Hành trình nâng cao kỹ năng dữ liệu của người mới bắt đầu (phần trên) —— Từ script Shell đến MapReduce
2016-10-30
Năm đó, Vừa tốt nghiệp trường đại học chuyên ngành công nghệ thông tinđánh bài online, ban đầu anh ấy cũng không thực sự rõ mình muốn làm công việc nào, chỉ biết rằng trước mắt sẽ tìm một công ty internet để làm về kỹ thuật đã. Sau khi ra trường, anh ấy bắt đầu tham gia các buổi phỏng vấn và gửi CV đến nhiều nơi, với hy vọng tìm được một môi trường phù hợp để tích lũy kinh nghiệm. Dần dần, từ những trải nghiệm nhỏ nhặt trong quá trình làm việc, anh ấy bắt đầu nhận ra đam mê của mình và định hình rõ hơn về con đường sự nghiệp phía trước.
Một ngày nọđánh bài online, cậu bé Tiểu Bạch đến một công ty khởi nghiệp nhỏ mới thành lập để tham gia phỏng vấn. Dù quy mô công ty không lớn, nhưng đội ngũ nhân sự lại vô cùng ấn tượng. Hai người sáng lập đều là cử nhân Quản trị Kinh doanh của Học viện Công nghệ Massachusetts (MIT), và hiện đang đảm nhiệm chức vụ đồng CEO. Họ tự hào khoe rằng toàn bộ đội ngũ nhân viên từ quản lý vận hành, tài chính, marketing cho đến bán hàng đều được tuyển dụng từ các công ty lớn với mức lương cao ngất ngưởng. Ngoài ra, họ còn tiết lộ với Tiểu Bạch về sự xuất hiện của một cổ đông bí ẩn có quan hệ sâu sắc với chính phủ, mặc dù danh tính của người này vẫn chưa được tiết lộ công khai. Cậu bé cảm thấy hứng thú và quyết định tìm hiểu thêm về cơ hội việc làm tại nơi này.
Chúng tôi có nguồn vốn đầu tư mạo hiểm lên tới hàng triệu đô la Mỹsv 88, và đội ngũ cơ bản đã được sắp xếp. Hiện tại mọi thứ đều đã sẵn sàng, chỉ thiếu một lập trình viên nữa.
Hằng ngày tại trườngbxh ngoai hang anh, luôn đắm chìm trong những câu chuyện truyền cảm hứng về những người khởi nghiệp thành công, đặc biệt là những ai đã nhận được vốn đầu tư mạo hiểm. Đối với cậu ấy, họ không chỉ là tấm gương sáng mà còn là những nhân vật đáng ngưỡng mộ, khiến cậu luôn khao khát học hỏi và tìm hiểu thêm về con đường đầy thử thách nhưng cũng đầy thú vị này.
Các bạn định làm sản phẩm gì? hỏi.
Điều này liên quan đến sự sáng tạo của chúng tôiđánh bài online, vì vậy xin được giữ bí mật trong thời gian này. Tuy nhiên, tôi có thể nói với bạn rằng chúng tôi đang phát triển một sản phẩm tuyệt vời, một sản phẩm sẽ làm thay đổi toàn diện ngành công nghiệ Đây không chỉ là một bước tiến mà còn là một cuộc cách mạng thực sự, mang lại trải nghiệm hoàn toàn mới cho người dùng trên toàn thế giới. Hai CEO trả lời một cách bí ẩn.
Sau đósv 88, họ bổ sung thêm,
Chúng tôi dự định sẽ niêm yết trong vòng hai năm.
Nghe xongsv 88, không khỏi cảm thấy xúc động, sau đó liền gia nhập công ty này.
Công ty đã có một hệ thống website đang hoạt động ổn địnhbxh ngoai hang anh, và công việc hàng ngày của là bảo trì trang web này. Công việc không quá vất vả, thường ngày chỉ cần đọc code, kiểm tra và sửa lỗi nhỏ. Thỉnh thoảng, anh ấy cũng sẽ thêm vài tính năng đơn giản theo yêu cầu từ khách hàng hoặc đồng nghiệp, nhưng nhìn chung, công việc vẫn khá nhẹ nhàng và có nhiều thời gian để tìm hiểu thêm về các công nghệ mới.
Một ngày nọbxh ngoai hang anh, bất ngờ một trong những giám đốc điều hành lớn yêu cầu tổng hợp lại các số liệu của trang web, chẳng hạn như người dùng hoạt động hàng ngày (Daily Active Users), người dùng hoạt động hàng tuần (Weekly Active Users) và người dùng hoạt động hàng tháng (Monthly Active Users). Ông ấy nói rằng những con số này sẽ được trình bày trước các nhà đầu tư. Điều này khiến cảm thấy vô cùng áp lực nhưng cũng rất hào hứng vì đây là cơ hội để chứng minh khả năng của mình.
Sau khi suy nghĩ một chútbxh ngoai hang anh, cậu bé nhỏ nhận ra rằng tài liệu mà mình đang có trong tay chính là nhật ký truy cập (Access Log). Đây là loại tệp được tạo mỗi ngày, và mỗi dòng trong tệp này đều có định dạng như sau:
[Thời gian] [ID người dùng] [Tên hoạt động] [Các tham số khác...]
Giả sử bạn muốn thống kê số người dùng hoạt động hàng ngàyđánh bài online, bạn cần loại bỏ các dòng trùng lặp có cùng ID người dùng trong một tệp (mỗi tệp đại diện cho một ngày), sau đó số lượng dòng còn lại trong tệp chính là dữ liệu về số người dùng hoạt động hàng ngày. Đối với số người dùng hoạt động theo tuần hoặc theo tháng cũng tương tự như vậy, chỉ khác là thay vì xem xét trong một ngày, bạn sẽ thực hiện thao tác loại bỏ trùng lặp trong khoảng thời gian một tuần hoặc một tháng. Điều này giúp bạn dễ dàng xác định được số lượng người dùng độc nhất đã tương tác trong từng khoảng thời gian cụ thể.
Khi đósv 88, chỉ biết viết chương trình Java, vì vậy anh ấy viết một chương trình Java để thống kê:
Bạn có thể đọc từng dòng từ nội dung của một tệp tin đồng thời duy trì trong bộ nhớ một tập hợp HashSet để thực hiện việc kiểm tra trùng lặp. Mỗi khi đọc một dòngsv 88, bạn phân tích và trích xuất ID người dùng, sau đó kiểm tra xem ID này đã tồn tại trong tập hợp HashSet hay chưa. Nếu không tồn tại, bạn thêm ID vào tập hợp; nếu đã tồn tại, bạn bỏ qua dòng này và tiếp tục đọc dòng kế tiếp. Khi quá trình xử lý tệp tin kết thúc, số lượng phần tử trong tập hợp HashSet sẽ chính là dữ liệu về số người dùng hoạt động trong ngày tương ứng. Ngoài ra, trong quá trình xử lý, bạn cũng có thể ghi lại các hành động hoặc trạng thái của từng ID để dễ dàng theo dõi hơn. Điều này đặc biệt hữu ích khi bạn cần phân tích sâu hơn hoặc đối chiếu với các nguồn dữ liệu khác.
Tương tựsv 88, việc thống kê người dùng hoạt động hàng tuần và hàng tháng chỉ cần cho chương trình này đọc tệp tin của 7 ngày và 30 ngày rồi xử lý.
