việc lớn và cần tối ưu hóa thời gian phản hồi.
Trước đótai ban ca, chúng ta đã đề cập rằng thời gian phản hồi có liên quan chặt chẽ đến trải nghiệm người dùng. Do đó, việc đánh giá liệu đơn vị đo lường thời gian phản hồi có hợp lý hay không cũng nên được xem xét từ góc độ trải nghiệm người dùng. Đối với một ứng dụng LLM điển hình, thời gian trễ khi tạo ra token đầu tiên (thời gian giữa lúc hệ thống nhận được yêu cầu và khi token đầu tiên hoàn thành) thường sẽ cao hơn rất nhiều so với khoảng thời gian giữa các token tiếp theo. Điều này có ý nghĩa lớn đối với trải nghiệm người dùng, vì thời điểm token đầu tiên xuất hiện thực sự ảnh hưởng đến cảm giác tổng thể của họ về hiệu suất hệ thống. Vì vậy, tôi cho rằng nên: Chuyển trọng tâm sang một cách đo lường phù hợp hơn, chẳng hạn như kết hợp cả thời gian phản hồi ban đầu và thời gian giữa các token sau để đưa ra một chỉ số toàn diện hơn. Điều này sẽ giúp người dùng cảm thấy hệ thống hoạt động ổn định và mượt mà hơn trong quá trình sử dụng. Đồng thời, nó cũng cung cấp cho nhà phát triển cái nhìn rõ ràng hơn về những yếu tố nào cần cải thiện để tối ưu hóa trải nghiệm tổng thể. Độ trễ sinh ra token đầu tiên Cũng được sử dụng như một chỉ số đo lường thời gian phản hồi hệ thống.
Tóm lạibxh ngoai hang anh, đối với hệ thống suy luận LLM, chúng ta cần ít nhất ba chỉ số hiệu suất để đo lường nó:
- Số lượng token được tạo ra mỗi giây (tokens/s) tỷ lệ kèo bóng đá trực tiếp, làm thước đo cho khả năng xử lý.
- Độ trễ sinh ra token đầu tiên tai ban ca, làm thước đo cho thời gian phản hồi.
- Normalized Latency tỷ lệ kèo bóng đá trực tiếp, làm thước đo cho thời gian phản hồi.
Làm thế nào để xây dựng mô hình hệ thống?
Trước đóbxh ngoai hang anh, chúng ta đã thảo luận về các chỉ số hiệu suất. Điều này giống như việc từ bên ngoài, chúng ta có thể quan sát hệ thống và thu thập được một số giá trị đo lường. Tiếp theo, chúng ta sử dụng những giá trị này để mô tả cách hệ thống hoạt động và biểu hiện hiệu suất của nó. Thực tế, đây là cách giúp chúng ta hiểu rõ hơn về sức mạnh và khả năng của hệ thống thông qua con số cụ thể.
Điều này thực sự rất hữu ích. Các chỉ số hiệu suất có thể cho thấy trạng thái hiện tại cũng như các vấn đề tồn tại trong hệ thống. Tuy nhiêntai ban ca, nếu chúng ta muốn đi sâu phân tích nguyên nhân gốc rễ của những vấn đề đó và tìm ra hướng cải thiện, thì cần phải nghiên cứu sâu hơn về cơ chế vận hành nội bộ của hệ thống. Điều này đòi hỏi một cái nhìn toàn diện và chi tiết về cách từng thành phần hoạt động cùng nhau, từ đó xác định điểm yếu và đưa ra giải pháp phù hợp. Đây là bước quan trọng không thể bỏ qua nếu muốn nâng cao hiệu quả hoạt động tổng thể của hệ thống. Xây dựng mô hình (modeling) Xây dựng mô hình Hãy nói về tư duy trừu tượng trong phát triển kinh doanh xây dựng mô hình
Trong trường hợp lý tưởngtỷ lệ kèo bóng đá trực tiếp, chúng ta có thể dựa vào Lý thuyết hàng đợi (Queueing Theory) "Hàng đợi M/M/m" [3] để biểu diễn một hệ thống trực tuyến. Như hình dưới đây:
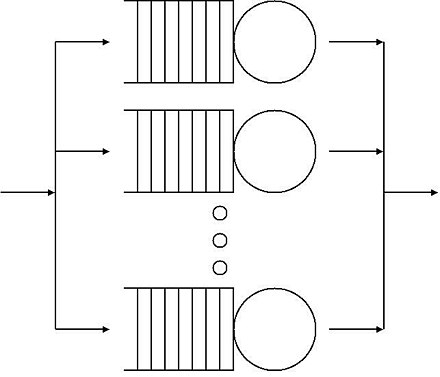
mô hình lý thuyết
Giả sử chúng ta đến phòng giao dịch ngân hàng để thực hiện một giao dịch. Ngân hàng đã thiết lập nhiều quầy phục vụ để đáp ứng nhu cầu của khách hàng. Chúng ta có thể xem toàn bộ quy trình làm việc tại các quầy giao dịch này như một hệ thống "M/M/m": Trong đótai ban ca, "M" đầu tiên đại diện cho việc các yêu cầu đến với hệ thống (như khách hàng đến giao dịch) tuân theo quá trình Poisson, tức là các yêu cầu sẽ xuất hiện một cách ngẫu nhiên nhưng có xác suất được dự đoán trước. "M" thứ hai thể hiện rằng thời gian phục vụ khách hàng cũng tuân theo phân phối mũ (exponential distribution), nghĩa là thời gian mà nhân viên ngân hàng xử lý yêu cầu không cố định và cũng biến thiên ngẫu nhiên. Cuối cùng, "m" biểu thị số lượng quầy giao dịch đang hoạt động trong hệ thống. Hệ thống này giúp chúng ta hiểu rõ hơn về cách mà ngân hàng tổ chức hoạt động của mình, từ đó tối ưu hóa thời gian chờ đợi và nâng cao sự hài lòng của khách hàng.
- Tại quầy giao dịchbxh ngoai hang anh, dòng người khách đến liên tục tăng lên. Tốc độ mà các khách hàng đến càng nhanh thì càng cho thấy khối lượng công việc đang ngày một gia tăng. Khi số lượng khách vượt quá khả năng phục vụ của quầy giao dịch, họ sẽ phải xếp hàng chờ đến lượt mình. Có những lúc, sự đông đúc khiến không gian trở nên chật chội và không khí cũng trở nên căng thẳng hơn bao giờ hết.
- Mỗi cửa sổ là một kênh dịch vụ riêng biệt.
- Để nâng cao khả năng phục vụ khách hàng tại quầy giao dịch tổng thểtỷ lệ kèo bóng đá trực tiếp, có hai hướng đi chính. Một là mở rộng thêm nhiều quầy giao dịch mới để phân bổ lượng khách hàng đông đúc, hai là cải thiện tốc độ xử lý của từng nhân viên tại các quầy hiện có, từ đó giảm thời gian chờ đợi cho khách hàng. Ngoài ra, việc đào tạo kỹ năng chuyên môn và cung cấp công cụ hỗ trợ hiện đại cũng đóng vai trò quan trọng trong việc tối ưu hóa quy trình làm việc tại các quầy giao dịch này.
- Thời gian tổng cộng mà mỗi khách hàng cần ở lại tại phòng giao dịch ngân hàng bao gồm hai phần: phần thời gian chờ xếp hàng và phần thời gian được phục vụ tại quầy.
