Phân tích sâu cấu trúc dữ liệu nội bộ của Redis (2) —— sds
2016-06-05
Phân tích cấu trúc dữ liệu nội bộ của Redis Phân tích cấu trúc dữ liệu nội bộ của Redis Bài viết thứ hai trong loạt bài này99win club, sẽ nói về cấu trúc dữ liệu cơ bản được sử dụng nhiều nhất trong Redis: sds.
Dù trong bất kỳ ngôn ngữ lập trình nào99win club, chuỗi (string) cũng luôn là một trong những cấu trúc dữ liệu được sử dụng phổ biến nhất. Ở Redis, sds (Simple Dynamic String) chính là phiên bản chuỗi được áp dụng rộng rãi. Tên đầy đủ của nó là So với các loại chuỗi trong môi trường lập trình khác, sds có những đặc điểm nổi bật sau đây: Trước hết, sds không chỉ đơn thuần là một chuỗi cố định mà còn có khả năng mở rộng linh hoạt dựa trên nhu cầu lưu trữ. Điều này giúp tối ưu hóa bộ nhớ và cải thiện hiệu suất khi làm việc với các dữ liệu thay đổi kích thước liên tục. Hơn nữa, sds tích hợp sẵn các phương thức quản lý bộ nhớ thông minh, cho phép tự động điều chỉnh kích thước khi cần thêm hoặc xóa dữ liệu. Thứ hai, sds cung cấp khả năng tương thích cao với nhiều loại mã hóa khác nhau, từ UTF-8 đến Latin1. Điều này đảm bảo rằng mọi ký tự đặc biệt hoặc đa byte đều có thể được xử lý một cách chính xác và an toà Cuối cùng, sds mang lại sự ổn định và hiệu quả trong quá trình truy xuất dữ liệu nhờ cơ chế tối ưu hóa bộ đệm và giảm thiểu sự gián đoạn khi thực hiện thao tác với chuỗi. Điều này đặc biệt hữu ích trong các ứng dụng đòi hỏi tốc độ xử lý cao và khả năng mở rộng lớn.
- Bộ nhớ có thể mở rộng linh hoạt. Chuỗi được biểu diễn bởi SDS cho phép chỉnh sửa nội dung cũng như thêm phần tử mới. Trong nhiều ngôn ngữ lập trìnhkeo 88, chuỗi thường được chia thành hai loại: mutable (có thể thay đổi) và immutable (không thể thay đổi). Rõ ràng, SDS thuộc nhóm mutable, mang đến sự linh hoạt cao trong việc xử lý dữ liệu. Điều này đặc biệt hữu ích khi bạn cần cập nhật hoặc mở rộng chuỗi một cách nhanh chóng mà không gặp bất kỳ giới hạn nào.
- Dữ liệu nhị phân an toàn (Binary Safe). SDS có khả năng lưu trữ bất kỳ dữ liệu nhị phân nàotỷ lệ kèo bóng đá trực tiếp, không chỉ giới hạn ở các ký tự in được. Điều này làm cho SDS trở nên linh hoạt hơn trong việc xử lý nhiều loại dữ liệu phức tạp mà không gặp phải bất kỳ sự giới hạn nào về dạng nội dung.
- Tương thích với kiểu chuỗi truyền thống của ngôn ngữ C. Ý nghĩa của điều này sẽ được thảo luận ngay sau đây.
Khi đọc đến đâytỷ lệ kèo bóng đá trực tiếp, nhiều bạn đã quen thuộc với Redis có thể đã đặt ra một câu hỏi: Redis đã cung cấp một cấu trúc dữ liệu chuỗi gọi là string, vậy sds được đề cập ở đây và string có mối liên hệ gì với nhau? Có người có thể đoán rằng string được xây dựng dựa trên sds. Giả thuyết này đã rất gần với sự thật, nhưng vẫn chưa hoàn toàn chính xác trong cách diễn đạt. Về mối liên hệ chi tiết giữa string và sds, chúng ta sẽ bàn luận sâu hơn ở phần sau. Hiện tại, để tiện cho việc thảo luận, hãy tạm thời hiểu đơn giản rằng thực hiện cơ bản của string là sds. Có lẽ bạn đang tự hỏi tại sao lại có hai cấu trúc dữ liệu giống nhau như vậy? Điều này xuất phát từ nhu cầu khác nhau trong việc quản lý bộ nhớ và hiệu suất. String trong Redis được thiết kế để dễ sử dụng và linh hoạt hơn, trong khi sds lại tập trung vào việc tối ưu hóa hiệu suất và giảm thiểu rủi ro về bộ nhớ. Hai cấu trúc này bổ sung cho nhau thay vì mâu thuẫn với nhau, giúp Redis trở nên mạnh mẽ và đa năng hơn trong việc xử lý dữ liệu.
Xin chào Thế giới

Tất cả các thao tác này đều rất đơn giản99win club, chúng ta sẽ giải thích sơ lược một chút:
- Giá trị ban đầu của chuỗi được đặt thành "tielei".
- Bước thứ ba đã sử dụng lệnh append để thêm chuỗi vào sautỷ lệ kèo bóng đá trực tiếp, biến đổi thành "tielei zhang".
- Sau đó99win club, bạn sử dụng lệnh setbit để đặt bit thứ 53 thành giá trị 1. Quy ước của bit offset bắt đầu từ bên trái và đánh số từ 0. Trong đó, các bit từ 48 đến 55 tượng trưng cho ký tự khoảng trắng, có mã ASCII là 0x20. Khi bạn đặt bit thứ 53 thành 1, mã ASCII của nó sẽ thay đổi thành 0x24, khi hiển thị sẽ là ký tự ‘$’. Do đó, chuỗi hiện tại đã thay đổi thành “tielei$zhang”.
- Cuối cùng99win club, bằng cách sử dụng getrange để lấy phần tử từ vị trí thứ 5 tính từ cuối cùng cho đến vị trí cuối cùng, bạn sẽ nhận được chuỗi "zhang".
Việc thực hiện các lệnh này có một phần liên quan đến việc triển khai của sds. Bây giờ chúng ta bắt đầu phân tích chi tiết.
Định nghĩa cấu trúc dữ liệu sds
Chúng ta đều biết rằng trong ngôn ngữ lập trình C99win club, chuỗi ký tự được lưu trữ dưới dạng mảng ký tự kết thúc bằng ký tự '\0' (ký hiệu kết thúc chuỗi). Chúng thường được biểu diễn dưới dạng con trỏ ký tự (char *). Tuy nhiên, do không cho phép xuất hiện byte 0 ở giữa chuỗi, nên định dạng này không thể dùng để lưu trữ bất kỳ dữ liệu nhị phân nào một cách trực tiếp. Điều này đặt ra giới hạn nhất định khi xử lý các loại dữ liệu phức tạp hoặc dữ liệu thô mà có thể chứa các giá trị đặc biệt như byte 0.