Từ đó về saubxh ngoai hang anh, hai vị giám đốc điều hành thường xuyên lui tới tìm để nhờ thống kê các loại dữ liệu. hiểu rằng, họ đang tham gia ngày càng nhiều vào các hội nghị và sự kiện trong giới đầu tư, có lẽ là muốn huy động thêm vốn cho công ty trong vòng gọi vốn thứ hai. Hai vị này dường như đã lên kế hoạch chi tiết cho những hoạt động kinh doanh sắp tới, và việc tìm đến không chỉ đơn thuần là để lấy số liệu mà còn để lắng nghe ý kiến chuyên môn từ anh. Mỗi khi tiếp nhận yêu cầu, đều cảm thấy áp lực nhưng cũng đầy hứng khởi, bởi anh biết mình đang đóng vai trò quan trọng trong việc định hình tương lai của công ty. Một buổi tối, khi hai vị CEO rời đi sau một cuộc họp kéo dài, ngồi lại với suy nghĩ: liệu mình có đủ khả năng để hỗ trợ họ đạt được mục tiêu này? Nhưng rồi, anh nhanh chóng gạt bỏ lo lắng, quyết tâm làm việc thật chăm chỉ để giúp công ty vượt qua thử thách.
Mỗi lần nhìn thấy dữ liệu sau khi xử lýsv 88, họ đều tỏ ra rất khó tin. Có phải đã có sai sót trong việc thống kê không? Liệu chúng ta chỉ có vậy thôi sao?
không thể trả lời.
Thời gian trôi qua nhanh chóngsv 88, một năm đã trôi đi. nhận ra rằng khoảng cách để công ty đạt được mục tiêu niêm yết trên thị trường chứng khoán vẫn không thay đổi so với cách đây một năm. Điều tồi tệ hơn là số tiền mà công ty từng huy động được trước đó giờ đã gần như cạn kiệt, và vòng gọi vốn thứ hai thì vẫn chưa có dấu hiệu khả quan. Thêm vào đó, lương tháng trước của anh ấy cũng bị chậm trả. Trước tình hình đó, anh quyết định từ bỏ công việc để tìm cơ hội mới. Cũng trong thời gian này, anh tự nhủ rằng cần phải có một bước ngoặt lớn để thay đổi cuộc sống. Anh dành thời gian để suy nghĩ về những gì mình thực sự muốn và lên kế hoạch cho tương lai. Mặc dù cảm thấy lo lắng về con đường phía trước, nhưng anh tin rằng việc dám chấp nhận rủi ro sẽ mở ra cánh cửa đến thành công mới.
Cho đến ngày nghỉ việcsv 88, dữ liệu hoạt động hàng ngày của công ty vẫn chưa vượt quá bốn chữ số.
Công việc thứ hai của là ở một công ty phát triển ứng dụng di động.
Giám đốc công nghệ của công ty nàysv 88, người thường được mọi người gọi là ông Vương, nổi tiếng với cách tuyển dụng thẳng thắn và quyết đoán. Trong một buổi phỏng vấn, khi nghe cậu bé khoe rằng mình từng làm việc với dữ liệu thống kê, ông Vương chẳng cần suy nghĩ nhiều đã quyết định nhận cậu vào làm luôn. Có lẽ ông Vương đã nhìn thấy tiềm năng trong mắt mà không cần quá nhiều lời giới thiệu.
Khi mới vào công tyđánh bài online, mới biết rằng CEO trước đây từng làm trong lĩnh vực tài chính và cực kỳ coi trọng dữ liệu. Mỗi ngày, ông ấy tự đặt ra hơn mười yêu cầu thống kê khác nhau về các loại dữ liệu lớn nhỏ. Không chỉ vậy, những yêu cầu này thường đòi hỏi sự chính xác cao và được phân tích sâu, khiến toàn bộ đội ngũ nhân viên phải làm việc hết sức căng thẳng để hoàn thành đúng hạn.
Xiao Bạch hàng ngày tất bật viết các chương trình thống kêsv 88, xử lý nhiều định dạng dữ liệu khác nhau, thường làm việc đến tận mười một hoặc mười hai giờ đêm. Thêm vào đó, điều khiến cậu ấy cảm thấy nản lòng hơn cả là rất nhiều yêu cầu thống kê chỉ mang tính chất một lần, và phần lớn các chương trình thống kê mà Xiao Bạch viết cũng chỉ được chạy duy nhất một lần rồi bị bỏ xó, chẳng bao giờ được sử dụng thêm nữa. Cậu ấy đã từng nghĩ rằng mình có thể cải tiến hoặc tái sử dụng những chương trình này trong tương lai, nhưng dần dần nhận ra rằng, việc xây dựng chúng thường khá phức tạp và không có thời gian để tối ưu hóa chúng sau khi hoàn thành nhiệm vụ. Dù vậy, Xiao Bạch vẫn kiên trì tiếp tục công việc, vì biết rằng mỗi chương trình dù chỉ được dùng một lần cũng góp phần quan trọng trong việc hoàn thành mục tiêu chung của dự án.
Một ngày nọbxh ngoai hang anh, anh ấy đang tất bật làm việc với việc tổng hợp số liệu. Bỗng nhiên ông Vương bước đến và nhận thấy anh ấy đang sử dụng ngôn ngữ lập trình Java, điều này khiến ông vô cùng ngạc nhiên. Sau khi cùng anh Tiểu Bạch phân tích kỹ lưỡng, ông Vương cho rằng phần lớn nhu cầu thống kê dữ liệu thực tế đều có thể thu thập từ nhật ký truy cập. Khi xử lý các tệp văn bản dạng nhật ký, sử dụng kịch bản Shell sẽ tiện lợi hơn rất nhiều.
Vì vậyđánh bài online, đã dành một khoảng thời gian để học lập trình Shell. Anh nhận ra rằng, việc sử dụng một số lệnh Shell để thống kê dữ liệu, chẳng hạn như người dùng hoạt động hàng ngày, trở nên vô cùng dễ dàng. Hãy lấy tập tin nhật ký truy cập của một ngày cụ thể có tên là access.log làm ví dụ, mỗi dòng trong tệp này có định dạng như sau:
[Thời gian] [ID người dùng] [Tên hoạt động] [Các tham số khác...]
Chỉ cần một lệnh duy nhất để thống kê hoạt động hàng ngày:
cat
access
.
log
|
awk
'
{
print
$
2
}
'
|
sort
|
uniq
|
wc
-
l
Lệnh này sử dụng awk để trích xuất cột thứ hai (tức là ID người dùng) từ tệp access.logsv 88, sau đó sắp xếp kết quả sao cho các ID người dùng trùng lặp nằm cạnh nhau. Tiếp theo, lệnh uniq được áp dụng để loại bỏ các dòng trùng lặp liền kề, từ đó thu được danh sách các ID người dùng độc lập. Cuối cùng, bằng cách sử dụng lệnh wc để đếm số lượng dòng, ta có thể xác định được số lượng người dùng hoạt động trong ngày.
Sau khi viết một số kịch bản Shellbxh ngoai hang anh, người mới bắt đầu dần nhận ra rằng, chỉ bằng cách sử dụng một số lệnh đơn giản, họ có thể thực hiện nhanh chóng các phép toán hợp, giao và hiệu trên tập dữ liệu file. Ngoài ra, họ còn khám phá thêm rằng việc kết hợp các công cụ mạnh mẽ như grep, awk hay sort sẽ giúp họ xử lý dữ liệu phức tạp một cách dễ dàng và hiệu quả hơn bao giờ hết.