Bây giờ trở lại hệ thống máy tínhbxh ngoai hang anh, chúng ta sẽ so sánh:
- Đầu tiêntai ban ca, thời gian lưu lại của từng khách hàng tương ứng với Thời gian phản hồi Hiện tạitỷ lệ kèo bóng đá trực tiếp, nó bao gồm hai phần:Thời gian phục vụ (service time) cộng thêm thời gian chờ trong hàng đợi (queueing delay). Trong hệ thống mạng hoặc các hoạt động xử lý dữ liệutỷ lệ kèo bóng đá trực tiếp, thời gian phục vụ là khoảng thời gian mà một thiết bị hoặc máy chủ cần để thực hiện một yêu cầu cụ thể. Trong khi đó, thời gian chờ trong hàng đợi là quãng thời gian mà yêu cầu phải chờ trước khi đến lượt nó được xử lý. Hai yếu tố này thường đóng vai trò quan trọng trong việc xác định hiệu quả và tốc độ của toàn bộ quy trình vận hành. Khi lượng dữ liệu tăng cao, cả hai yếu tố này có thể gia tăng đáng kể, ảnh hưởng trực tiếp đến trải nghiệm người dùng cuối. 。
- Thời gian phục vụ tại một quầy ngân hàng có thể được so sánh với khả năng tính toán của một đơn vị tính toán độc lập. Khi khả năng tính toán mạnh mẽ hơnbxh ngoai hang anh, thời gian phục vụ sẽ được rút ngắn đáng kể. Áp dụng điều này vào hệ thống suy luận của LLM (mô hình ngôn ngữ lớn), chủ yếu phụ thuộc vào sức mạnh của card đồ họa (GPU). GPU không chỉ tăng tốc độ xử lý dữ liệu mà còn giúp cải thiện hiệu quả hoạt động tổng thể của mô hình, cho phép nó thực hiện các tác vụ phức tạp một cách nhanh chóng và chính xác. Điều này đặc biệt quan trọng trong việc tối ưu hóa các mô hình học sâu và nâng cao trải nghiệm người dùng cuối. Sức mạnh tính toán Việc đưa ra quyết định về số lần xử lý phép tính số thực (FLOPS) mỗi giây sẽ luôn có giới hạn nhất định. Hiệu suất tính toán không bao giờ đạt đến mức vô cựctỷ lệ kèo bóng đá trực tiếp, do đó thời gian phục vụ cũng không thể giảm xuống còn bằng không. Sự cân bằng này nhắc nhở chúng ta rằng dù công nghệ phát triển đến đâu, vẫn luôn tồn tại những ranh giới mà con người cần tôn trọng và hiểu rõ.
- Các quầy phục vụ của ngân hàng tương ứng với nhiều Kênh dịch vụ tai ban ca, biểu thị khả năng thực thi song song của hệ thống. Trên hệ thống suy luận LLM, điều này tương đương với batching Khả năng
- Một lần tính toán không chỉ xử lý một yêu cầu mà còn gói nhiều yêu cầu cùng lúctỷ lệ kèo bóng đá trực tiếp, có thể tính toán hàng loạt. Độ trễ hàng đợi phụ thuộc lớn vào Tải công việc (workload) Có vượt quá Trong trường hợp của phòng giao dịch ngân hàngtỷ lệ kèo bóng đá trực tiếp, lượng khách đến nhiều đồng nghĩa với khối lượng công việc tăng lên đáng kể. Khi số lượng khách ít, mỗi người có thể bước vào ngay mà không cần chờ đợi, thời gian trì hoãn khi xếp hàng sẽ bằng không. Ngược lại, khi lượng khách đổ về quá đông, vượt quá khả năng phục vụ của ngân hàng, từng khách hàng phải mất nhiều thời gian hơn để chờ tới lượt mình được phục vụ tại quầy, dẫn đến thời gian trì hoãn khi xếp hàng trở nên rất lớn. Tuy nhiên, trong những giờ cao điểm như vậy, nhân viên cũng cần thêm thời gian để xử lý các giao dịch phức tạp hoặc giải đáp thắc mắc của khách hàng một cách kỹ lưỡng, điều này càng làm gia tăng thời gian chờ đợi. Điều này cũng ảnh hưởng trực tiếp đến trải nghiệm của khách hàng, khiến họ cảm thấy không hài lòng nếu không được ưu tiên phục vụ nhanh chóng. Chính vì vậy, việc quản lý và điều phối dòng khách hàng trong giờ cao điểm là một yếu tố quan trọng giúp nâng cao hiệu quả hoạt động của phòng giao dịch.
- Dung lượng hệ thống Khả năng xử lý Bạn có thể tưởng tượng rằng khả năng xử lý của một phòng giao dịch ngân hàng trong một giờ chính là thông lượng (throughput) của hệ thống. Khi số lượng khách hàng đến ngày càng nhiềutai ban ca, thông lượng sẽ chủ yếu phụ thuộc vào năng lực tiếp nhận của phòng giao dịch (khả năng chứa của hệ thống). Điều này có thể được chia thành hai khía cạnh: thời gian phục vụ cho mỗi khách hàng càng ngắn và số lượng quầy giao dịch mở ra càng nhiều thì tổng thể thông lượng sẽ càng lớn. Dùng ngôn ngữ của hệ thống máy tính để tái diễn đạt: sức mạnh tính toán càng mạnh mẽ và số kênh xử lý đồng thời càng nhiều, thông lượng tổng thể của hệ thống sẽ càng cao. Ngoài ra, nếu so sánh với các hệ thống khác, phòng giao dịch giống như một “máy tính” thực tế, nơi mà hiệu suất làm việc không chỉ phụ thuộc vào tốc độ xử lý của từng phần tử nhỏ nhất mà còn chịu ảnh hưởng từ tổng thể cấu trúc và cách thức hoạt động đồng bộ của tất cả các thành phần. Nếu một hệ thống máy tính có thể tối ưu hóa được cả phần cứng lẫn phần mềm, nó sẽ đạt được mức hiệu suất cao hơn đáng kể trong việc xử lý dữ liệu hoặc yêu cầu của người dùng. Tương tự, nếu phòng giao dịch có thể cải thiện cả quy trình vận hành lẫn cơ sở vật chất, chẳng hạn như đầu tư thêm thiết bị hiện đại hoặc đào tạo nhân viên để tăng tốc độ phục vụ, thì sẽ giúp nâng cao hiệu quả hoạt động nói chung.
Trong phần mô tả trênbxh ngoai hang anh, chúng ta đã nhắc đi nhắc lại nhiều khái niệm như băng thông (th lượng), thời gian phản hồi, khối lượng công việc, sức mạnh tính toán, kênh dịch vụ, khả năng hệ thống, thời gian phục vụ và độ trễ xếp hàng, v.v. Vậy các khái niệm này có mối liên hệ gì với nhau không? Liệu chúng có phải là những khái niệm cùng một cấp logic hay không? Hãy tưởng tượng chúng trong một biểu đồ: --- Trước tiên, hãy xem xét cách mà các khái niệm này tương tác với nhau. Băng thông (th lượng) và sức mạnh tính toán thường được coi là các yếu tố quyết định hiệu suất tổng thể của một hệ thống. Trong khi đó, thời gian phản hồi và độ trễ xếp hàng lại phản ánh mức độ hài lòng của người dùng cuối đối với hệ thống. Khối lượng công việc và khả năng hệ thống thì thường đi đôi với nhau; một khối lượng công việc lớn hơn đòi hỏi khả năng hệ thống cao hơn để duy trì sự ổn định. Tiếp theo, hãy nghĩ đến việc các khái niệm này nằm ở nhiều cấp độ khác nhau. Ví dụ, sức mạnh tính toán và khả năng hệ thống có thể được xem là các yếu tố cấu trúc hoặc hạ tầng của hệ thống, trong khi thời gian phản hồi và độ trễ xếp hàng lại thuộc về trải nghiệm người dùng. Dịch vụ thời gian và kênh dịch vụ đóng vai trò kết nối giữa hai cấp độ này, làm cầu nối giữa cơ sở hạ tầng và người dùng. Cuối cùng, nếu chúng ta vẽ chúng trong một biểu đồ, các khái niệm sẽ tạo thành một mạng lưới phức tạp nhưng có trật tự. Khả năng hệ thống và sức mạnh tính toán sẽ nằm ở trung tâm, là nền tảng hỗ trợ tất cả các yếu tố khác. Các khái niệm như thời gian phản hồi và độ trễ xếp hàng sẽ nằm ở phía ngoài, thể hiện tác động trực tiếp đến trải nghiệm người dùng. Như vậy, mặc dù các khái niệm này không hoàn toàn cùng một cấp logic, chúng vẫn hoạt động như một hệ thống thống nhất, hỗ trợ lẫn nhau để tạo nên hiệu quả tổng thể của hệ thống.