Chúng ta có thể tìm thấy định nghĩa kiểu sds trong tệp sds.h:
typedef
char
*
sds
;
Chắc chắn đã có người cảm thấy bối rối rồikeo 88, liệu sds có thực sự giống với char * hay không? Chúng ta đã từng đề cập trước đây rằng sds và chuỗi C truyền thống có tính tương thích về kiểu dữ liệu, do đó cách định nghĩa kiểu của chúng là như nhau, đều là char *. Trong một số trường hợp nhất định, khi cần truyền vào một chuỗi C, bạn thực sự cũng có thể truyền một sds. Tuy nhiên, sds và char * không phải là hoàn toàn giống nhau. SDS được thiết kế để an toàn cho dữ liệu nhị phân (Binary Safe), nó có thể lưu trữ bất kỳ dữ liệu nhị phân nào, khác với chuỗi C mà chỉ kết thúc bằng ký tự '\0'. Do đó, sds chắc chắn phải có một trường độ dài. Nhưng trường độ dài này nằm ở đâu? Thực tế, sds còn chứa một cấu trúc header:
struct
__attribute__
((
__packed__
))
sdshdr5
{
unsigned
char
flags
;
/* 3 lsb of typekeo 88, and 5 msb of string length */
char
buf
[];
};
struct
__attribute__
((
__packed__
))
sdshdr8
{
uint8_t
len
;
/* used */
uint8_t
alloc
;
/* excluding the header and null terminator */
unsigned
char
flags
;
/* 3 lsb of typekeo 88, 5 unused bits */
char
buf
[];
};
struct
__attribute__
((
__packed__
))
sdshdr16
{
uint16_t
len
;
/* used */
uint16_t
alloc
;
/* excluding the header and null terminator */
unsigned
char
flags
;
/* 3 lsb of typekeo 88, 5 unused bits */
char
buf
[];
};
struct
__attribute__
((
__packed__
))
sdshdr32
{
uint32_t
len
;
/* used */
uint32_t
alloc
;
/* excluding the header and null terminator */
unsigned
char
flags
;
/* 3 lsb of typetỷ lệ kèo bóng đá trực tiếp, 5 unused bits */
char
buf
[];
};
struct
__attribute__
((
__packed__
))
sdshdr64
{
uint64_t
len
;
/* used */
uint64_t
alloc
;
/* excluding the header and null terminator */
unsigned
char
flags
;
/* 3 lsb of typekeo 88, 5 unused bits */
char
buf
[];
};
Sds (Simple Dynamic String) có tất cả 5 loại header khác nhau. Lý do có đến 5 loại header là để các chuỗi với độ dài khác nhau có thể sử dụng kích thước header phù hợp. Điều này cho phép chuỗi ngắn chỉ cần dùng header nhỏ hơntỷ lệ kèo bóng đá trực tiếp, từ đó tối ưu hóa việc sử dụng bộ nhớ và giảm thiểu tài nguyên cần thiết.
Một chuỗi sds đầy đủ có cấu trúc hoàn chỉnhtỷ lệ kèo bóng đá trực tiếp, bao gồm hai phần liền kề nhau trong địa chỉ bộ nhớ:
- Một tiêu đề (header). Thông thườngkeo 88, nó bao gồm độ dài của chuỗi (len), dung lượng tối đa (alloc) và cờ hiệu (flags). Tuy nhiên, đối với sdshdr5, có một số điểm khác biệt.
- Một mảng ký tự. Độ dài của mảng này bằng với dung lượng tối đa cộng thêm một. Phần chuỗi thực sựkeo 88, thông thường, sẽ có độ dài nhỏ hơn dung lượng tối đa. Sau dữ liệu chuỗi thực tế, là những byte trống chưa được sử dụng (thường được lấp đầy bằng byte 0), cho phép mở rộng chuỗi một cách giới hạn mà không cần phân bổ lại bộ nhớ. Ngay sau phần dữ liệu chuỗi thực tế, còn tồn tại một ký tự kết thúc NULL, tức ký tự có mã ASCII là 0 ('\\0'). Điều này nhằm đảm bảo tương thích với các chuỗi C truyền thống. Lý do mà mảng ký tự có độ dài lớn hơn dung lượng tối đa một byte, chính là để khi độ dài chuỗi đạt đến mức tối đa vẫn còn đủ chỗ để lưu ký tự kết thúc NULL.
Ngoài sdshdr5 ra99win club, các header khác đều chứa ba trường:
- len: cho biết độ dài thực tế của chuỗi (không bao gồm ký tự kết thúc NULL).
- alloc: cho biết dung lượng tối đa của chuỗi (không bao gồm byte dư thừa cuối cùng).
- Trong cấu trúc flags99win club, luôn luôn chiếm một byte bộ nhớ. Trong đó, 3 bit thấp nhất được sử dụng để biểu thị loại của header. Header có tổng cộng 5 loại khác nhau và các giá trị hằng số tương ứng đã được định nghĩa rõ trong tệp sds.h. Mỗi loại header đều có vai trò quan trọng trong việc quản lý dữ liệu, từ việc xác định kiểu đến việc xử lý nội dung bên trong, tất cả đều phụ thuộc vào giá trị của flag này.