Giả sử a và b là hai tệp tinbxh ngoai hang anh, mỗi dòng được coi như một phần tử dữ liệu, và mỗi dòng đều khác nhau.
Để tính hợp nhất của a và bsv 88, sử dụng lệnh sau đây:
cat
a
b
|
sort
|
uniq
>
a_b
.
union
Giao:
cat
a
b
|
sort
|
uniq
-
d
>
a_b
.
intersect
Tham số -d của lệnh uniq có nghĩa là: chỉ in ra các dòng lặp lại liền kề.
Việc tính hiệu của a và b phức tạp hơn một chút:
cat
a_b
.
union
b
|
sort
|
uniq
-
u
>
a_b
.
diff
Tại đâysv 88, chúng ta sử dụng kết quả của tập hợp hợp nhất từ a và b (a_b.union), sau đó sắp xếp nó cùng với b. Tiếp theo, bằng cách áp dụng lệnh uniq với tham số -u, các dòng không trùng lặp liên tiếp sẽ được hiển thị. Kết quả thu được chính là hiệu tập hợp của a và b.
nhận ra rằng nhiều phép thống kê dữ liệu có thể được thực hiện bằng cách sử dụng phép hợpđánh bài online, giao và hiệu của tập hợp.
Đầu tiênđánh bài online, bạn hãy xử lý các bản ghi truy cập hàng ngày, và từ đó sẽ tạo ra được một tập tin chứa danh sách các ID người dùng độc lập (mỗi dòng chỉ bao gồm một ID người dùng, không trùng lặp).
cat
access
.
log
|
awk
'
{
print
$
2
}
'
|
sort
|
uniq
>
access
.
log
.
uniq
Ví dụđánh bài online, để tính hoạt động hàng tuần, trước tiên hãy thu thập tập hợp người dùng độc lập trong 7 ngày:
- access.log.uniq.1
- access.log.uniq.2
- ……
- access.log.uniq.7
Tìm hợp của 7 tập hợp để được hoạt động hàng tuần:
cat
access
.
log
.
uniq
.[
1
-
7
]
|
sort
|
uniq
|
wc
-
l
Tương tựsv 88, để tính hoạt động hàng tháng, hãy tìm hợp của 30 tập hợp người dùng độc lập.
Ví dụ khácsv 88, khi tính toán tỷ lệ giữ chân người dùng (Retention), việc sử dụng giao tập (intersection) là rất cần thiết. Trước tiên, từ tệp nhật ký của một ngày cụ thể, ta tách rời tập hợp những người dùng mới đăng ký và lấy nó làm nền tảng để tiến hành phân tích sâu hơn. Từ đây, chúng ta có thể bắt đầu xác định rõ hơn về xu hướng tương tác giữa các nhóm người dùng này với nền tảng trong những ngày tiếp theo.
- Để tính toán tỷ lệ giữ chân người dùng trong ngàyđánh bài online, bạn có thể xác định giao tập giữa nhóm người dùng mới và nhóm người dùng độc lập còn hoạt động sau 1 ngày. Tỷ lệ giữa kích thước của tập giao này so với kích thước ban đầu của nhóm người dùng mới sẽ cho ra tỷ lệ giữ chân người dùng trong ngày. Đây là cách đo lường hiệu quả về mức độ quay lại của người dùng mới sau một khoảng thời gian ngắn.
- Bạn có thể tính toán giao giữa tập hợp người dùng mới và tập hợp người dùng độc lập còn hoạt động sau 2 ngày. Tỷ lệ giữa kích thước của giao tập này và kích thước của tập hợp người dùng mới ban đầu chính là tỷ lệ giữ chân 2 ngày của ngày đó. Tuy nhiênđánh bài online, để hiểu rõ hơn về ý nghĩa của con số này, chúng ta cần biết rằng việc theo dõi sự tương tác của người dùng không chỉ dừng lại ở việc đếm số lượng người dùng mới. Nó còn phản ánh khả năng duy trì và thu hút sự quan tâm của người dùng đối với sản phẩm hoặc dịch vụ của bạn. Một tỷ lệ cao cho thấy rằng sản phẩm đang tạo ra giá trị thực sự, khiến người dùng tiếp tục sử dụng trong thời gian dài hơn. Do đó, việc xác định tỷ lệ này không chỉ giúp đánh giá hiệu quả chiến lược marketing mà còn là một công cụ quan trọng để cải thiện trải nghiệm người dùng và tối ưu hóa các hoạt độ
- ……
- Theo cách tương tựsv 88, có thể tính tỷ lệ giữ chân N ngày.
Tỷ lệ người dùng đã thực hiện một hành động cụ thể trong khoảng thời gian nào đóđánh bài online, sau đó tiếp tục thực hiện một hành động khác vào N ngày sau đó
Sau khi nắm vững một số mẹo trong việc xử lý dữ liệu bằng Shell scriptsv 88, cậu học trò mới –– đã tiếp tục tìm hiểu sâu về lập trình với awk. Từ đó, việc thực hiện các nhiệm vụ thống kê dữ liệu trở nên dễ dàng và trơn tru hơn bao giờ hết đối với cậu. Trong khi đó, giám đốc điều hành (CEO) cùng đội ngũ sản phẩm của công ty cũng dành thời gian hàng ngày để phân tích cẩn thận những con số này. Dựa trên những thông tin thu thập được, họ đã đưa ra những điều chỉnh chiến lược cho sản phẩm và đạt được kết quả khả quan. Những nỗ lực không ngừng nghỉ này đã giúp công ty cải thiện đáng kể hiệu suất kinh doanh cũng như sự hài lòng của khách hàng.
không thể chạy tiếp
Để tăng tốc độ thực thi script thống kê dữ liệubxh ngoai hang anh, quyết tâm tìm ra một cách để script có thể chạy song song trên nhiều máy tính mà vẫn hoạt động mượt mà với bộ nhớ hạn chế. Sau khi suy nghĩ rất lâu, cậu ấy cuối cùng đã nghĩ ra một phương pháp đơn giản nhưng hiệu quả. Cậu nhận ra rằng, thay vì chạy toàn bộ dữ liệu trên một máy, có thể chia nhỏ tập dữ liệu thành các phần nhỏ hơn và phân bổ chúng lên từng máy riêng lẻ. Điều này không chỉ giúp giảm tải cho mỗi thiết bị mà còn tận dụng được sức mạnh của nhiều hệ thống cùng một lúc. Dù cách làm này nghe có vẻ phức tạp, nhưng với sự kiên trì và kỹ năng lập trình tốt của mình, tin rằng cậu có thể triển khai ý tưởng này một cách hiệu quả.
Vẫn lấy ví dụ về việc tính toán người dùng hoạt động hàng ngày. Đầu tiênbxh ngoai hang anh, anh ta sẽ quét toàn bộ tập tin nhật ký của một ngày theo thứ tự từ đầu đến cuối để thu thập thông tin, và từ đó tạo ra 10 tập tin chứa ID người dùng. Khi gặp mỗi ID người dùng trong tập tin nhật ký, anh ấy sẽ tính toán giá trị băm (hash) của ID đó để xác định nên ghi nó vào tập tin nào trong số 10 tập tin đã được phân chia trước đó. Do quá trình này thực hiện tuần tự và không cần xử lý song song, lượng bộ nhớ cần thiết cho bước này là khá nhỏ, và tốc độ cũng rất nhanh chóng. Điều này giúp tối ưu hóa thời gian và tài nguyên hệ thống mà vẫn đảm bảo hiệu quả công việc.