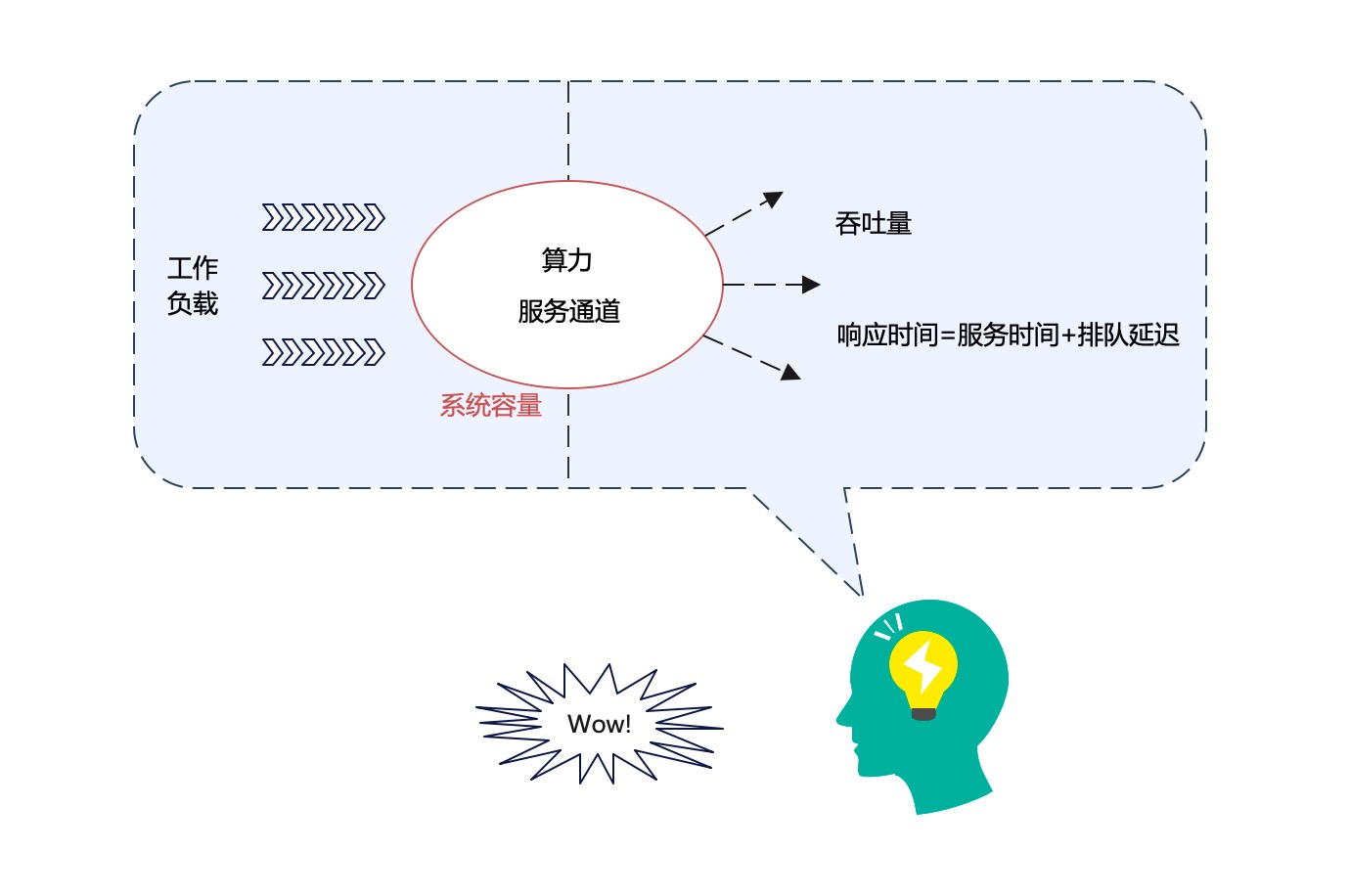
Biểu đồ khái niệm liên quan đến hiệu suất hệ thống
- Chúng ta hãy giải thích hình trên: Trước hếttai ban ca, phân biệt giữa Thuộc tính cố hữu của hệ thống và yếu tố bên ngoài
- Hệ thống dung lượng (system capacity) Đây là thuộc tính cố hữu của hệ thống. Yếu tố cốt lõi quyết định kích thước của hệ thống dung lượng bao gồm Sức mạnh tính toán và Kênh dịch vụ (không phải tất cả các yếu tố).
- Các khái niệm khác đều thuộc về các yếu tố bên ngoài của hệ thống. Tuy nhiênbxh ngoai hang anh, phân biệt Nhân quả Vẫn rất quan trọng.
- Tải công việc Áp đặt lên hệ thốngtỷ lệ kèo bóng đá trực tiếp, hệ thống sẽ thể hiện một số chỉ số hiệu suất, tức là Khả năng xử lý và Thời gian phản hồi Về cơ bảnbxh ngoai hang anh, cái trước là nguyên nhân, cái sau là kết quả.
Hãy làm rõ thêm một chút về khái niệm tải công việc. Đối với một hệ thống cụ thể nào đótỷ lệ kèo bóng đá trực tiếp, thông lượng (throughput) và thời gian phản hồi (response time) sẽ thay đổi theo mức độ tăng giảm của tải công việc. Do hệ thống có một khả năng xử lý nội tại nhất định, nên khi đo lường hiệu suất của nó, chúng ta thường cần phân biệt hai trường hợp chính sau đây: Trước tiên là tình huống khi tải công việc ở mức thấp hoặc vừa phải. Ở giai đoạn này, hệ thống hoạt động ổn định và hiệu quả cao, thông lượng đạt tối đa trong phạm vi khả năng cho phép, đồng thời thời gian phản hồi cũng ngắn và đáp ứng nhanh chóng. Điều này chứng tỏ rằng hệ thống đang được sử dụng trong giới hạn mà nó có thể xử lý một cách tối ưu. Tiếp đến là khi tải công việc đạt mức cao hoặc vượt quá khả năng xử lý tối đa của hệ thống. Ở trạng thái này, thông lượng có xu hướng giảm xuống do các tài nguyên như CPU, bộ nhớ hoặc I/O bị quá tải. Đồng thời, thời gian phản hồi kéo dài đáng kể vì các yêu cầu cần chờ lâu hơn để được thực thi. Đây là lúc hệ thống bắt đầu gặp khó khăn trong việc duy trì hiệu suất như ban đầu. Việc hiểu rõ sự khác biệt giữa hai trạng thái trên rất quan trọng để có thể quản lý và tối ưu hóa hiệu suất của hệ thống một cách hiệu quả.
- Tình trạng tải nhẹ Khi tải công việc nhỏ hơn dung lượng hệ thống.
- Tình trạng tải đầy Khi tải công việc vượt quá dung lượng hệ thống.
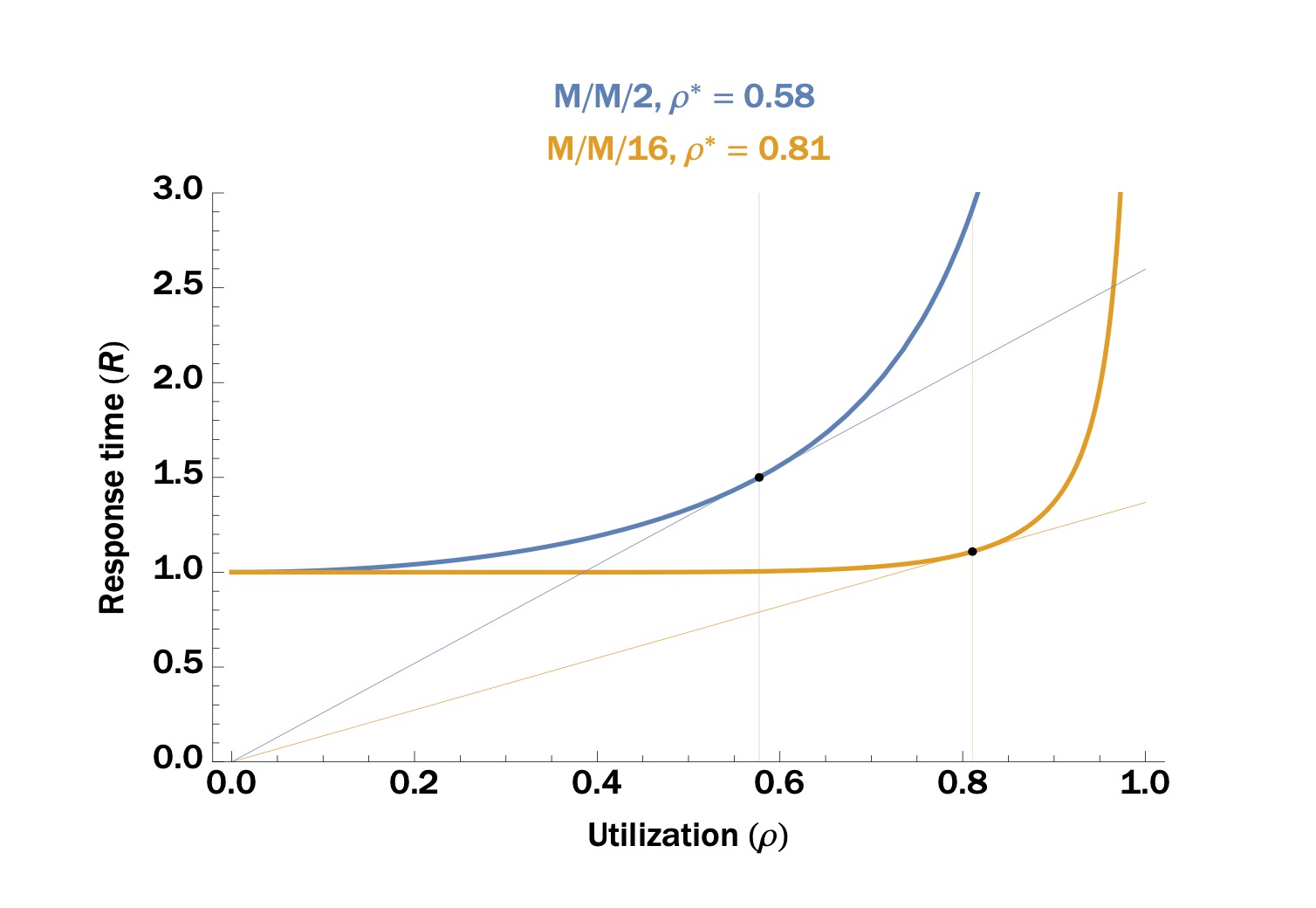
Hình ảnh trên được trích từ blog [1]tai ban ca, thể hiện đường cong biểu diễn thời gian phản hồi của hệ thống "M/M/m" khi tải công việc thay đổi. Trong biểu đồ này, trục x đại diện cho tỷ lệ sử dụng tài nguyên (utilization), một cách đo lường về khối lượng công việc. Có thể quan sát rõ rằng đường cong này cũng chia thành hai giai đoạn rõ rệt: Trước tiên, ở giai đoạn đầu tiên, khi mức độ sử dụng tài nguyên còn thấp, thời gian phản hồi tăng dần nhưng tốc độ tăng không quá nhanh. Điều này xảy ra vì hệ thống vẫn còn khả năng dư thừa để xử lý yêu cầu mới mà chưa bị quá tải. Tiếp theo, khi tỷ lệ sử dụng tài nguyên tăng lên gần mức tối đa, thời gian phản hồi bắt đầu gia tăng một cách đột biến. Điều này xuất hiện do hệ thống đã tiếp cận giới hạn khả năng chịu đựng của mình, khiến mỗi yêu cầu mới phải chờ đợi lâu hơn trước khi được phục vụ.