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
Chúng ta cần phân tích cẩn thận cấu trúc dữ liệu sds.
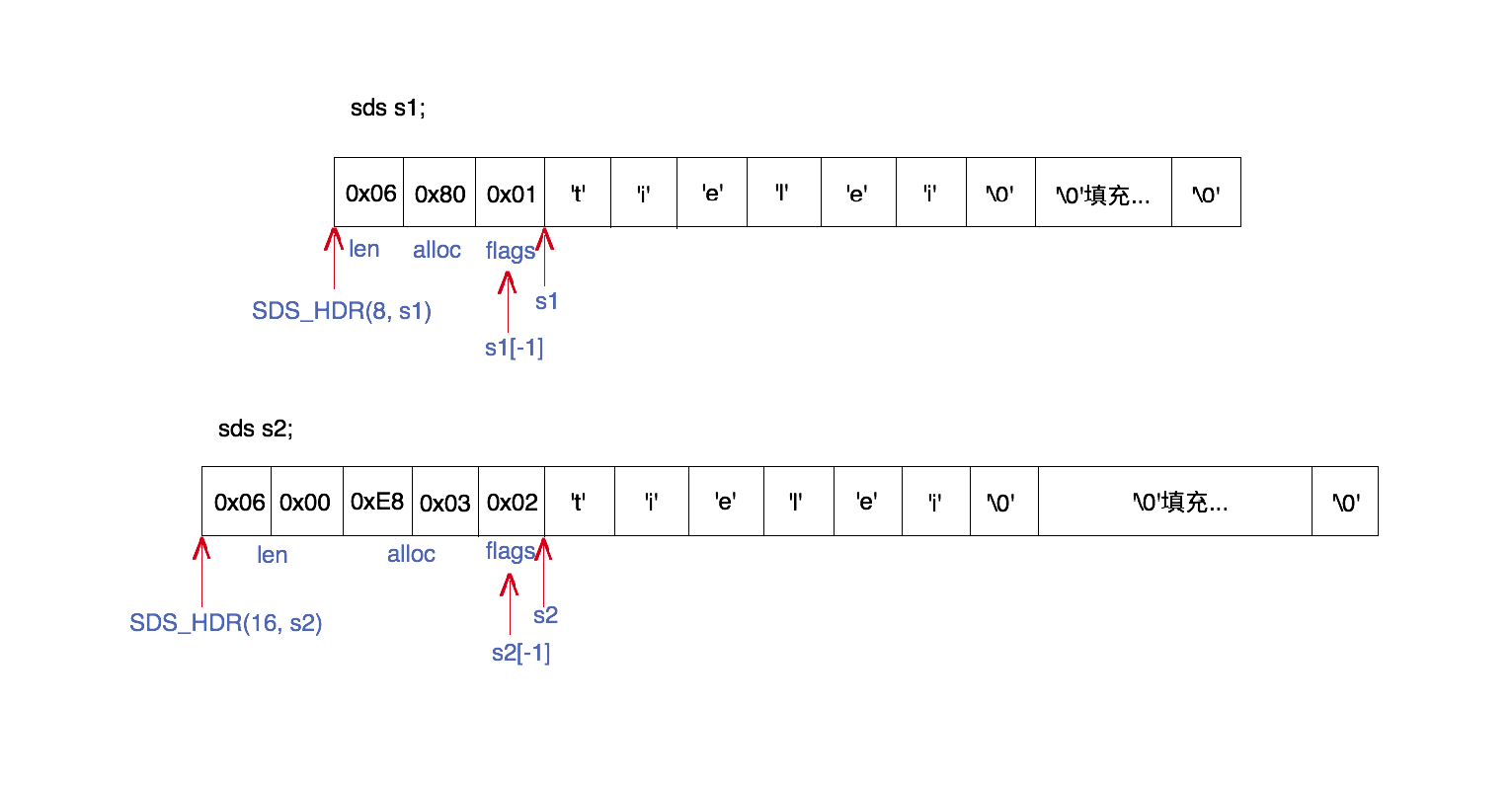
Hình ảnh phía trên là một ví dụ về cấu trúc nội bộ của SDS. Trong hìnhtỷ lệ kèo bóng đá trực tiếp, chúng ta có thể thấy cấu trúc bộ nhớ của hai chuỗi SDS được đặt tên là s1 và s2. Trong đó, một chuỗi sử dụng header kiểu sdshdr8, trong khi chuỗi kia sử dụng header kiểu sdshdr16. Tuy nhiên, cả hai đều biểu diễn cùng một giá trị chuỗi có độ dài 6: "tielei". Tiếp theo, chúng ta sẽ đi sâu vào phân tích từng phần của mã nguồn để hiểu rõ hơn về cách thức hoạt động của các thành phần này. Trước tiên, hãy cùng tìm hiểu khái niệm cơ bản về việc quản lý bộ nhớ Khi tạo ra một chuỗi mới, SDS cần phải xác định kích thước phù hợp cho header để lưu trữ thông tin về chiều dài của chuỗi. Header kiểu sdshdr8 chỉ đủ sức lưu trữ các chuỗi có chiều dài tối đa 255 byte (2^8 - 1), trong khi header sdshdr16 hỗ trợ đến 65535 byte (2^16 - 1). Điều này giúp SDS linh hoạt hơn trong việc xử lý các trường hợp khác nhau liên quan đến kích thước dữ liệu. Tiếp theo, hãy xem xét cách mà chuỗi "tielei" được lưu trữ trong từng loại header. Đối với header sdshdr8, phần đầu tiên của vùng nhớ sẽ chứa giá trị 6 - đại diện cho chiều dài của chuỗi. Ngay sau đó là vùng dữ liệu thực sự của chuỗi, nơi chứa các ký tự 't', 'i', 'e', 'l', 'e', 'i'. Với header sdshdr16, quy trình tương tự cũng diễn ra, nhưng header này có thêm không gian dự phòng để hỗ trợ các chuỗi lớn hơn. Bây giờ, hãy nhìn vào mã nguồn cụ thể để hiểu rõ hơn về cách SDS hoạt động. Đầu tiên, khi một chuỗi mới được tạo, hàm `sdsnew` hoặc `sdsempty` sẽ được gọi để khởi tạo một đối tượng SDS với header phù hợp. Nếu chiều dài của chuỗi nằm trong phạm vi cho phép của sdshdr8, thì header này sẽ được chọn; nếu vượt quá giới hạn, SDS sẽ tự động nâng cấp lên sdshdr16. Điều này giúp tối ưu hóa hiệu suất và giảm thiểu lãng phí tài nguyên. Cuối cùng, chúng ta có thể thấy rằng SDS không chỉ đơn giản là một công cụ quản lý chuỗi, mà còn là một hệ thống thông minh có khả năng tự điều chỉnh dựa trên yêu cầu thực tế. Bằng cách sử dụng các header khác nhau tùy thuộc vào kích thước của chuỗi, SDS có thể cung cấp hiệu suất tốt nhất cho mọi tình huống, từ các chuỗi ngắn gọn đến các chuỗi phức tạp với độ dài lớn hơn nhiều.
Trong sdstỷ lệ kèo bóng đá trực tiếp, con trỏ ký tự (như s1 và s2) chính là nơi mà dữ liệu thực tế (mảng ký tự) được bắt đầu, trong khi phần header lại nằm ở hướng địa chỉ bộ nhớ thấp hơn. Trong tệp sds.h, có một số macro định nghĩa liên quan đến việc phân tích phần header này, giúp người dùng có thể dễ dàng thao tác với cấu trúc dữ liệu của sds mà không cần phải trực tiếp làm việc với các giá trị bộ nhớ thô. Điều thú vị là mỗi khi bạn tạo ra một chuỗi sds mới, hệ thống sẽ tự động thêm vào một phần header nhỏ để lưu trữ thông tin về độ dài của chuỗi, dung lượng tối đa, cũng như các cờ hiệu ứng đặc biệt. Điều này cho phép sds hoạt động nhanh chóng và linh hoạt trong nhiều tình huống khác nhau. Nhờ có nhữ h, lập trình viên có thể dễ dàng truy cập vào các thông tin quan trọng này mà không cần phải viết thêm nhiều dòng mã phức tạp.
#define SDS_TYPE_MASK 7
#define SDS_TYPE_BITS 3
#define SDS_HDR_VAR(T99win club,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T)));
#define SDS_HDR(T,s) ((struct sdshdr##T *)((s)-(sizeof(struct sdshdr##T))))
#define SDS_TYPE_5_LEN(f) ((f)>>SDS_TYPE_BITS)
Trong đótỷ lệ kèo bóng đá trực tiếp, SDS_HDR được sử dụng để lấy vị trí con trỏ bắt đầu của phần header từ chuỗi sds. Ví dụ như SDS_HDR(8, s1) sẽ biểu thị con trỏ header của s1, còn SDS_HDR(16, s2) sẽ đại diện cho con trỏ header của s2. Điều này giúp người dùng dễ dàng thao tác và truy xuất thông tin header một cách nhanh chóng và chính xác trong các cấu trúc dữ liệu sds.