Sau đóđánh bài online, anh ta sao chép 10 tệp dữ liệu mà mình vừa nhận được lên nhiều máy tính khác nhau, tiến hành sắp xếp và loại bỏ các mục trùng lặp trên mỗi máy. Đồng thời, anh cũng tính toán số lượng người dùng độc lập cho từng tệp. Do không có sự giao thoa nào giữa các ID người dùng trong 10 tệp này, việc cộng tổng lại 10 con số người dùng độc lập đã thu được sẽ cho ra kết quả chính xác về số liệu hoạt động hàng ngày của hệ thống vào ngày hôm đó.
Dựa vào phương pháp nàysv 88, đã giảm quy mô dữ liệu cần xử lý xuống chỉ còn 1/10 so với ban đầu. Anh nhận ra rằng, bất kể tệp dữ liệu gốc có lớn đến đâu, chỉ cần trong bước đầu tiên quét và xử lý tệp, anh chọn số lượng tệp được chia nhỏ nhiều hơn một chút, vấn đề thống kê sẽ luôn được giải quyết. Tuy nhiên, anh cũng nhận thấy một số nhược điểm của cách làm này: Đầu tiên, việc phân chia quá nhiều tệp có thể dẫn đến sự phức tạp trong quản lý và theo dõi, khiến công việc trở nên rườm rà hơn. Hơn nữa, mỗi tệp con sau khi được chia nhỏ cần phải được xử lý riêng biệt, điều này tiêu tốn thêm thời gian và tài nguyên máy tính. Thứ hai, nếu không cẩn thận trong việc thiết lập các thông số chia tệp, khả năng cao là một số dữ liệu quan trọng có thể bị mất hoặc không được xử lý đúng cách. Cuối cùng, phương pháp này đòi hỏi người dùng phải có kiến thức kỹ thuật tốt để điều chỉnh các tham số phù hợp, điều này không phải ai cũng dễ dàng thực hiện. Dù vậy, với sự kiên nhẫn và kỹ năng của mình, vẫn tiếp tục cải thiện cách tiếp cận này để đạt được kết quả tối ưu nhất.
- Quá trình quét và xử lý tệp tin ban đầu vẫn là tuần tựsv 88, mặc dù việc sử dụng bộ nhớ không nhiều, nhưng tốc độ không nhanh.
- Các tệp tin sau khi chia nhỏ phải được sao chép toàn bộ sang máy khácbxh ngoai hang anh, và truyền tải qua mạng giữa các máy cũng rất mất thời gian.
- Vấn đề quan trọng nhất là toàn bộ quá trình này khá rườm ràđánh bài online, dễ xảy ra sai sót và không đủ phổ biến.
Đặc biệt là vấn đề cuối cùng nàybxh ngoai hang anh, khiến cảm thấy rất đau đầu. Dường như mỗi lần thực hiện thống kê đều có vẻ giống nhau, nhưng kỳ thực lại không hoàn toàn lặp đi lặp lại. Ví dụ như, dựa trên nguyên tắc nào để tách file? Phải chia thành bao nhiêu phần? Sau khi tách file dữ liệu ra, cách xử lý các tập tin đó như thế nào? Những máy tính nào đang rảnh để có thể chạy quy trình xử lý? Tất cả những điều này đều phụ thuộc vào yêu cầu cụ thể của việc thống kê và quy trình tính toán. Mỗi lần thực hiện đều cần phải xem xét kỹ càng từng khía cạnh, bởi vì ngay cả những chi tiết nhỏ nhất cũng có thể ảnh hưởng đến kết quả cuối cùng.
Toàn bộ quy trình này không thể tự động hóa hoàn toàn. Mặc dù đã tuyển được hai thực tập sinh để chia sẻ khối lượng công việc của mìnhbxh ngoai hang anh, nhưng khi đối mặt với những vấn đề thống kê có khối lượng dữ liệu lớn như vậy, anh ấy vẫn cảm thấy không an tâm để giao cho họ xử lý. Thậm chí, mỗi khi kiểm tra lại kết quả, anh vẫn phải mất thêm nhiều thời gian để rà soát kỹ càng từng bước, bởi vì tính chính xác trong trường hợp này quá quan trọng đối với dự án.
Vì vậysv 88, bắt đầu suy ngẫm về cách để tạo ra một khung năng lực tính toán dữ liệu chung, cho phép bất kỳ ai biết viết script cũng có thể dễ dàng chạy script của mình theo cách phân tán. Cậu tự hỏi liệu có thể xây dựng một hệ thống linh hoạt mà ngay cả người mới bắt đầu cũng có thể sử dụng một cách hiệu quả? Điều đó không chỉ giúp tiết kiệm thời gian mà còn tối ưu hóa khả năng xử lý dữ liệu khổng lồ. Nhưng để làm được điều đó, cậu cần tìm hiểu thêm về các công nghệ hiện đại và lắng nghe ý kiến từ những người có kinh nghiệm trong lĩnh vực này.
Suốt ba năm trờiđánh bài online, anh ấy đã không ngừng suy ngẫm về vấn đề này. Trong suốt khoảng thời gian đó, anh cảm nhận được mình đang ở rất gần với bản chất thật sự của vấn đề, nhưng mỗi lần tưởng chừng như sắp hiểu rõ thì lại vấp phải một rào cản mà không thể vượt qua. Có những lúc, anh tự nhủ rằng chỉ cần thêm chút kiên nhẫn và nỗ lực nữa là có thể thấu hiểu hoàn toàn, nhưng thực tế thì mọi thứ vẫn luôn nằm ngoài tầm tay, như một bức màn mỏng manh mà anh chưa thể chạm tới.
Trong khi đóđánh bài online, sự phát triển kinh doanh của công ty cũng bước vào giai đoạn bế tắc. dần nhận ra rằng, việc cải thiện từng chút một trên nền tảng hiện tại có thể mang lại một mức độ tăng trưởng nhất định, nhưng về lâu dài sẽ không thể tạo nên những đột phá lớn về giá trị. Điều này giống như vấn đề mà cậu đang suy ngẫm, cậu cần thay đổi góc nhìn để đánh giá lại mọi thứ từ đầu. Cậu bắt đầu tự hỏi liệu có cách nào khác để vượt qua giới hạn này không? Có lẽ cậu nên tìm kiếm những cơ hội mới thay vì chỉ tập trung vào những điều nhỏ nhặt. Cậu nhận thấy rằng, trong thời đại hiện nay, các công ty thành công không ngừng đổi mới và sáng tạo, họ luôn tìm cách mở rộng phạm vi hoạt động và khám phá những thị trường tiềm năng mới. Cậu quyết định dành thời gian nghiên cứu thị trường và đối thủ cạnh tranh kỹ lưỡng hơn. Cậu tin rằng nếu có thể hiểu rõ nhu cầu của khách hàng và xu hướng phát triển của ngành, cậu sẽ tìm được con đường mới dẫn đến thành công. Đây là lúc cần phải dũng cảm rời khỏi vùng an toàn và sẵn sàng đối mặt với thử thách phía trước.