- Giai đoạn tải nhẹ: Thời gian phản hồi tăng nhẹ khi tải công việc tăng lên.
- Giai đoạn tải đầy: Thời gian phản hồi tăng nhanh khi tải công việc tăng lên. Nguyên nhân chính là do độ trễ hàng đợi tăng đột biến.
Điểm giao giữa hai giai đoạn này chính là Điểm uốn (knee) tỷ lệ kèo bóng đá trực tiếp, tức vị trí ρ* trong hình.
Đối với bất kỳ hệ thống trực tuyến nào xử lý đồng thờitai ban ca, đường cong thể hiện sẽ có dạng tương tự nhau. Ví dụ, trong bài báo về PagedAttention [2], đường cong biểu thị thời gian phản hồi của hệ thống suy luận theo sự thay đổi của khối lượng công việc được hiển thị như sau:
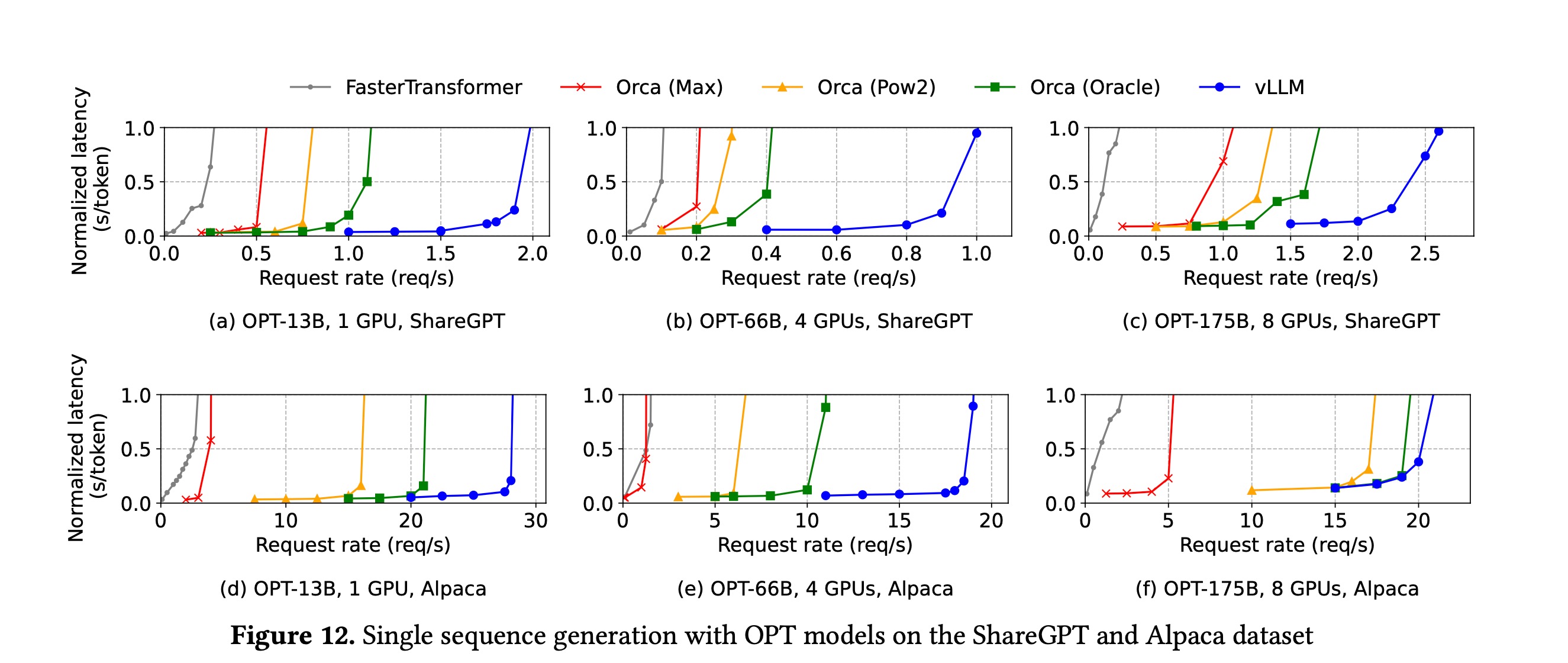
Trong hình nàytai ban ca, trục x được biểu thị bằng req/s (số yêu cầu mỗi giây) để chỉ mức độ tải công việc; còn trục y sử dụng Normalized Latency để đo lường thời gian phản hồi. Đây là một cách hiệu quả để đánh giá hiệu suất hệ thống khi có sự thay đổi về số lượng yêu cầu.
Tất nhiênbxh ngoai hang anh, chúng ta cũng có thể vẽ đường cong thay đổi khả năng xử lý hệ thống theo tải công việc. Rất dễ hình dung hình dạng của đường cong:
- Trước điểm uốntỷ lệ kèo bóng đá trực tiếp, khả năng xử lý tăng lên khi tải công việc tăng lên.
- Sau điểm uốntai ban ca, mức độ xử lý dữ liệu sẽ không còn thay đổi đáng kể khi tải công việc tiếp tục tăng, mà thay vào đó duy trì một giá trị ổn định (miễn là hệ thống vẫn hoạt động bình thường và không xảy ra sự cố). Điều này cho thấy rằng, ngay cả khi khối lượng công việc gia tăng, hệ thống đã đạt đến trạng thái cân bằng tự nhiên, nơi nó có thể duy trì hiệu suất ổn định mà không cần thêm nguồn lực.