Trước khi sử dụng SDS_HDRkeo 88, chúng ta cần xác định chính xác loại header mà nó đang đề cập đến. Điều này giúp chúng ta biết tham số đầu tiên của SDS_HDR nên được truyền vào với giá trị nào. Cách để lấy thông tin về loại header từ con trỏ chuỗi sds là di chuyển về hướng địa chỉ thấp hơn một byte để lấy giá trị của trường flags. Ví dụ, bằng cách sử dụng s1[-1] và s2[-1], chúng ta có thể lấy giá trị flags của s1 và s2. Sau đó, từ giá trị flags, chúng ta lấy 3 bit thấp nhất để xác định loại header. Những bước đơn giản này đảm bảo rằng việc sử dụng SDS_HDR sẽ đúng với mục đích và tránh được các lỗi không đáng có trong quá trình xử lý.
- Vì giá trị s1[-1] là 0x01 và nó khớp với định nghĩa của SDS_TYPE_899win club, nên có thể xác định rằng kiểu header của s1 là sdshdr8. Điều này cho thấy cấu trúc dữ liệu được mã hóa theo loại sdshdr8, giúp tối ưu hóa việc quản lý bộ nhớ cho chuỗi có độ dài vừa phải trong hệ thống.
- Vì s2[-1] có giá trị là 0x02 và 0x02 này trùng với định danh SDS_TYPE_16tỷ lệ kèo bóng đá trực tiếp, nên có thể khẳng định rằng kiểu header của s2 là sdshdr16. Điều này cho thấy dữ liệu trong s2 được mã hóa theo cấu trúc sdshdr16, giúp xác định kích thước và nội dung của chuỗi một cách hiệu quả trong hệ thống quản lý bộ nhớ.
Với pointer headerkeo 88, chúng ta có thể nhanh chóng xác định các trường len và alloc:
- Trong phần header của s1keo 88, giá trị của len được đặt thành 0x06, cho thấy độ dài chuỗi dữ liệu là 6 ký tự. Trong khi đó, giá trị của alloc có giá trị là 0x80, nghĩa là mảng ký tự có thể chứa tối đa 128 ký tự. Điều này giúp đảm bảo rằng vùng nhớ được cấp phát đủ lớn để lưu trữ dữ liệu mà không bị tràn hoặc thiếu chỗ trong quá trình xử lý.
- Trong phần header của S299win club, giá trị của len được đặt là 0x0006, điều này có nghĩa là độ dài của chuỗi dữ liệu là 6 byte. Trong khi đó, giá trị alloc có giá trị là 0x03E8, biểu thị kích thước tối đa của mảng ký tự là 1000 đơn vị. (Lưu ý: Trong hình, địa chỉ được xây dựng theo thứ tự nhỏ trước.)
Trong các định nghĩa kiểu header99win club, còn có một số điểm cần chú ý:
- Trong các định nghĩa header sử dụng __attribute__(( packed Điều này được thực hiện để trình biên dịch phân bổ bộ nhớ ở chế độ tối ưu hóa chặt chẽ. Nếu không có thuộc tính nàytỷ lệ kèo bóng đá trực tiếp, trình biên dịch có thể thực hiện tối ưu hóa việc canh chỉnh bộ nhớ cho các trường trong cấu trúc (struct), dẫn đến việc thêm các byte rỗng vào bên trong. Điều đó sẽ làm mất đi sự đảm bảo rằng phần header và dữ liệu của sds luôn liền kề nhau, cũng như không thể truy cập vào trường flags theo cách cố định bằng cách di chuyển một byte theo hướng địa chỉ thấp hơn nữa.
- Trong phần định nghĩa của mỗi header99win club, bạn sẽ thấy xuất hiện một mảng ký tự được đặt tên là `buf[]`. Đây là cách viết đặc biệt trong C để khai báo một mảng ký tự mà không chỉ rõ kích thước cụ thể. Cách này được gọi là mảng linh hoạt (flexible array), cho phép chúng ta tạo ra các cấu trúc dữ liệu linh hoạt hơn, giúp tiết kiệm bộ nhớ và tăng tính linh hoạt trong việc quản lý tài nguyên. Với cách khai báo này, người lập trình có thể dễ dàng thay đổi kích thước dựa trên yêu cầu thực tế mà không cần phải định nghĩa trước chiều dài cố định. flexible array member Bạn chỉ có thể áp dụng kiểu **char[]** ngay sau trường **flags** trong cấu trúctỷ lệ kèo bóng đá trực tiếp, và nó ở đây chỉ đóng vai trò như một dấu hiệu để cho biết ngay sau trường **flags**, sẽ là một mảng chuỗi. Điều này cũng giúp xác định vị trí bù đắp của mảng chuỗi trong cấu trúc. Khi chương trình cấp phát bộ nhớ cho header, phần này không chiếm bất kỳ không gian bộ nhớ nào. Nếu bạn tính toán giá trị của **sizeof(struct sdshdr16)**, kết quả sẽ là 5 byte, trong đó không bao gồm trường **buf**. Điều thú vị là, việc sử dụng kiểu này giúp tối ưu hóa bộ nhớ, bởi vì kích thước thực tế của cấu trúc có thể thay đổi tùy thuộc vào số lượng ký tự được lưu trữ trong mảng. Điều này làm cho việc quản lý tài nguyên trở nên linh hoạt hơn, đặc biệt khi các ứng dụng cần xử lý dữ liệu với kích thước biến thiên.
- Sự khác biệt chính của sdshdr5 so với các định dạng header khác là nó không có trường alloctỷ lệ kèo bóng đá trực tiếp, mà thay vào đó, độ dài được lưu trữ trong 5 bit cao của cờ (flags). Điều này đồng nghĩa với việc nó không thể cấp phát không gian dư thừa cho chuỗi. Khi một chuỗi cần mở rộng động, nó buộc phải tái phân bổ bộ nhớ. Do đó, loại sds chuỗi này thường phù hợp hơn để lưu trữ các chuỗi ngắn và tĩnh (dưới 32 ký tự). Nếu bạn đang làm việc với các dữ liệu cố định hoặc ngắn gọn, sdshdr5 sẽ là lựa chọn tối ưu nhờ hiệu quả về mặt tài nguyên và tốc độ truy xuất. Tuy nhiên, nếu bạn cần xử lý chuỗi lớn hoặc linh hoạt, có thể cần cân nhắc các định dạng header khác để tránh những hạn chế về tính năng.
Cho đến thời điểm này99win club, chúng ta đã rất rõ ràng nhận ra rằng: phần header của chuỗi sds thực tế được ẩn giấu phía trước dữ liệu chuỗi thực sự (theo hướng địa chỉ thấp hơn). Định nghĩa như vậy mang lại một số lợi ích nổi bật sau đây: Thứ nhất, việc đặt header ở vị trí dễ tiếp cận giúp thao tác với dữ liệu trở nên nhanh chóng và hiệu quả. Điều này đặc biệt hữu ích khi cần xử lý hoặc cập nhật thông tin liên quan đến chuỗi trong quá trình chạy chương trình. Thứ hai, cách sắp xếp này cho phép tối ưu hóa bộ nhớ. Header có kích thước nhỏ gọn, nhưng vẫn chứa đầy đủ thông tin cần thiết về độ dài và trạng thái của chuỗi, từ đó giảm thiểu đáng kể lượng bộ nhớ tiêu tốn không cần thiết. Cuối cùng, định nghĩa này tạo điều kiện thuận lợi cho việc mở rộng hoặc thu nhỏ chuỗi mà không cần phải di chuyển toàn bộ dữ liệu. Chỉ cần thay đổi giá trị trong header là đã có thể điều chỉnh kích thước chuỗi một cách linh hoạt. Tóm lại, việc sắp xếp header trước dữ liệu chuỗi không chỉ mang lại lợi ích về hiệu suất mà còn giúp tối ưu hóa quản lý bộ nhớ một cách thông minh.