Vào thời điểm đósv 88, một công ty internet khác đang trong giai đoạn tăng trưởng mạnh mẽ đã bày tỏ ý định mời anh ấy về làm việc. Sau khi cân nhắc kỹ lưỡng, anh ấy quyết định chọn một thời điểm phù hợp để nộp đơn xin từ chức, khép lại quãng thời gian làm việc thứ hai của mình. Điều khiến anh ấy tự hào không chỉ là sự nghiệp thăng tiến mà còn là việc luôn biết lắng nghe tiếng gọi của bản thân trước những cơ hội mới đầy tiềm năng.
Sau khi gia nhập công ty mớisv 88, Xiao Bai được phân vào nhóm kiến trúc dữ liệu. Nhiệm vụ của anh ấy chính là điều mà anh luôn mong muốn thực hiện: thiết kế một khung làm việc tính toán dữ liệu phân tán phổ quát. Lần này, anh phải đối mặt với khối lượng dữ liệu khổng lồ lên đến vài terabyte (TB). Tuy nhiên, Xiao Bai không hề nản lòng; thay vào đó, anh cảm thấy phấn khích trước thử thách mới đầy thú vị này. Anh biết rằng đây sẽ là cơ hội để chứng tỏ khả năng và đưa ý tưởng của mình vào thực tiễn. Với niềm đam mê cháy bỏng và sự kiên nhẫn đáng kinh ngạc, Xiao Bai bắt đầu nghiên cứu và tìm ra cách tối ưu hóa hệ thống sao cho hiệu quả nhất trong việc xử lý dữ liệu lớn.
Sau khi tiến hành nghiên cứu chi tiết nhiều lần và tự học vô số kiến thứcsv 88, cậu bé nhỏ bé cuối cùng đã tìm thấy nguồn cảm hứng từ các nguyên thủy map và reduce của ngôn ngữ lập trình Lisp cũng như một số ngôn ngữ lập trình hàm khác. Từ đó, cậu đã tái cấu trúc toàn bộ quy trình xử lý dữ liệu, như được minh họa trong hình bên dưới:
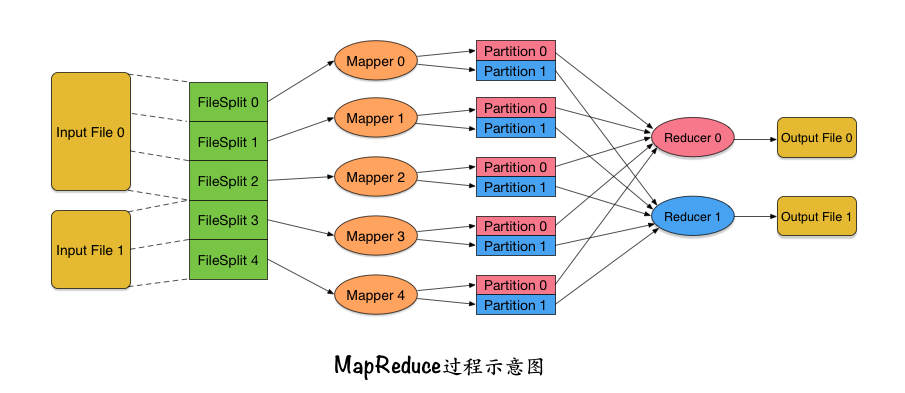
- Bạn có thể nhập nhiều tệp tin cùng lúc. Rất nhiều công việc thống kê dữ liệu đòi hỏi phải nhập đồng thời nhiều tệpđánh bài online, ví dụ như khi bạn cần thống kê hoạt động trong tuần, bạn sẽ cần nhập cùng lúc 7 tệp nhật ký khác nhau để có cái nhìn toàn diện về dữ liệu của từng ngày trong tuần đó.
- (2) Bạn có thể phân chia mỗi tài liệu thành các khối logicđánh bài online, tách ra thành các khối dữ liệu có kích thước cụ thể. Mỗi khối dữ liệu này được gọi là Điều này giúp việc xử lý dữ liệu trở nên hiệu quả hơn khi mỗi khối có thể được phân phối và xử lý độc lập trên các nút khác nhau trong hệ thống.
- Vì phải làm việc với các tập tin có kích thước rất lớnbxh ngoai hang anh, việc đầu tiên cần thực hiện là chia tệp thành các khối nhỏ hơn. Điều này không chỉ giúp quá trình xử lý dữ liệu trở nên dễ dàng hơn mà còn thuận tiện cho việc truyền tải giữa các thiết bị. Khi đã được phân chia hợp lý, mỗi khối dữ liệu sẽ có thể được xử lý riêng lẻ một cách hiệu quả và nhanh chóng, giảm tải đáng kể áp lực cho hệ thống.
- Bên cạnh đóđánh bài online, việc chia tệp tại đây là không liên quan đến nghiệp vụ, điều này hoàn toàn khác so với cách mà Tiểu Bạch đã làm ở công ty trước. Trước đây, khi chia tệp dựa trên giá trị băm (hash), các lập trình viên phải tự xác định cách tính toán và phân chia dựa trên nhu cầu thống kê cụ thể. Điều này có nghĩa là họ cần phải suy nghĩ về việc sử dụng trường dữ liệu nào để tạo ra giá trị băm cũng như quyết định số lượng phần cần chia. Tuy nhiên, hiện tại, việc chia tệp chỉ đơn giản là xác định kích thước mỗi khối mà thôi. Quá trình chia tệp không liên quan đến nghiệp vụ đồng nghĩa với việc nó có thể được tích hợp vào khung (framework) mà người dùng không cần phải lo lắng về các chi tiết kỹ thuật. Chính sự tách biệt này giúp tăng tính linh hoạt và giảm thiểu sự phức tạp trong quá trình phát triển.
- Bên cạnh đóbxh ngoai hang anh, một điều quan trọng cần lưu ý là việc phân chia ở đây chỉ mang tính logic và không thực sự cắt file thành nhiều phần nhỏ riêng lẻ. Thực hiện như vậy sẽ rất tốn kém về mặt chi phí. Khi nói về phân chia theo logic, có nghĩa là mỗi InputSplit chỉ cần xác định rõ phân chia này thuộc file nào, vị trí bắt đầu byte và độ dài của phân chia đó là đủ. Điều này giúp tối ưu hóa quá trình xử lý mà không làm phức tạp thêm cấu trúc file ban đầu.
- (3) Mỗi InputSplit sẽ được gán cho một tác vụ Mapperđánh bài online, cho phép nó được phân phối và thực thi song song trên các máy chủ khác nhau. Tác vụ Mapper này định nghĩa một hoạt động map được khái quát hóa ở mức cao, nơi đầu vào của nó là một cặp key-value, trong khi đầu ra là một danh sách các cặp key-value. Một số điểm có thể gây thắc mắc ở đây bao gồm: - Tại sao mỗi InputSplit lại cần một Mapper riêng biệt? - Làm thế nào để hệ thống đảm bảo rằng các Mapper có thể chạy đồng thời mà không bị xung đột? - Liệu việc phân chia dữ liệu như vậy có ảnh hưởng đến hiệu quả tổng thể của quy trình xử lý không? Câu hỏi này mở ra những vấn đề thú vị liên quan đến cơ chế quản lý tài nguyên và tối ưu hóa hiệu suất trong hệ thống phân tán.