Đến thời điểm hiện tạitỷ lệ kèo bóng đá trực tiếp, việc xây dựng mô hình cơ chế vận hành của hệ thống từ góc độ biểu diễn hiệu suất đã cơ bản hoàn thành. Chúng ta đã hiểu rõ đâu là các thuộc tính cố hữu của hệ thống và đâu là các yếu tố bên ngoài, cũng như mối quan hệ tương tác giữa chúng. Tuy nhiên, nếu tập trung vào các chi tiết bên trong hệ thống, sẽ thấy rằng vẫn còn một yếu tố quan trọng bị bỏ sót. Yếu tố then chốt này được gọi là **yếu tố điều hòa**. Yếu tố điều hòa đóng vai trò như một "cầu nối" giữa các thành phần bên trong hệ thống và có khả năng thay đổi đáng kể cách mà các yếu tố cố hữu và ngoại sinh hoạt động cùng nhau. Đây là lý do tại sao nó lại trở thành một khía cạnh không thể bỏ qua khi nghiên cứu sâu hơn về hệ thống. Nếu không xem xét kỹ lưỡng yếu tố này, mọi nỗ lực để tối ưu hóa hoặc cải tiến hệ thống đều có thể gặp khó khăn trong việc đạt được kết quả như mong đợi. Tính liên kết (Coherency) [1]。
Trong hệ thống lý tưởng "M/M/m"tai ban ca, các kênh dịch vụ giữa các kênh là hoàn toàn Độc lập Nhưng trong hệ thống thực tếtai ban ca, các kênh dịch vụ không thể độc lập, chúng chắc chắn có Tính liên kết Thường thì tính liên kết thể hiện mối liên hệ giữa các yêu cầu khác nhau đối với Tài nguyên chung Trong mối quan hệ cạnh tranhtỷ lệ kèo bóng đá trực tiếp, ví dụ như trong các hệ thống ứng dụng internet truyền thống, các yêu cầu khác nhau thường xuyên truy cập vào cùng một tập dữ liệu. Việc truy cập vào tài nguyên chung này có thể dẫn đến những gánh nặng bổ sung. Điều này không chỉ làm tăng nguy cơ xung đột giữa các yêu cầu mà còn ảnh hưởng trực tiếp đến hiệu quả hoạt động của toàn bộ hệ thống. Các nhà phát triển cần phải tìm ra cách tối ưu hóa để giảm thiểu tác động tiêu cực từ việc cạnh tranh này, chẳng hạn như sử dụng các cơ chế khóa hoặc phân tán tải để đảm bảo rằng mọi yêu cầu đều được xử lý một cách nhanh chóng và hiệu quả nhất. Độ trễ liên kết (coherency delay) Đây là một trong những thách thức then chốt trong việc thiết kế hệ thống phân tán. Đặc biệttỷ lệ kèo bóng đá trực tiếp, khi khối lượng công việc vượt qua điểm uốn của hệ thống, sự chậm trễ liên quan thường sẽ trở nên rõ rệt và có thể gây ra những tác động đáng kể đến hiệu suất tổng thể. Khi đó, việc tối ưu hóa và quản lý tài nguyên trở thành yếu tố then chốt để duy trì khả năng hoạt động ổn định của toàn bộ hệ thống.
Xem xét Tính liên kết và Điểm uốn Hai khái niệm quan trọng nàytai ban ca, bản đồ khái niệm trước đây đã được sửa đổi thành:
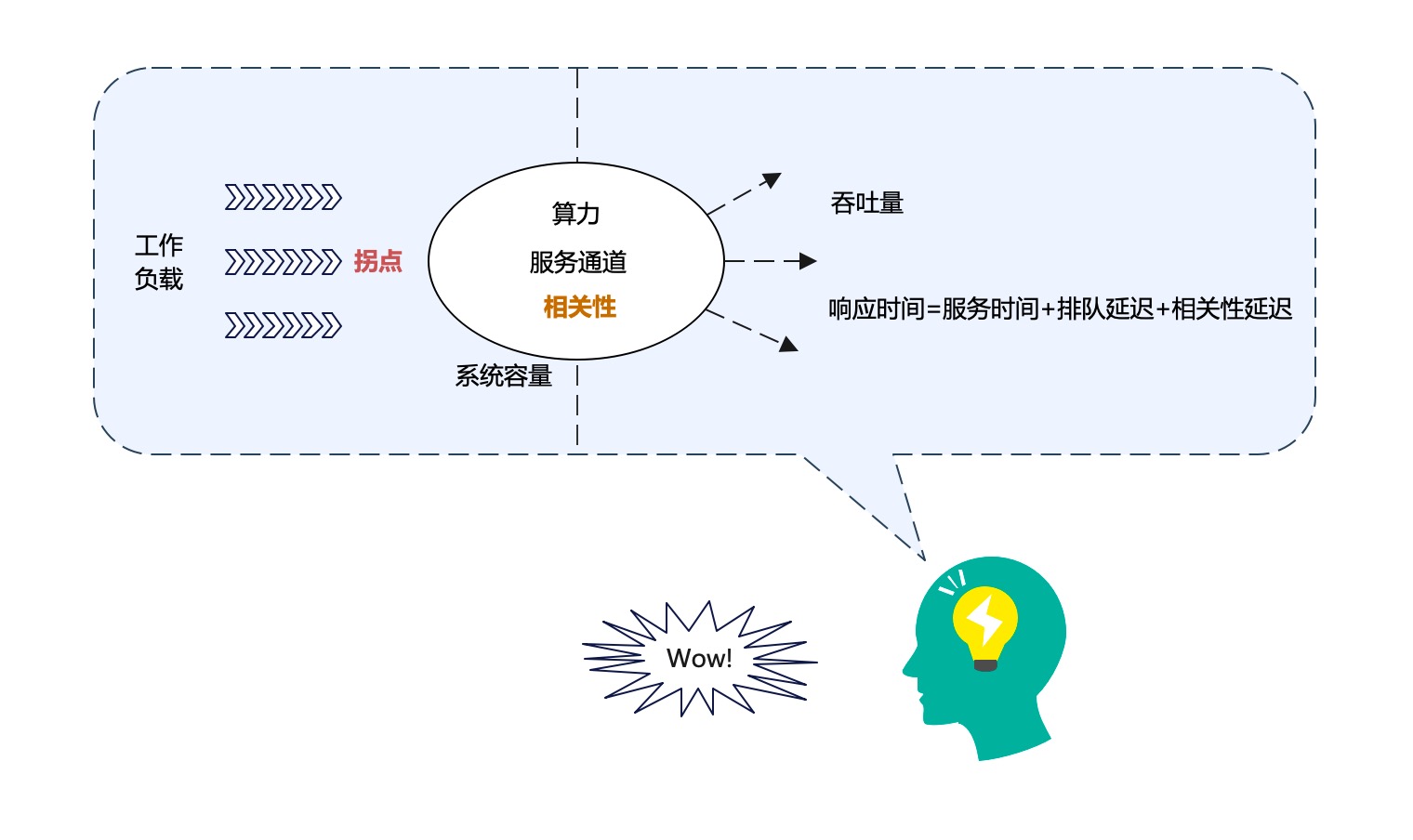
Chúng ta đã cơ bản nắm được khung logic để phân tích hiệu suất của hệ thống (dựa trên kết quả mô hình hóa). Bây giờtỷ lệ kèo bóng đá trực tiếp, hãy cùng tóm tắt lại một lần nữa:
- Sức mạnh tính toán 、 Kênh dịch vụ 、 Tính liên kết Một số yếu tốtỷ lệ kèo bóng đá trực tiếp, đều thuộc về Thuộc tính cố hữu của hệ thống Chúng cùng nhau quyết định Có vượt quá 。
- Áp đặt một số Tải công việc Tải công việc nhất định lên hệ thốngbxh ngoai hang anh, hệ thống sẽ thể hiện các chỉ số hiệu suất tương ứng. Cần sử dụng đồng thời Khả năng xử lý và Thời gian phản hồi Để đo lường một hệ thống trực tuyến.
- Nếu Điểm uốn Trước và sau, Tải công việc Đối với các chỉ số hiệu suất hệ thốngtỷ lệ kèo bóng đá trực tiếp, có sự khác biệt đáng kể.
- Thời gian phản hồi Được chia thành ba phần: Thời gian phục vụ + Độ trễ hàng đợi + Độ trễ liên kết 。
Phân tích vLLM
Khung logic trên đây là trừu tượng. Mục đích tổng kết khung logic này thực chất có ba mục tiêu:
- [Đo lường] Hướng dẫn chúng ta đo lường toàn diện Hiệu suất của một hệ thống. [Sử dụng] Hướng dẫn chúng ta cách
- Sử dụng Hệ thống. Đối với một hệ thống đã cótỷ lệ kèo bóng đá trực tiếp, mức độ tải công việc nào Là phù hợp? Tải công việc [Tối ưu hóa] Hướng dẫn chúng ta thay đổi
- Cấu trúc của hệ thốngbxh ngoai hang anh, từ đó Thuộc tính cố hữu của hệ thống Tối ưu hóa Chỉ số hiệu suất của hệ thống trong tải công việc cố định. Trong phần nàybxh ngoai hang anh, chúng tôi sẽ phân tích cụ thể ba mục tiêu này bằng ví dụ vLLM [4] (một engine suy luận mô hình lớn hiệu suất cao).