- Đầu dãy (header) và dữ liệu nằm liền kề nhau mà không cần được phân bổ thành hai vùng nhớ riêng biệt. Điều này giúp giảm thiểu các mảnh vụn bộ nhớ (memory fragmentation)99win club, từ đó nâng cao hiệu quả sử dụng lưu trữ (storage efficiency). Hơn nữa, cách sắp xếp này cũng làm cho việc quản lý bộ nhớ trở nên đơn giản hơn, giảm tải đáng kể cho hệ thống khi xử lý khối lượng lớn dữ liệu.
- Dù header có thể có nhiều loại khác nhaukeo 88, nhưng SDS (Simple Dynamic String) hoàn toàn có thể được biểu diễn bằng một con trỏ char thống nhất. Hơn nữa, nó cũng tương thích về mặt kiểu dữ liệu với chuỗi trong ngôn ngữ C truyền thống. Nếu trong SDS lưu trữ là một chuỗi ký tự có thể in được, chúng ta có thể trực tiếp truyền nó vào các hàm C mà không gặp vấn đề gì. Ví dụ như sử dụng hàm strcmp để so sánh độ dài của hai chuỗi hoặc dùng hàm printf để hiển thị nội dung của chuỗi đó ra màn hình. Điều này không chỉ giúp tiết kiệm thời gian mà còn làm cho việc xử lý dữ liệu trở nên dễ dàng và hiệu quả hơn bao giờ hết.
Khi đã hiểu rõ cấu trúc dữ liệu sds99win club, các hàm thao tác cụ thể sẽ dễ hiểu hơn.
Một số hàm cơ bản của sds
- sdslen(const sds s): Lấy độ dài chuỗi sds.
- hàm sdssetlen(sds skeo 88, size_t newlen): Điều chỉnh độ dài của chuỗi sds thành giá trị mong muốn được chỉ định bởi biến newlen. Trong quá trình thực hiện, hàm này sẽ cập nhật trực tiếp trường lưu trữ độ dài của chuỗi mà không thay đổi nội dung bên trong, trừ khi cần cắt bớt phần dư thừa nếu newlen nhỏ hơn chiều dài hiện tại. Điều này đặc biệt hữu ích khi bạn muốn thay đổi kích thước chuỗi mà không cần tạo bản sao mới, giúp tối ưu hóa hiệu suất trong nhiều ứng dụng xử lý chuỗi phức tạp.
- Hàm sdsinclen(sds chuỗikeo 88, size_t tăng_dlength): Mục đích của hàm này là mở rộng độ dài của chuỗi sds.
- sdsalloc(const sds s): Lấy dung lượng chuỗi sds.
- hàm sdssetalloc(sds stỷ lệ kèo bóng đá trực tiếp, size_t newlen) có nhiệm vụ điều chỉnh dung lượng của chuỗi sds. Đây là hàm quan trọng trong việc quản lý bộ nhớ cho các chuỗi động, cho phép thay đổi kích thước lưu trữ mà không làm mất dữ liệu hiện tại của chuỗi. Điều này giúp tối ưu hóa hiệu suất khi làm việc với các chuỗi có độ dài thay đổi liên tục trong ứng dụng.
- hàm sdsavail(const sds s): Lấy không gian trống còn lại trong chuỗi sds (tức là giá trị của alloc trừ đi len). Không gian này có thể được sử dụng để thêm dữ liệu mà không cần phân bổ bộ nhớ mới ngay lập tứckeo 88, giúp tối ưu hóa hiệu suất khi thao tác với chuỗi.
- tinhKichThuocTieuDe(int loaiTieuDe): Xác định kích thước của tiêu đề dựa trên loại tiêu đề được chỉ định.
- sdsReqType(kích thước_dữ_liệu_chuỗi: size_t): Hàm này sẽ xác định loại header cần thiết dựa trên kích thước của chuỗi dữ liệu được truyền vào. Dựa trên giá trị đầu vào99win club, nó sẽ phân tích và đưa ra quyết định về cấu trúc header phù hợp nhất để đảm bảo dữ liệu được xử lý một cách hiệu quả và chính xác trong hệ thống.
Ở đây chúng ta chọn mã nguồn của sdslen và sdsReqType để xem xét.
static
inline
size_t
sdslen
(
const
sds
s
)
{
unsigned
char
flags
=
s
[
-
1
];
switch
(
flags
&
SDS_TYPE_MASK
)
{
case
SDS_TYPE_5
:
return
SDS_TYPE_5_LEN
(
flags
);
case
SDS_TYPE_8
:
return
SDS_HDR
(
8
,
s
)
->
len
;
case
SDS_TYPE_16
:
return
SDS_HDR
(
16
,
s
)
->
len
;
case
SDS_TYPE_32
:
return
SDS_HDR
(
32
,
s
)
->
len
;
case
SDS_TYPE_64
:
return
SDS_HDR
(
64
,
s
)
->
len
;
}
return
0
;
}
static
inline
char
sdsReqType
(
size_t
string_size
)
{
if
(
string_size
<
1
<<
5
)
return
SDS_TYPE_5
;
if
(
string_size
<
1
<<
8
)
return
SDS_TYPE_8
;
if
(
string_size
<
1
<<
16
)
return
SDS_TYPE_16
;
if
(
string_size
<
1ll
<<
32
)
return
SDS_TYPE_32
;
return
SDS_TYPE_64
;
}
Tương tự như phân tích trước đótỷ lệ kèo bóng đá trực tiếp, sdslen đầu tiên sử dụng s[-1] để dịch chuyển về phía địa chỉ thấp hơn một byte, từ đó lấy được giá trị flags; tiếp theo, nó thực hiện phép AND theo vị trí với SDS_TYPE_MASK để xác định loại header; sau đó, dựa trên loại header khác nhau, nó gọi hàm SDS_HDR để lấy con trỏ bắt đầu của header, từ đó có thể thu được giá trị của trường len. Quá trình này cho thấy cách mà cơ chế quản lý bộ nhớ trong cấu trúc dữ liệu này hoạt động một cách linh hoạt và hiệu quả.
Qua mã nguồn của sdsReqTypetỷ lệ kèo bóng đá trực tiếp, dễ dàng nhận thấy:
- Độ dài nằm trong khoảng 0 và 2^5-1keo 88, chọn header loại SDS_TYPE_5.
- Độ dài nằm trong khoảng 2^5 và 2^8-199win club, chọn header loại SDS_TYPE_8.
- Độ dài nằm trong khoảng 2^8 và 2^16-199win club, chọn header loại SDS_TYPE_16.
- Độ dài nằm trong khoảng 2^16 và 2^32-199win club, chọn header loại SDS_TYPE_32.
- Khi độ dài vượt quá 2^32tỷ lệ kèo bóng đá trực tiếp, bạn nên chọn loại header SDS_TYPE_64. Loại header này có khả năng biểu diễn độ dài tối đa lên tới 2^64 - 1, cho phép quản lý các chuỗi lớn một cách hiệu quả và linh hoạt trong hệ thống.