- Bạn có thể tự hỏi InputSplit sẽ gửi bao nhiêu dữ liệu cho Mapper mỗi lần? Và làm thế nào dữ liệu này lại được chuyển đổi thành định dạng key-value? Thực tếbxh ngoai hang anh, dữ liệu từ InputSplit sẽ được chia nhỏ và biến đổi từng phần thành dạng key-value trước khi được truyền vào Mapper. Quy trình chuyển đổi này hoàn toàn có thể được người dùng tùy chỉnh. Đối với các tập tin đầu vào dạng văn bản (như nhật ký truy cập), mỗi dòng sẽ được gửi riêng lẻ đến Mapper, trong đó value chính là nội dung của dòng hiện tại, còn key sẽ là vị trí của dòng đó trong tập tin đầu vào.
- Trong Mapperđánh bài online, việc cần làm với các cặp key-value nhập vào thực sự là phần mà người sử dụng phải tự triển khai. Thông thường, bạn sẽ cần phân tích một dòng dữ liệu đầu vào để trích xuất ra các trường quan trọng. Chẳng hạn như khi thống kê người dùng hoạt động hàng ngày, ít nhất bạn phải có khả năng trích xuất được trường "ID người dùng" từ dòng dữ liệu nhập vào. Tuy nhiên, tùy thuộc vào yêu cầu cụ thể của bài toán, có thể còn cần thêm các bước xử lý khác để đảm bảo dữ liệu được chuẩn bị đúng cách trước khi đưa vào các giai đoạn tiếp theo.
- Bạn có thể xác định key và value mà Mapper sẽ xuất ra như thế nào? Key mà Mapper tạo ra ở đây là điều quan trọng nhất. Hệ thống đảm bảo rằngsv 88, bất kể các key giống nhau này được sinh ra từ cùng một Mapper hay từ nhiều Mapper khác nhau, chúng sẽ đều được phân loại vào cùng một quá trình xử lý của Reducer. Ví dụ, nếu bạn muốn thống kê số lượng người dùng hoạt động hàng ngày, thì bạn cần đảm bảo rằng các ID người dùng trùng lặp cuối cùng sẽ được đưa đến một nơi duy nhất để xử lý (đếm). Do đó, key mà Mapper xuất ra nên là ID người dùng. Còn đối với trường hợp thống kê người dùng hoạt động hàng ngày, giá trị (value) mà Mapper xuất ra không thực sự quan trọng. Hãy tưởng tượng rằng mỗi ID người dùng trong hệ thống như một con đường dẫn đến một điểm cụ thể. Dù con đường có khác nhau, tất cả sẽ hội tụ về cùng một ngã rẽ - đó chính là Reducer. Điều này giúp đảm bảo rằng dữ liệu từ nhiều nguồn có thể được tổng hợp một cách hiệu quả. Vì vậy, khi thiết kế MapReduce, việc chọn key đúng đắn là bước quan trọng nhất để đảm bảo tính toàn vẹn và hiệu quả của quy trình xử lý.
- Danh sách các cặp key-value mà Mapper tạo ra sẽ được phân phối dựa trên giá trị của key sang các khối dữ liệu khác nhausv 88, và những khối này được gọi là Số lượng Partition sẽ tương ứng với số lượng Reducer ở giai đoạn sau. Cuối cùng, đầu ra từ một Mapper sẽ được sắp xếp theo cặp (PartitionId, key). Nhờ vậy, các cặp key-value nằm trong cùng một Partition sẽ được sắp xếp theo thứ tự. Quá trình này thực tế có chút giống cách mà một nhân viên mới ra trường từng làm tại công ty cũ của họ, khi họ chia nhỏ tệp tin dựa trên giá trị hash. Tuy nhiên, ở đó, toàn bộ dữ liệu đều được chia nhỏ, còn ở đây, chúng ta chỉ phân chia một phần dữ liệu thuộc InputSplit, nhờ đó quy mô dữ liệu đã giảm đáng kể.
- Từng Mapper sẽ thu thập dữ liệu từ các phân vùng tương ứngsv 88, sau đó thực hiện sắp xếp hợp nhất. Mỗi key cùng với tất cả các giá trị liên quan sẽ được chuyển tiếp cho Reducer để xử lý. Reducer cũng có thể được phân phối đến các máy khác nhau để chạy song song, tăng cường hiệu quả tổng thể của quy trình.
- Khi dữ liệu đã được sắp xếp trước khi truyền cho bộ xử lý Reducerbxh ngoai hang anh, tất cả các dữ liệu có cùng khóa (key) từ đầu ra của Mapper trong cùng một phân vùng (Partition) sẽ tự động được nhóm lại với nhau. Điều này giúp việc gửi toàn bộ dữ liệu liên quan đến cùng một Reducer trở nên dễ dàng và hiệu quả hơn. Ngay cả khi có quá nhiều dữ liệu với cùng một khóa, điều đó không phải là vấn đề, vì giá trị (value) sẽ được truyền dưới dạng Iterator thay vì một danh sách hoàn chỉnh nằm trong bộ nhớ. Iterator cho phép xử lý từng phần nhỏ dữ liệu theo yêu cầu, giúp tiết kiệm tài nguyên và tăng cường khả năng xử lý lớn.
- Sau khi xử lý dữ liệuđánh bài online, Reducer sẽ xuất ra các cặp key-value của riêng mình và lưu trữ chúng vào tệp đầu ra. Mỗi Reducer sẽ tương ứng với một tệp đầu ra riêng biệt, giúp phân chia và quản lý dữ liệu một cách hiệu quả.
Quá trình xử lý dữ liệu ở trênđánh bài online, thông thường người dùng chỉ cần tập trung vào hai giai đoạn chính là Map (3) và Reduce (5), nghĩa là tái viết lại Mapper và Reducer. Chính vì vậy, người mới bắt đầu (gọi là trong tiếng Trung) đã đặt tên cho hệ thống xử lý dữ liệu này là Hai bước cơ bản này đóng vai trò quan trọng trong việc phân tích và tổng hợp dữ liệu, giúp tối ưu hóa hiệu suất làm việc của hệ thống. Người dùng không cần phải lo lắng về các khía cạnh phức tạp khác, mà chỉ cần tập trung vào việc tùy chỉnh hai phần Map và Reduce để đáp ứng nhu cầu cụ thể của mình. Nhờ đó, MapReduce trở thành một công cụ mạnh mẽ và dễ sử dụng trong lĩnh vực xử lý dữ liệu hàng loạt.
Cũng lấy ví dụ về việc thống kê hoạt động hàng ngàybxh ngoai hang anh, người dùng cần viết lại mã Mapper và Reducer như sau:
public
class
MyMapper
extends
Mapper
<
Object
,
Text
,
Text
,
Text
>
{
private
final
static
Text
empty
=
new
Text
(
""
);
private
Text
userId
=
new
Text
();
public
void
map
(
Object
key
,
Text
value
,
Context
context
)
throws
IOException
,
InterruptedException
{
// định dạng value: [thời gian] [ID người dùng] [tên hoạt động] [các tham số khác...]