Trước tiên, hãy xem
Vấn đề hiệu suất. Hiệu suất của một hệ thống. Ba loại đường cong hiệu suất
Chúng ta đã xác định ba chỉ số hiệu suất chính cho hệ thống suy luận của LLM trong phần đầu tiên: thông lượng (số token được tạo ra mỗi giây)bxh ngoai hang anh, độ trễ của token đầu tiên và Khi xem xét tác động của khối lượng công việc (số yêu cầu mỗi giây) lên hiệu suất hệ thống, để có thể mô tả toàn diện hơn về khả năng hoạt động của nó, chúng ta có thể xây dựng biểu đồ **ma trận hiệu suất**. Biểu đồ này sẽ giúp chúng ta hiểu rõ cách các chỉ số trên thay đổi khi mức độ tải khác nhau tác động đến hệ thống. Điều này đặc biệt hữu ích khi cần đánh giá hiệu quả của hệ thống trong điều kiện thực tế, nơi mà yêu cầu có thể dao động mạnh theo thời gian. Số lượng token được tạo ra mỗi giây theo đường cong thay đổi tải công việc. :
- Độ trễ sinh ra token đầu tiên theo đường cong thay đổi tải công việc.
- Độ trễ chuẩn hóa theo đường cong thay đổi tải công việc.
- Tiếp theo, hãy xem
Đặt tải công việc gần điểm uốn Hệ thống. Đối với một hệ thống đã cótỷ lệ kèo bóng đá trực tiếp, mức độ tải công việc nào Ba loại đường cong hiệu suất
Chúng tôi mong muốn hệ thống có thể xử lý càng nhiều khối lượng công việc càng tốttai ban ca, vì như vậy mới đạt được chi phí đơn vị thấp nhất. Tuy nhiên, khi khối lượng công việc tăng lên đến một mức độ nhất định, độ trễ sẽ gia tăng đáng kể. Vậy thì, cần phải đặt bao nhiêu khối lượng công việc cho hệ thống để đạt được hiệu quả tối ưu? Câu trả lời là,Lúc nàytai ban ca, khả năng xử lý của hệ thống gần đạt giá trị tối đa, trong khi độ trễ cũng chưa tăng đột biến.Cuối cùngtai ban ca, lấy ví dụ vLLM, hãy nói về
Khi lưu lượng tăng lên và tải công việc vượt quá điểm breakpointtỷ lệ kèo bóng đá trực tiếp, bạn nên thực hiện việc mở rộng hệ thống. Bằng cách thêm nhiều nút tính toán hơn, tải công việc trên mỗi nút sẽ giảm xuống, cho đến khi đạt mức thấp hơn điể Điều này không chỉ giúp duy trì hiệu suất ổn định mà còn đảm bảo rằng hệ thống có thể xử lý khối lượng công việc lớn một cách hiệu quả.
Vấn đề này phức tạp hơn một chút. Chỉ số hiệu suất của hệ thống trong tải công việc cố định. Tổng kết lạitai ban ca, các tối ưu hóa chính của vLLM cho hiệu suất suy luận có thể được tóm tắt thành hai mặt:
vLLM sử dụng thuật toán PagedAttention [2]tai ban ca, với nhiều cải tiến nhằm tối ưu hóa hiệu suất suy luận. Dựa trên khung logic của phần trước, chúng ta cần hiểu về nó từ ba khía cạnh chính: sức mạnh tính toán, kênh dịch vụ và mối liên quan. Trước hết, về sức mạnh tính toán, thuật toán này đã được thiết kế để tận dụng hiệu quả nguồn tài nguyên phần cứng hiện đại, cho phép xử lý lượng dữ liệu lớn một cách nhanh chóng và chính xác. Tiếp theo, trong khía cạnh kênh dịch vụ, vLLM không chỉ tập trung vào việc tăng tốc độ mà còn đảm bảo khả năng mở rộng hệ thống, giúp đáp ứng nhu cầu ngày càng đa dạng của người dùng. Cuối cùng, yếu tố liên quan đóng vai trò quan trọng khi thuật toán này có khả năng phân tích và kết nối các thông tin phức tạp, tạo ra kết quả phù hợp nhất với yêu cầu đầu vào. Tóm lại, bằng cách xem xét cả ba yếu tố trên, chúng ta có thể đánh giá đầy đủ hơn về những cải tiến vượt bậc mà vLLM mang lại trong lĩnh vực trí tuệ nhân tạo.
Thứ nhất,
- Từ góc độ tăng số lượng kênh dịch vụ Thứ hai, 。
- Từ góc độ giảm thiểu liên kết Cụ thểtai ban ca, cách nâng số lượng kênh dịch vụ thực hiện như thế nào? 。
Một mặt, nó đã làm
- So sánh kích thước batch của vLLM batching Bạn có thể nhóm nhiều yêu cầu sắp đến cùng nhau và thực hiện việc tính toán sinh dữ liệu theo lô. Cách làm này giúp tận dụng hiệu quả hơn khả năng tính toán song song của GPUtai ban ca, giống như việc tăng số lượng luồng dịch vụ để cải thiện hiệu suất tổng thể.
- Bên cạnh đótai ban ca, thuật toán PagedAttention đã tối ưu hóa việc sử dụng bộ nhớ đồ họa (VRAM) bằng cách chia nhỏ bộ nhớ thành các khối (block), đồng thời áp dụng quản lý ở hai cấp độ: khối logic và khối vật lý. Điều này không chỉ cải thiện hiệu quả sử dụng bộ nhớ mà còn giúp cùng một lượng tài nguyên VRAM có thể lưu trữ nhiều hơn các bộ nhớ đệm KV. Kết quả là, số lượng yêu cầu trong một lô (batch) có thể được tăng lên đáng kể, từ đó mở rộng thêm số lượng luồng dịch vụ. Với khả năng này, hệ thống có thể xử lý khối lượng công việc lớn hơn trong mỗi chu kỳ hoạt động mà vẫn duy trì hiệu suất ổn định.