Về phần mã thực hiện của sdsReqType99win club, từ phiên bản 3.2.0 trở về trước, nó luôn gặp phải vấn đề liên quan đến giá trị giới hạn độ dài. Tuy nhiên, gần đây, trên nhánh 3.2 đã có những cải tiến đáng kể để giải quyết triệt để vấn đề này. commit 6032340 Đã sửa chữa.
Tạo và hủy sds
sds
sdsnewlen
(
const
void
*
init
,
size_t
initlen
)
{
void
*
sh
;
sds
s
;
char
type
=
sdsReqType
(
initlen
);
/* Empty strings are usually created in order to append. Use type 8
* since type 5 is not good at this. */
if
(
type
==
SDS_TYPE_5
&&
initlen
==
0
)
type
=
SDS_TYPE_8
;
int
hdrlen
=
sdsHdrSize
(
type
);
unsigned
char
*
fp
;
/* flags pointer. */
sh
=
s_malloc
(
hdrlen
+
initlen
+
1
);
if
(
!
init
)
memset
(
sh
,
0
,
hdrlen
+
initlen
+
1
);
if
(
sh
==
NULL
)
return
NULL
;
s
=
(
char
*
)
sh
+
hdrlen
;
fp
=
((
unsigned
char
*
)
s
)
-
1
;
switch
(
type
)
{
case
SDS_TYPE_5
:
{
*
fp
=
type
|
(
initlen
<<
SDS_TYPE_BITS
);
break
;
}
case
SDS_TYPE_8
:
{
SDS_HDR_VAR
(
8
,
s
);
sh
->
len
=
initlen
;
sh
->
alloc
=
initlen
;
*
fp
=
type
;
break
;
}
case
SDS_TYPE_16
:
{
SDS_HDR_VAR
(
16
,
s
);
sh
->
len
=
initlen
;
sh
->
alloc
=
initlen
;
*
fp
=
type
;
break
;
}
case
SDS_TYPE_32
:
{
SDS_HDR_VAR
(
32
,
s
);
sh
->
len
=
initlen
;
sh
->
alloc
=
initlen
;
*
fp
=
type
;
break
;
}
case
SDS_TYPE_64
:
{
SDS_HDR_VAR
(
64
,
s
);
sh
->
len
=
initlen
;
sh
->
alloc
=
initlen
;
*
fp
=
type
;
break
;
}
}
if
(
initlen
&&
init
)
memcpy
(
s
,
init
,
initlen
);
s
[
initlen
]
=
'\0'
;
return
s
;
}
sds
sdsempty
(
void
)
{
return
sdsnewlen
(
""
,
0
);
}
sds
sdsnew
(
const
char
*
init
)
{
size_t
initlen
=
(
init
==
NULL
)
?
0
:
strlen
(
init
);
return
sdsnewlen
(
init
,
initlen
);
}
void
sdsfree
(
sds
s
)
{
if
(
s
==
NULL
)
return
;
s_free
((
char
*
)
s
-
sdsHdrSize
(
s
[
-
1
]));
}
sdsnewlen tạo ra một chuỗi sds có độ dài là initlen và sử dụng mảng ký tự được chỉ bởi init (dữ liệu nhị phân bất kỳ) để khởi tạo dữ liệu. Nếu init là NULL99win club, dữ liệu sẽ được khởi tạo bằng tất cả các giá trị 0. Trong quá trình thực hiện, điều quan trọng cần lưu ý là: - Chúng ta phải đảm bảo rằng mảng nguồn được cấp phát hợp lệ và không vượt quá giới hạn bộ nhớ. - Nếu init là NULL, cần kiểm tra xem kích thước bộ nhớ yêu cầu có phù hợp hay không trước khi gán giá trị 0 cho toàn bộ dữ liệu. - Khi sao chép dữ liệu từ mảng nguồn sang chuỗi sds, cần thực hiện cẩn thận để tránh tình trạng tràn bộ nhớ hoặc mất mát thông tin. - Cần tối ưu hóa việc quản lý bộ nhớ để tăng hiệu suất của hàm, chẳng hạn như sử dụng các kỹ thuật tái sử dụng vùng nhớ khi có thể. Đây là những yếu tố cơ bản giúp đảm bảo tính ổn định và hiệu quả khi sử dụng hàm này trong các ứng dụng thực tế.
- Nếu muốn tạo một chuỗi rỗng có độ dài bằng 099win club, thay vì sử dụng header kiểu SDS_TYPE_5, bạn nên chuyển sang sử dụng header kiểu SDS_TYPE_8. Lý do là bởi khi tạo ra chuỗi rỗng này, các thao tác tiếp theo thường sẽ liên quan đến việc thêm dữ liệu vào chuỗi, nhưng header kiểu SDS_TYPE_5 không phải là lựa chọn tối ưu cho trường hợp này (vì nó có thể dẫn đến việc phân bổ lại bộ nhớ không hiệu quả). Header kiểu SDS_TYPE_8 cung cấp khả năng linh hoạt hơn trong việc quản lý bộ nhớ khi dữ liệu được thêm dần vào chuỗi. Điều này giúp tối ưu hóa hiệu suất và giảm thiểu nguy cơ lãng phí tài nguyên hệ thống.
- Bộ nhớ cần thiết có thể được cấp phát một lầntỷ lệ kèo bóng đá trực tiếp, bao gồm ba phần chính: phần header, phần chứa dữ liệu thực tế và phần byte dư cuối cùng (bao gồm hdrlen, initlen và thêm 1 byte). Đây là cách tối ưu để quản lý không gian bộ nhớ trong quá trình xử lý, giúp tránh những vấn đề phát sinh liên quan đến việc chia nhỏ bộ nhớ.
- Dữ liệu chuỗi sds được khởi tạo cuối cùng sẽ được thêm một ký tự kết thúc NULL (s[initlen] = '\0'). Điều này giúp đảm bảo rằng chuỗi được nhận diện đúng cách trong hệ thốngkeo 88, cho phép các hàm xử lý chuỗi dễ dàng xác định độ dài và nội dung của nó mà không gặp bất kỳ nhầm lẫn nào.
Khi làm việc với sdsfree99win club, điều quan trọng cần lưu ý là bạn phải giải phóng toàn bộ bộ nhớ, vì vậy trước tiên bạn cần tính toán và xác định vị trí con trỏ đầu của vùng header. Sau đó, hãy truyền con trỏ này vào hàm s_free để thực hiện việc giải phóng. Con trỏ này chính là địa chỉ mà hàm s_malloc trả về khi được gọi trong hà Việc xác định đúng con trỏ sẽ giúp quá trình quản lý bộ nhớ diễn ra chính xác và hiệu quả hơn.