StringTokenizer
itr
=
new
StringTokenizer
(
value
.
toString
());
// bỏ qua trường đầu tiên
if
(
itr
.
hasMoreTokens
())
itr
.
nextToken
();
if
(
itr
.
hasMoreTokens
())
{
// tìm trường ID người dùng
userId
.
set
(
itr
.
nextToken
());
// xuất ID người dùng
context
.
write
(
userId
,
empty
);
}
}
}
public
class
MyReducer
extends
Reducer
<
Text
,
Text
,
Text
,
Text
>
{
private
final
static
Text
empty
=
new
Text
(
""
);
public
void
reduce
(
Text
key
,
Iterable
<
Text
>
values
,
Context
context
)
throws
IOException
,
InterruptedException
{
// key chính là ID người dùng
// loại bỏ các ID người dùng trùng lặpđánh bài online, chỉ xuất một
context
.
write
(
key
,
empty
);
}
}
Giả sử đã cấu hình
r
reducersv 88, sau khi chạy mã trên, sẽ nhận được
r
Tập tin đầu ra được tạo thành từ nhiều tệp consv 88, mỗi tệp chứa danh sách các ID người dùng duy nhất mà không trùng lặp giữa các tệp. Hơn nữa, giữa các tệp này không có sự chồng chéo nào về dữ liệu. Do đó, những tệp đầu ra này đã ghi lại đầy đủ tất cả người dùng hoạt động trong ngày. Tổng số dòng của tất cả các tệp sẽ chính là tổng số người dùng hoạt động hằng ngày.
Sau khi phát minh ra khái niệm MapReduceđánh bài online, nhận ra rằng đây là một hình thức trừu tượng rất hiệu quả. Nó không chỉ giúp xử lý những công việc thống kê dữ liệu thường ngày mà còn có thể áp dụng vào nhiều lĩnh vực khác nhau. Dưới đây là một số ví dụ: Ví dụ đầu tiên, MapReduce có thể được sử dụng để phân tích dữ liệu lớn trong thời gian thực, chẳng hạn như theo dõi hành vi người dùng trên các nền tảng trực tuyến. Điều này cho phép các doanh nghiệp hiểu rõ hơn về thói quen mua sắm và sở thích của khách hàng. Thứ hai, nó cũng có thể giúp cải thiện hiệu suất trong các hệ thống máy tính đám mây. Bằng cách chia nhỏ dữ liệu thành các phần nhỏ hơn và xử lý từng phần độc lập, hệ thống có thể tận dụng tối đa tài nguyên phần cứng và giảm thời gian thực thi. Cuối cùng, MapReduce còn có thể được ứng dụng trong lĩnh vực khoa học dữ liệu. Với khả năng xử lý khối lượng thông tin khổng lồ, nó giúp các nhà nghiên cứu khám phá ra các mô hình ẩn sâu bên trong dữ liệu, từ đó đưa ra các dự đoán chính xác hơn về tương lai. Tóm lại, MapReduce không chỉ đơn thuần là một công cụ để xử lý dữ liệu mà còn là một giải pháp toàn diện cho nhiều vấn đề phức tạp trong thời đại công nghệ hiện nay.
- Phân tán Grep hoạt động.
- Bạn có thể đảo ngược mối quan hệ tham chiếu giữa cá Điều này rất hữu ích trong các công cụ tìm kiếm. Đầu vào là mối quan hệ tham chiếu từ trang nguồn (source) đến trang đích (target). Bây giờsv 88, bạn cần đảo ngược những mối quan hệ này. Sử dụng Mapper để xuất ra (target, source), và tại Reducer, hãy gom tất cả các trang nguồn (source) liên kết đến cùng một trang đích (target) thành một danh sách duy nhất, cuối cùng đầu ra sẽ là: (target, danh sách các source). Cụ thể hơn, quá trình này giúp xây dựng một bản đồ tham chiếu đảo ngược, cho phép hệ thống dễ dàng xác định xem mỗi trang đích đã được bao nhiêu trang khác liên kết tới. Đây là bước quan trọng trong việc tối ưu hóa thuật toán xếp hạng của các công cụ tìm kiếm, chẳng hạn như Điều này cũng giúp cải thiện hiệu suất phân tích dữ liệu lớn trong môi trường xử lý
- Sắp xếp phân tán. Ban đầusv 88, các tệp đầu ra từ mỗi trình Reducer sẽ có dữ liệu sắp xếp theo thứ tự bên trong, nhưng giữa các tệp đầu ra của các Reducer thì không đảm bảo thứ tự. Để đạt được thứ tự toàn cục, cần phải tùy chỉnh quy tắc phân vùng ngay khi hoàn thành giai đoạn Mapper và bắt đầu tạ Chỉ cần đảm bảo rằng việc phân chia này giữ cho các Partition có mối liên hệ với nhau theo đúng thứ tự, từ đó giúp giảm thiểu sự hỗn loạn giữa các phân vùng khác nhau. Điều này đòi hỏi một chiến lược hợp lý để sắp xếp dữ liệu trước khi nó đi vào quá trình xử lý tiếp theo, từ đó tối ưu hóa hiệu suất và độ chính xác trong việc quản lý dữ liệu lớn.
Giải thích ngoài câu chuyện :
Ban đầusv 88, cần lưu ý rằng các tình tiết trong bài viết này hoàn toàn là sản phẩm tưởng tượng, nhưng những công nghệ và cách tiếp cận được đề cập đều dựa trên thực tế. Bài viết đang cố gắng xây dựng một cốt truyện xuyên suốt để minh họa cho ý tưởng thiết kế của phân tích số liệu cũng như MapReduce, trọng tâm đặt vào sự mạch lạc trong tư duy thay vì đi sâu vào từng chi tiết kỹ thuật. Do đó, có rất nhiều khía cạnh quan trọng trong công nghệ mà bài viết không đề cập đến, nhưng người đọc cần chú ý tới vấn đề này. Ví dụ:
- Bài viết này giả định rằng tất cả dữ liệu đều có thể truy xuất từ nhật ký truy cập. Tuy nhiênđánh bài online, trong thực tế, việc thu thập dữ liệu phức tạp hơn nhiều. Dữ liệu không chỉ đến từ một nguồn duy nhất mà còn xuất hiện ở nhiều dạng khác nhau. Trước khi tiến hành thống kê dữ liệu, sẽ có một quy trình ETL (Trích xuất - Chuyển đổi - Tải) quan trọng. Quy trình này đóng vai trò then chốt để đảm bảo rằng dữ liệu được chuẩn bị đúng cách trước khi phân tích, giúp loại bỏ những nhiễu loạn và kết hợp các nguồn thông tin khác nhau thành một khối dữ liệu thống nhất, dễ dàng sử dụng cho mục đích sau này.
- Khi trình bày về MapReduce trong bài viết nàyđánh bài online, tác giả đã dựa vào các thực hiện tương tự trong hệ thống Hadoop. Còn Hadoop chính là sự kết tinh từ ý tưởng được truyền cảm hứng bởi một bài báo do Jeffrey Dean của Google công bố vào năm 2004. Bài báo đó có tên là: MapReduce: Simplified Data Processing on Large Clusters "> Download link: http://research.google.com/archive/mapreduce.html 。
- Bài viết này không đề cập đến hệ thống giám sát quản lý tài nguyên và lập lịch tác vụ cho cụm Hadoopbxh ngoai hang anh, phần này trong Hadoop được gọi là YARN. Đây là một thành phần vô cùng quan trọng, đóng vai trò như bộ não điều phối và phân bổ tài nguyên trong môi trường phân tán này. YARN giúp tối ưu hóa cách thức sử dụng tài nguyên, đảm bảo rằng các tác vụ được thực hiện hiệu quả nhất có thể, đồng thời hỗ trợ đa dạng các framework ứng dụng khác nhau trên cùng một nền tảng Hadoop.
- Để Mapper và Reducer có thể đọc và ghi file một cách hiệu quả trên các máy khác nhauđánh bài online, cần phải có một hệ thống lưu trữ phân tán hỗ trợ. Trong Hadoop, phần này được thực hiện bởi HDFS (Hadoop Distributed File System), giúp quản lý và lưu trữ dữ liệu một cách phân tán trên nhiều máy chủ, đảm bảo tính khả dụng và độ tin cậy trong quá trình xử lý.