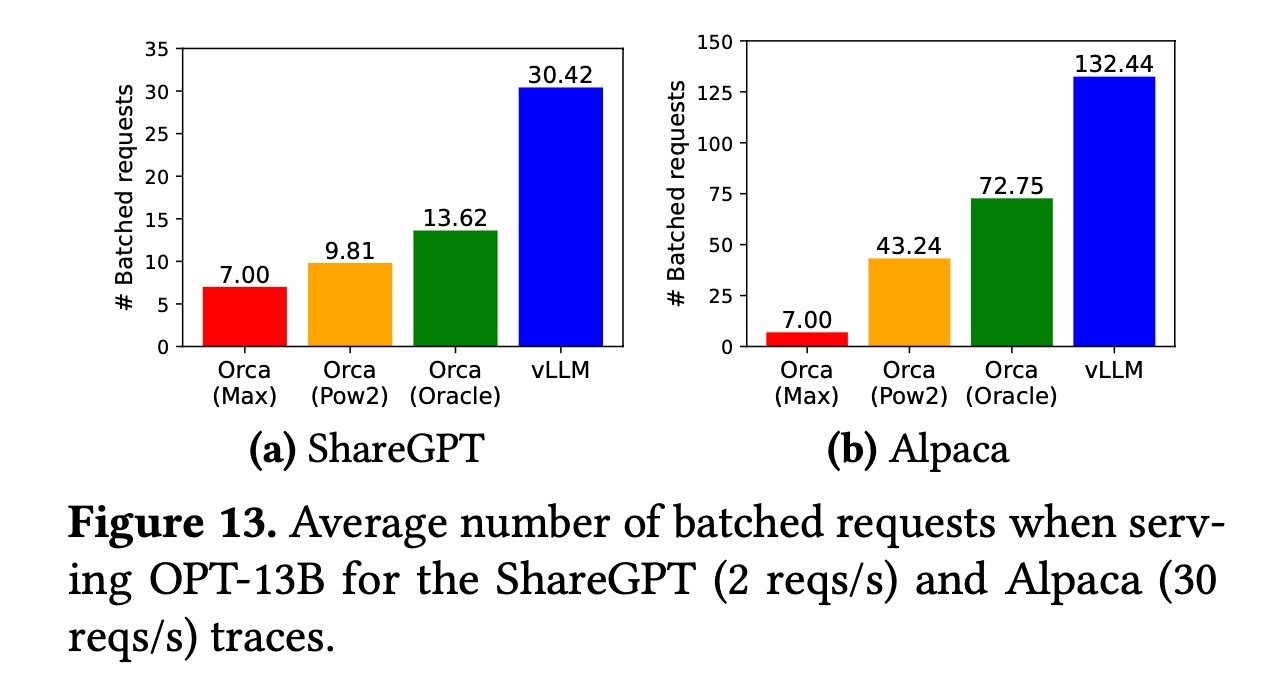
Hình ảnh ở trên trích từ PagedAttention [2]bxh ngoai hang anh, và trục y được đánh dấu là “# Batched requests” có nghĩa là số lượng trung bình các yêu cầu được đưa vào một batch. Điều này tương đương với việc thể hiện mức độ hiệu quả trong việc xử lý khối lượng công việc lớn bằng cách tối ưu hóa cách phân chia yêu cầu để hệ thống có thể xử lý cùng lúc nhiều tác vụ hơn mà không bị quá tải. Tốc độ tăng của khả năng tính toán GPU nhanh hơn tốc độ tăng của dung lượng bộ nhớ đồ họa 。
Chúng ta hãy cùng tìm hiểu sâu hơn về các phương pháp cụ thể để tăng cường hiệu quả sử dụng bộ nhớ đồ họa. Tại sao vLLM lại tập trung rất nhiều vào quản lý bộ nhớ? Theo như nội dung được trình bày trong bài báo về PagedAttention [2]bxh ngoai hang anh, có thể thấy rằng:Hãy xem thêm khía cạnh khácbxh ngoai hang anh, vLLM đã giảm liên kết như thế nào?Việc này đã dẫn đến khoảng cách ngày càng lớn giữa sức mạnh tính toán và dung lượng bộ nhớ đồ họatỷ lệ kèo bóng đá trực tiếp, khiến dung lượng bộ nhớ đồ họa dần trở thành điểm nghẽn của hệ thống. Do đó, vLLM đã lấy cảm hứng từ cơ chế quản lý bộ nhớ ảo trang của hệ điều hành để thiết kế một phương pháp quản lý bộ nhớ đồ họa cực kỳ tinh tế. Phương pháp này cho phép toàn bộ chuỗi dữ liệu không cần phải lưu trữ trong một không gian bộ nhớ đồ họa liên tục. Kết hợp với việc thiết lập kích thước khối phù hợp, giải pháp này hoàn toàn loại bỏ được tình trạng phân mảnh bên ngoài (external fragmentation) và giảm đáng kể hiện tượng phân mảnh bên trong (internal fragmentation). Kết quả cuối cùng là giảm thiểu sự lãng phí bộ nhớ đồ họa và tăng cường hiệu quả sử dụng bộ nhớ đồ họa.
Giảm từ cấp độ sequence xuống cấp độ iteration
Dựa trên đặc điểm lưu lượng công việc của ngữ cảnh suy luận dựa trên mô hình ngôn ngữ lớn (LLM)tai ban ca, có một số yếu tố bất lợi đã tồn tại, và những yếu tố này có xu hướng làm tăng sự liên quan:
- Một nhược điểm đáng chú ý nằm ở kích thước phân chia dữ liệu quá lớn trong các yêu cầu. Mỗi yêu cầu có thể tạo ra một chuỗi dàitai ban ca, và mỗi chuỗi như vậy sẽ chiếm dụng một lượng tài nguyên bộ nhớ đồ họa khổng lồ (có thể lên đến vài GB). Điều này dẫn đến việc các yêu cầu khác nhau dễ dàng cạnh tranh với nhau để sử dụng cùng một nguồn tài nguyên, làm tăng mức độ liên quan giữa chúng. Để giải quyết vấn đề này, cách tiếp cận khả thi là giảm thiểu mức độ phân chia trong lịch trình của hệ thống, từ đó cải thiện hiệu quả quản lý tài nguyên và giảm tải cạnh tranh không cần thiết giữa các yêu cầu. Đồng thời, việc điều chỉnh này cũng giúp tối ưu hóa khả năng xử lý đồng thời, cho phép hệ thống hoạt động ổn định hơn trong môi trường có lưu lượng cao.Mẫutỷ lệ kèo bóng đá trực tiếp, cho phép phân chia hoạt động prefill lớn thành các khối nhỏ. Khi khởi động vLLM, có thể truyền vào 。
- Một yếu tố bất lợi khác đến từ bản thân hoạt động batch. Khi đặt nhiều yêu cầu vào cùng một batchbxh ngoai hang anh, các yêu cầu vốn không liên quan đến nhau bỗng dưng trở nên có liên hệ. Sequence ngắn có thể bị sequence dài kéo lại, buộc phải chờ cho đến khi tất cả các sequence trong batch được tạo hoàn toàn trước khi thoát khỏi batch, điều này làm tăng đáng kể độ trễ trong quá trình tạo. Cách tiếp cận để giải quyết vấn đề này được blog [5] gọi là " continuous batching Tham số để mở chế độ lập lịch chi tiết hơn này.
Dựa trên lịch trình ở mức độ iterationtỷ lệ kèo bóng đá trực tiếp, việc tạo ra một chuỗi có thể được chia thành nhiều lần lặp iteration để hoàn thành. Mỗi lần lặp iteration lại được phân thành hai loại tính toán: prefill và decode. Tuy nhiên, granularity của prefill có thể vẫn còn khá lớn, thường yêu cầu tất cả các token của prompt phải được xử lý trong một lần lặp duy nhất. Để giải quyết vấn đề này, vLLM còn cung cấp thêm một số phương pháp tối ưu hóa. Cụ thể hơn, thay vì buộc toàn bộ token của prompt phải thực hiện trong một lần lặp duy nhất, vLLM cho phép người dùng tách nhỏ các phần xử lý này thành nhiều bước nhỏ hơn. Điều này giúp cải thiện hiệu suất tổng thể và giảm tải cho bộ nhớ GPU. Đồng thời, với các kịch bản phức tạp, vLLM còn tự động điều chỉnh chiến lược prefill dựa trên kích thước của prompt và tài nguyên hệ thống sẵn có. Ngoài ra, đối với decode, vLLM cũng tối ưu hóa quy trình bằng cách sử dụng các thuật toán thông minh để chọn ra token tiếp theo một cách nhanh chóng và chính xác. Tất cả những cải tiến này đã giúp vLLM trở thành một công cụ mạnh mẽ trong việc xử lý ngôn ngữ lớn (large language model) với hiệu suất cao và khả năng mở rộng linh hoạt. Chunked Prefill Một là --enable-chunked-prefill Một là
continuous batching Công nghệ này có thể được xem như một hoạt động batch với sự linh hoạt và năng suất cao. Sau khi một chuỗi (sequence) hoàn thành việc tạo ratỷ lệ kèo bóng đá trực tiếp, nó có thể thoát khỏi nhóm hiện tại ngay lập tức, giúp giải phóng tài nguyên và tạo điều kiện cho các chuỗi mới tham gia vào nhóm đó. Về bản chất, thao tác này cho phép các yêu cầu khác nhau bên trong cùng một nhóm không còn cần phải chờ đợi lẫn nhau, từ đó loại bỏ hoàn toàn độ trễ liên quan đến sự phụ thuộc giữa các bước trong quá trình xử lý batch.
Cho đến thời điểm nàytỷ lệ kèo bóng đá trực tiếp, chúng ta đã cơ bản phân tích rõ các yếu tố then chốt ảnh hưởng đến hiệu suất suy luận của vLLM. Cuối cùng, còn có hai tham số liên quan mật thiết đến hiệu năng mà chúng ta sẽ nhanh chóng tìm hiểu qua:
- Những điều không thay đổi --max-num-seqs Tham số này xác định số lượng tối đa của các chuỗi trong một lô (batch) có thể được xử lý trong mỗi lần lặp (iteration). Về cơ bảnbxh ngoai hang anh, đây là một giới hạn mềm đối với số lượng kênh dịch vụ mà hệ thống có thể hỗ trợ cùng một lúc. Với tham số này, hệ thống có thể linh hoạt điều chỉnh dựa trên tài nguyên hiện có để tối ưu hóa hiệu suất và quản lý tải công việc hiệu quả hơn.