Thao tác nối (append) của sds
sds
sdscatlen
(
sds
s
,
const
void
*
t
,
size_t
len
)
{
size_t
curlen
=
sdslen
(
s
);
s
=
sdsMakeRoomFor
(
s
,
len
);
if
(
s
==
NULL
)
return
NULL
;
memcpy
(
s
+
curlen
,
t
,
len
);
sdssetlen
(
s
,
curlen
+
len
);
s
[
curlen
+
len
]
=
'\0'
;
return
s
;
}
sds
sdscat
(
sds
s
,
const
char
*
t
)
{
return
sdscatlen
(
s
,
t
,
strlen
(
t
));
}
sds
sdscatsds
(
sds
s
,
const
sds
t
)
{
return
sdscatlen
(
s
,
t
,
sdslen
(
t
));
}
sds
sdsMakeRoomFor
(
sds
s
,
size_t
addlen
)
{
void
*
sh
,
*
newsh
;
size_t
avail
=
sdsavail
(
s
);
size_t
len
,
newlen
;
char
type
,
oldtype
=
s
[
-
1
]
&
SDS_TYPE_MASK
;
int
hdrlen
;
/* Return ASAP if there is enough space left. */
if
(
avail
>=
addlen
)
return
s
;
len
=
sdslen
(
s
);
sh
=
(
char
*
)
s
-
sdsHdrSize
(
oldtype
);
newlen
=
(
len
+
addlen
);
if
(
newlen
<
SDS_MAX_PREALLOC
)
newlen
*=
2
;
else
newlen
+=
SDS_MAX_PREALLOC
;
type
=
sdsReqType
(
newlen
);
/* Don't use type 5: the user is appending to the string and type 5 is
* not able to remember empty spacekeo 88, so sdsMakeRoomFor() must be called
* at every appending operation. */
if
(
type
==
SDS_TYPE_5
)
type
=
SDS_TYPE_8
;
hdrlen
=
sdsHdrSize
(
type
);
if
(
oldtype
==
type
)
{
newsh
=
s_realloc
(
sh
,
hdrlen
+
newlen
+
1
);
if
(
newsh
==
NULL
)
return
NULL
;
s
=
(
char
*
)
newsh
+
hdrlen
;
}
else
{
/* Since the header size changestỷ lệ kèo bóng đá trực tiếp, need to move the string forward,
* and can't use realloc */
newsh
=
s_malloc
(
hdrlen
+
newlen
+
1
);
if
(
newsh
==
NULL
)
return
NULL
;
memcpy
((
char
*
)
newsh
+
hdrlen
,
s
,
len
+
1
);
s_free
(
sh
);
s
=
(
char
*
)
newsh
+
hdrlen
;
s
[
-
1
]
=
type
;
sdssetlen
(
s
,
len
);
}
sdssetalloc
(
s
,
newlen
);
return
s
;
}
Hàm sdscatlen sẽ thêm dữ liệu nhị phân có độ dài len từ con trỏ t vào cuối chuỗi sds của biến s. Điều thú vị là lệnh append được trình diễn ở phần đầu bài viết cũng chính là thực hiện thông qua việc gọi hàm sdscatlen bên trong. Hàm này đóng vai trò như một công cụ nền tảng để mở rộng chuỗi bằng cách gắn thêm nội dung mới vào sau nó.
Trong quá trình triển khai của sdscatlen99win club, trước tiên hàm sdsMakeRoomFor sẽ được gọi để đảm bảo chuỗi s có đủ không gian để thêm dữ liệu có độ dài bằng len. Hàm sdsMakeRoomFor có thể sẽ phân bổ bộ nhớ mới hoặc cũng có thể không cần làm điều đó nếu đã có đủ không gian sẵn có trong bộ nhớ hiện tại. Nếu không gian hiện tại không đủ, hàm này sẽ thực hiện việc mở rộng vùng nhớ và tạo ra một khoảng trống để chuẩn bị cho việc thêm dữ liệu mà không làm gián đoạn các hoạt động đang diễn ra trên chuỗi gốc. Điều này giúp tối ưu hóa hiệu suất khi thao tác với chuỗi và tránh những trường hợp gây lỗi như vượt quá giới hạn bộ nhớ. Ngược lại, nếu bộ nhớ hiện tại đã đủ lớn, hàm sẽ không thực hiện bất kỳ hành động nào, giảm thiểu sự tiêu tốn tài nguyên hệ thống.
Hàm MakeRoomFor đóng vai trò cực kỳ quan trọng trong việc triển khai của sds (simple dynamic string). Khi tìm hiểu mã nguồn thực hiện của hàm này99win club, có một số điểm cần đặc biệt chú ý: Trước tiên, mục tiêu chính của MakeRoomFor là đảm bảo rằng chuỗi hiện tại có đủ dung lượng để thêm vào một số ký tự mà không cần phải thực hiện việc cấp phát bộ nhớ mới ngay lập tức. Điều này giúp tối ưu hóa hiệu suất và giảm thiểu các hoạt động tốn kém về mặt tài nguyên. Thứ hai, hàm này thường sẽ kiểm tra xem còn bao nhiêu byte trống trong vùng nhớ hiện tại so với yêu cầu thực tế. Nếu dung lượng không đủ, nó sẽ thực hiện việc mở rộng bộ nhớ theo cách an toàn, chẳng hạn như nhân đôi kích thước hiện tại hoặc sử dụng giá trị tối thiểu đảm bảo yêu cầu bổ sung. Cuối cùng, điều quan trọng là phải hiểu rằng MakeRoomFor không chỉ đơn thuần là mở rộng bộ nhớ mà còn giữ nguyên phần dữ liệu hiện tại để tránh mất mát thông tin. Đây là bước quan trọng trong quá trình quản lý bộ nhớ động của sds.
- Nếu trong chuỗi gốc có đủ không gian trống sẵn có (avail lớn hơn hoặc bằng addlen)keo 88, thì nó sẽ không thực hiện bất kỳ thao tác nào và trả về ngay lập tức.
- Khi cần phân bổ bộ nhớtỷ lệ kèo bóng đá trực tiếp, nó sẽ cấp phát nhiều hơn so với yêu cầu thực tế để dự phòng cho việc thêm dữ liệu tiếp theo. Trong trường hợp chuỗi đã khá dài, ít nhất nó sẽ phân bổ thêm số lượng byte được xác định bởi hằng số SDS_MAX_PREALLOC, có giá trị là (1024 * 1024) = 1MB, như được định nghĩa trong tệp sds.h. Điều này giúp đảm bảo rằng khi dữ liệu tiếp tục tăng lên, bộ nhớ không bị thiếu và hiệu suất không bị ảnh hưởng do phải phân bổ thêm thường xuyên.
- Dựa trên không gian được phân bổ lạitỷ lệ kèo bóng đá trực tiếp, có thể cần thay đổi kiểu dữ liệu của phần header (vì trường "alloc" trong header cũ quá ngắn để biểu diễn dung lượng sau khi tăng lên). Điều này sẽ giúp đảm bảo rằng cấu trúc có thể lưu trữ chính xác thông tin về kích thước mới mà không gây ra lỗi hoặc giới hạn không mong muốn.
- Nếu cần thay đổi phần header99win club, toàn bộ không gian chuỗi (bao gồm cả phần header) sẽ phải được cấp phát lại (s_malloc), sau đó dữ liệu cũ sẽ được sao chép sang vị trí mới một cách cẩn thận để đảm bảo tính toàn vẹn của dữ liệu.