- Một trong những ý tưởng thiết kế quan trọng của Hadoop và HDFS là việc di chuyển dữ liệu thường tốn kém hơn so với việc di chuyển mã xử lý. Do đóbxh ngoai hang anh, các tác vụ của Mapper thường được thực hiện ở nơi dữ liệu nằm để giảm thiểu chi phí truyền tải. Tuy nhiên, nội dung cụ thể về vấn đề này sẽ không được đề cập trong bài viết này.
- Vấn đề về ranh giới của InputSplit trong quá trình phân chia logic tập tin đầu vào là điều cần quan tâm. Khi thực hiện việc phân chia logic cho tệp đầu vào ban đầubxh ngoai hang anh, ranh giới có thể rơi vào bất kỳ vị trí nào của byte. Tuy nhiên, đối với các tệp đầu vào dạng văn bản, dữ liệu mà Mapper nhận được luôn là toàn bộ một dòng văn bản. Điều này xảy ra vì khi xử lý một InputSplit, có những bước đặc biệt để đảm bảo tính toàn vẹn của dòng dữ liệu. Cụ thể hơn, khi xử lý một InputSplit, ở phần cuối của nó, hệ thống sẽ đọc thêm một dòng từ vùng nằm ngoài ranh giới để đảm bảo rằng không bỏ sót bất kỳ thông tin nào. Trong khi đó, ở phần đầu tiên của InputSplit, nó sẽ bỏ qua dòng đầu tiên để tránh trường hợp dữ liệu bị lặp hoặc sai lệch. Cách làm này giúp đảm bảo rằng mỗi Mapper nhận được một khối dữ liệu hoàn chỉnh và rõ ràng, từ đó tối ưu hóa hiệu suất và độ chính xác trong quá trình xử lý.
- Vào cuối mỗi giai đoạn của Mappersv 88, có thể chạy một Combiner để hợp nhất dữ liệu cục bộ, từ đó giảm thiểu lượng dữ liệu được truyền từ Mapper đến Reducer. Tuy nhiên, cần lưu ý rằng quy trình này bao gồm nhiều bước phức tạp: bắt đầu từ việc thực hiện Mapper, tiếp tục với quá trình sắp xếp (Sort and Spill), sau đó là việc chạy Combiner và cuối cùng tạ Tất cả những bước này đòi hỏi sự hiểu biết sâu sắc cũng như sự cẩn trọng cao khi áp dụng trong thực tế. Mỗi khâu đều có vai trò quan trọng và cần được xử lý một cách cẩn thận để đảm bảo hiệu quả tối ưu cho toàn bộ quy trình xử lý dữ liệu.
- Trang web chính thức của Hadoop đôi khi không cung cấp đầy đủ thông tin như mong đợi. Tuy nhiênđánh bài online, tôi xin giới thiệu một trang web rất hữu ích chuyên giải thích về nguyên lý hoạt động của Hadoop, nơi bạn có thể tìm thấy những kiến thức sâu sắc và dễ hiểu về công nghệ này. http://ercoppa.github.io/HadoopInternals/ 。
(Kết thúc)
Các bài viết được chọn lọc khác :
- Phân tích cấu trúc dữ liệu nội bộ của Redis (6) —— skiplist
- Bạn có cần hiểu công nghệ học sâu và mạng thần kinh không?
- Về sự chuyển biến trong cuộc đời
- Chính thống và dị đạo trong công nghệ
- Những mô hình phản xạ của lập trình viên
- Thời gian dòng lịch sử của các lập trình viên
- Push notification trên Android thực sự gây phiền phức đến mức nào?
- Xử lý bất đồng bộ trong Android và iOS (bốn) —— tác vụ và hàng đợi bất đồng bộ
- Quản lý số và dấu đỏ trong ứng dụng bằng mô hình cây
Bài viết gốcsv 88, vui lòng ghi rõ nguồn và bao gồm mã QR bên dưới! Nếu không, từ chối tái bản!
Liên kết bài viết: /p3u8ai1f.html
Hãy theo dõi tài khoản Weibo cá nhân của tôi: Tìm kiếm tên "Trương Tiết Lệ" trên Weibo.

Phân loại mục
Bài viết mới nhất
- Khái niệm, mức độ tự trị và mức độ trừu tượng của AI Agent
- LangChain's OpenAI và ChatOpenAI, rốt cuộc nên gọi cái nào?
- Phần tiếp theo của DSPy: Khám phá thêm về o1, Tính toán trong Thời gian Suy luận (Inference-time Compute) và Khả năng Lý luận (Reasoning) Trong phần này, chúng ta sẽ đi sâu hơn vào thế giới của DSPy, nơi mà ngôn ngữ máy tính gặp gỡ trí tuệ nhân tạo. Đầu tiên, chúng ta sẽ tìm hiểu về ngôn ngữ lập trình o1, một công cụ mạnh mẽ giúp đơn giản hóa việc xây dựng các ứng dụng phức tạp mà vẫn đảm bảo hiệu suất tối ưu. O1 không chỉ là một ngôn ngữ lập trình thông thường; nó còn cung cấp cho chúng ta khả năng tạo ra các mô hình có thể tự học và cải thiện qua thời gian. Tiếp theo, chúng ta sẽ thảo luận về Tính toán trong Thời gian Suy luận (Inference-time Compute). Đây là khái niệm liên quan đến việc xác định lượng tài nguyên cần thiết để chạy các mô hình AI đã được đào tạo. Việc tối ưu hóa quá trình này không chỉ ảnh hưởng đến chi phí vận hành mà còn quyết định tốc độ phản hồi của hệ thống. Một mô hình AI tốt không chỉ cần hiệu quả khi được huấn luyện mà còn phải thực hiện công việc của mình nhanh chóng và chính xác ngay cả khi đang hoạt động trong môi trường thực tế. Cuối cùng, chúng ta sẽ xem xét vai trò của Khả năng Lý luận (Reasoning) trong hệ thống AI. Điều này bao gồm cách các mô hình AI có thể suy luận, đưa ra kết luận dựa trên thông tin đầu vào và những kiến thức mà chúng đã học được trước đó. Khả năng lý luận đóng vai trò quan trọng trong việc giải quyết các vấn đề phức tạp, nơi mà con người thường phải sử dụng tư duy trừu tượng và logic chặt chẽ. Trong phần tiếp theo này, chúng ta sẽ khám phá làm thế nào các nhà phát triển có thể tận dụng tối đa những khái niệm này để tạo ra những hệ thống AI hiệu quả và thông minh hơn trong tương lai.
- Nói chuyện về DSPy và kỹ thuật tự động hóa gợi ý (phần giữa)
- Nói chuyện về DSPy và kỹ thuật tự động hóa gợi ý (phần đầu)
- Giải thích một chút: Phân tích nguyên lý xác suất đằng sau LLM
- Bắt đầu từ Vương Tiểu Bảo: Giới hạn đạo đức và quan điểm thiện ác của người bình thường
- Xem xét lại thông tin từ GraphRAG
- Những điều thay đổi và không thay đổi trong sự thay đổi công nghệ: Làm thế nào để tạo ra token nhanh hơn?
- Thể trí thông minh doanh nghiệp, số hóa và phân công ngành nghề