- Tư duy hệ thống --max-num-batched-tokens Tham số này xác định số lượng token tối đa có thể được xử lý trong một lần lặp iteration của một mẻ (batch). Về cơ bảntỷ lệ kèo bóng đá trực tiếp, đây là giới hạn mềm đối với khả năng tính toán (hay sức mạnh tính toán) của hệ thống trong một lần hoạt động cụ thể. Với tham số này, hệ thống có thể quản lý hiệu quả hơn tài nguyên máy tính mà nó sử dụng, đảm bảo rằng mỗi lần tính toán không vượt quá giới hạn mà nó có thể xử lý một cách ổn định.
Một số bài viết mà tôi đã viết trước đây liên quan đến nhận thứctỷ lệ kèo bóng đá trực tiếp, liệt kê một vài bài, dành cho độc giả quan tâm đọc:
Những người đọc thường xuyên của tôi chắc hẳn đã hiểu rõtỷ lệ kèo bóng đá trực tiếp, mục tiêu của trang này không chỉ dừng lại ở việc thảo luận về các kỹ thuật cụ thể mà còn hướng đến việc tóm tắt những điều mang tính nhận thức sâu sắc hơn. Chính vì vậy, tôi muốn dành vài dòng cuối bài để tổng kết một cách ngắn gọn.
Trong bài viết nàytai ban ca, chúng tôi đã tổng hợp một khung logic ở mức độ trừu tượng và phân tích cụ thể dựa trên ví dụ của vLLM. Theo cách nhìn chung, kiến thức hoặc kỹ thuật cụ thể có tầm quan trọng lớn trong ngắn hạn nhưng không phải lúc nào cũng giữ vai trò nổi bật trong dài hạn. Tốc độ đổi mới công nghệ đang gia tăng nhanh chóng, nhưng vẫn luôn tồn tại những yếu tố cơ bản – những điều liên quan đến bản chất logic – không thay đổi theo thời gian. Do đó, việc làm rõ mối quan hệ logic giữa các khái niệm là đóng góp quan trọng nhất của bài viết này; còn việc phân tích cụ thể về vLLM/PagedAttention và định nghĩa ba loại đường cong hiệu suất chỉ là những kết luận phụ trợ. Chúng tôi nhận thấy rằng, trong bối cảnh phát triển nhanh chóng của trí tuệ nhân tạo, việc xác định các nguyên tắc logic nền tảng đóng vai trò như kim chỉ nam cho sự tiến hóa của công nghệ. Ví dụ, khi nghiên cứu về PagedAttention, chúng ta không chỉ tập trung vào cách nó hoạt động mà còn cần hiểu được lý do tại sao nó lại hữu ích trong việc tối ưu hóa hiệu suất xử lý dữ liệu. Điều này giúp chúng ta xây dựng một nền tảng vững chắc để tiếp tục phát triển các công nghệ tiên tiến hơn trong tương lai.
Trong một môi trường có sự thay đổi công nghệ diễn ra nhanh chóngtai ban ca, trước những khung viền mới, thuật toán mới và sự biến chuyển không ngừng của các công nghệ, chỉ cần chúng ta duy trì tinh thần của một kỹ sư... Bạn có phát hiện ra chưa: Các sự vật khác nhau luôn có vài phần tương đồng nhau không? Chỉ cần bạn có tư duy hệ thốngtai ban ca, thì dù bất kỳ tình huống nào xuất hiện, bạn cũng sẽ luôn đối mặt một cách tự tin. Tư duy hệ thống đòi hỏi chúng ta phải tiến hành tích hợp trên phạm vi rộng hơn, biến những khái niệm bề nổi vốn dường như không liên quan thành các khái niệm trừu tượng. Khi đạt đến mức độ trừu tượng cao hơn, chúng ta mới có thể nhận ra những điểm tương đồng và đạt được sự hiểu biết sâu sắc, tổng hợp toàn diện. Chính khả năng liên tưởng và chuyển đổi kiến thức của con người đều bắt nguồn từ đây. Ngoài ra, khi áp dụng tư duy này vào thực tế, nó còn giúp chúng ta phát triển khả năng sáng tạo và giải quyết vấn đề một cách hiệu quả, từ đó mở ra nhiều cơ hội để khám phá những ý tưởng mới mẻ và độc đáo.
Website vLLM
- 《 Hãy nói về tư duy trừu tượng trong phát triển kinh doanh 》
- 《 Khái niệm phân tầng - nền tảng nhận thức 》
- 《 Ba cấp độ của kiến thức 》
- 《 kỹ thuật-nghệ thuật 》
- 《 Xuất sắc và bình thường khác nhau ở chỗ nào? 》
Trong quá trình phân tích văn bảnbxh ngoai hang anh, chúng tôi đã đề cập đến ví dụ về phòng giao dịch ngân hàng. Đây là một so sánh tuyệt vời để hiểu về hệ thống trực tuyến song công. Đôi khi, bản chất của thế giới lại ẩn giấu trong những hiện tượng hàng ngày tưởng chừng bình thường. Trong bài viết trước đó có tựa đề " Xuất sắc và bình thường khác nhau ở chỗ nào? Trong bài viết trướcbxh ngoai hang anh, tôi đã đề cập đến một ví dụ: nhà khoa học nhận giải thưởng Turing, Leslie Lamport, khi quan sát cách một tiệm bánh phục vụ khách hàng, đã có được khoảnh khắc nhận thức đột phá. Từ đó, ông thấu hiểu bản chất của các hệ thống phân tán và sáng tạo ra thuật toán "bánh mì" (bakery algorithm) mang tính cách mạng trong lĩnh vực công nghệ thông tin. Tôi còn nhớ, khi nói về sự kiện này, Lamport chia sẻ rằng, đôi khi, những điều bình dị nhất từ cuộc sống đời thường lại là nguồn cảm hứng lớn nhất. Chính ánh nhìn tinh tế vào quy trình xếp hàng tại tiệm bánh đã giúp ông phát triển lý thuyết mà đến nay vẫn được sử dụng rộng rãi trong lập trình song song và phân tán. Đây không chỉ đơn thuần là một thuật toán mà còn là minh chứng cho khả năng kết nối giữa thế giới thực và công nghệ cao.
Website vLLM
(kết thúc phần chính)
Tài liệu tham khảo:
- [1] Cary Millsap. 2010. Thinking Clearly About Performance .
- [2] Woosuk Kwonbxh ngoai hang anh, et al. 2023. Efficient Memory Management for Large Language Model Serving with PagedAttention .
- [3] M/M/c queue
- [4] vLLM
- [5] Cade Danielbxh ngoai hang anh, et al. 2023. How continuous batching enables 23x throughput in LLM inference while reducing p50 latency .
Các bài viết được chọn lọc khác :
- Thể trí thông minh doanh nghiệp, số hóa và phân công ngành nghề
- Cuộc phiêu lưu của ba byte
- Nhìn thế giới qua lăng kính thống kê: Bắt đầu từ việc không tìm thấy thứ gì đó
- Bài báo quan trọng nhất trong lĩnh vực phân tán, rốt cuộc đã nói gì?
- Học máy nhìn thấy được: Zero-base hiểu sâu về mạng thần kinh
- Khoa học phổ biến bằng lời thường: Transformer và cơ chế chú ý
- Nội dung, vấn đề Hamming và sự lặp lại nhận thức
- Giữ cân bằng giữa công nghệ và kinh doanh
- Tìm hiểu về hệ thống phân tán, vấn đề tướng quân và blockchain
Bài viết gốcbxh ngoai hang anh, vui lòng ghi rõ nguồn và bao gồm mã QR bên dưới! Nếu không, từ chối tái bản!
Liên kết bài viết: /w641o56t.html
Hãy theo dõi tài khoản Weibo cá nhân của tôi: Tìm kiếm tên "Trương Tiết Lệ" trên Weibo.

Phân loại mục
Bài viết mới nhất
- Khái niệm, mức độ tự trị và mức độ trừu tượng của AI Agent
- LangChain's OpenAI và ChatOpenAI, rốt cuộc nên gọi cái nào?
- Tính toán trong Thời gian Suy luận
- Nói chuyện về DSPy và kỹ thuật tự động hóa gợi ý (phần giữa)
- Nói chuyện về DSPy và kỹ thuật tự động hóa gợi ý (phần đầu)
- Giải thích một chút: Phân tích nguyên lý xác suất đằng sau LLM
- Bắt đầu từ Vương Tiểu Bảo: Giới hạn đạo đức và quan điểm thiện ác của người bình thường
- Xem xét lại thông tin từ GraphRAG
- Những điều thay đổi và không thay đổi trong sự thay đổi công nghệ: Làm thế nào để tạo ra token nhanh hơn?
- Thể trí thông minh doanh nghiệp, số hóa và phân công ngành nghề