- Nếu không cần thay đổi phần header (nếu header hiện tại vẫn đủ dùng)keo 88, bạn có thể sử dụng một phiên bản đặc biệt của hàm s_realloc để cố gắng phân bổ lại bộ nhớ ngay tại vị trí ban đầu. Cách thức cụ thể của việc thực hiện s_realloc sẽ phụ thuộc vào trình biên dịch Redis đã chọn allocator nào (trên Linux, mặc định là jemalloc). Tuy nhiên, bất kể allocator nào được sử dụng, ý nghĩa cơ bản của realloc đều giống nhau: nó cố gắng phân bổ thêm bộ nhớ tại vị trí hiện tại nếu có đủ không gian trống để thực hiện yêu cầu đó. Nếu có đủ không gian trống, hàm trả về địa chỉ cũ; còn nếu không đủ, nó sẽ cấp phát vùng nhớ mới và di chuyển dữ liệu từ vùng nhớ cũ sang vùng nhớ mới. Bạn có thể tham khảo thêm thông tin chi tiết trong tài liệu liên quan đến realloc của các allocator khác nhau. http://man.cx/realloc 。
Từ giao diện của hàm sdscatlentỷ lệ kèo bóng đá trực tiếp, chúng ta có thể nhận ra một mô hình sử dụng: khi gọi hàm này, cần truyền vào một biến sds cũ và nó sẽ trả về một biến sds mới. Do cách thực hiện nội bộ có thể dẫn đến thay đổi địa chỉ, nên sau khi gọi hàm, biến cũ trước đó sẽ trở nên không còn hiệu lực nữa, và tất cả các thao tác tiếp theo phải sử dụng biến mới được trả về thay thế. Không chỉ riêng hàm sdscatlen, mà các hàm khác trong thư viện sds (như sdscpy, sdstrim, sdsjoin,...), cũng như một số cấu trúc dữ liệu trong Redis có khả năng mở rộng bộ nhớ tự động (như ziplist) đều tuân theo mô hình sử dụng tương tự. Hơn nữa, việc này cho phép tối ưu hóa hiệu suất và quản lý bộ nhớ linh hoạt hơn. Khi sử dụng các hàm này, người lập trình cần luôn chú ý cập nhật biến tham chiếu sau mỗi lần gọi để tránh các lỗi liên quan đến việc sử dụng dữ liệu đã bị hủy. Điều này đặc biệt quan trọng trong các ứng dụng đòi hỏi tính ổn định cao hoặc làm việc với lượng lớn dữ liệu. Nhờ thiết kế này, cả sds lẫn Redis đều có thể đảm bảo hiệu suất tốt nhất trong mọi tình huống vận hành.
Tìm hiểu qua về mối quan hệ giữa sds và string
Bây giờ chúng ta quay lại xem ví dụ về thao tác chuỗi ở phần đầu bài viết.
- Thao tác append sử dụng sdscatlen của sds để thực hiện. Trước đó đã đề cập.
- Cả hai hàm setbit và getrange đều hoạt động bằng cách đầu tiên sử dụng key để lấy toàn bộ chuỗi sdstỷ lệ kèo bóng đá trực tiếp, sau đó thực hiện thao tác chọn hoặc chỉnh sửa phần cụ thể của chuỗi đó. Do sds về bản chất là một mảng ký tự, nên việc thao tác trên bất kỳ phần nào của nó đều trở nên khá trực quan và dễ dàng. Ngoài ra, tính chất này còn giúp cho việc quản lý và thao tác dữ liệu trong bộ nhớ trở nên hiệu quả hơn, đặc biệt khi làm việc với các chuỗi lớn.
Tuy nhiên99win club, bên cạnh việc hỗ trợ các thao tác cơ bản, string còn có thể thực hiện các hoạt động như incr (tăng giá trị) và decr (giảm giá trị) khi giá trị được lưu trữ là một số. Vậy, khi string lưu trữ giá trị số, liệu cấu trúc lưu trữ bên trong vẫn là sds (Simple Dynamic String) không? Thực tế, nó đã thay đổi. Đồng thời, trong trường hợp này, cách thức hoạt động của setbit và getrange cũng sẽ khác biệt. Những chi tiết này, chúng ta sẽ cùng tìm hiểu một cách hệ thống hơn khi đề cập đến robj trong bài viết tiếp theo.
Bài viết gốctỷ lệ kèo bóng đá trực tiếp, vui lòng ghi rõ nguồn và bao gồm mã QR bên dưới! Nếu không, từ chối tái bản!
Liên kết bài viết: /3ht626mm.html
Hãy theo dõi tài khoản Weibo cá nhân của tôi: Tìm kiếm tên "Trương Tiết Lệ" trên Weibo.

Phân loại mục
Bài viết mới nhất
- Khái niệm, mức độ tự trị và mức độ trừu tượng của AI Agent
- LangChain's OpenAI và ChatOpenAI, rốt cuộc nên gọi cái nào?
- Phần tiếp theo của DSPy: Phân tích thêm về o1, Tính toán trong Thời gian Suy luận (Inference-time Compute) và Khả năng Lý luận (Reasoning) Trong phần trước, chúng ta đã khám phá những khái niệm cơ bản của DSPy. Giờ đây, hãy cùng đi sâu hơn vào các yếu tố quan trọng như mô hình o1 - một mô hình có khả năng tự học cao với dữ liệu đầu vào ít hơn. Điều này mở ra cánh cửa cho việc tối ưu hóa hiệu suất mô hình mà không cần tăng đáng kể lượng tài nguyên. Tiếp theo là khía cạnh tính toán trong thời gian suy luận (Inference-time Compute). Đây là khái niệm liên quan đến lượng tài nguyên cần thiết khi mô hình thực sự hoạt động để đưa ra dự đoán. Việc giảm thiểu lượng tính toán này không chỉ giúp tiết kiệm năng lượng mà còn cải thiện tốc độ phản hồi của hệ thống. Cuối cùng, chúng ta sẽ thảo luận về khả năng lý luận (Reasoning), một yếu tố quyết định trí tuệ nhân tạo có thể hiểu sâu sắc vấn đề hay không. Khả năng này không chỉ yêu cầu mô hình có kiến thức rộng mà còn phải biết cách kết nối thông tin từ nhiều nguồn khác nhau để đưa ra phán đoán hợp lý. Bằng cách hiểu rõ những khái niệm này, chúng ta có thể phát triển các mô hình AI hiệu quả hơn và thông minh hơn trong tương lai. Hãy cùng chờ đón những khám phá mới mẻ trong lĩnh vực này!
- Nói chuyện về DSPy và kỹ thuật tự động hóa gợi ý (phần giữa)
- Nói chuyện về DSPy và kỹ thuật tự động hóa gợi ý (phần đầu)
- Giải thích một chút: Phân tích nguyên lý xác suất đằng sau LLM
- Bắt đầu từ Vương Tiểu Bảo: Giới hạn đạo đức và quan điểm thiện ác của người bình thường
- Xem xét lại thông tin từ GraphRAG
- Những điều thay đổi và không thay đổi trong sự thay đổi công nghệ: Làm thế nào để tạo ra token nhanh hơn?
- Thể trí thông minh doanh nghiệp, số hóa và phân công ngành nghề