Làm thế nào để miêu tả hình ảnh cơ chế backpressure và điều khiển dò
2016-12-15
Trước đây99WIN, tôi đã được mời trả lời một câu hỏi trên Zhihu về cơ chế Backpressure (áp lực ngược) của RxJava. Hôm nay, tôi quyết định sắp xếp lại những gì đã chia sẻ đó, với hy vọng có thể giúp ích cho nhiều người hơn nữa.
Khi một chuỗi phát sinh dữ liệu với tốc độ cao hơn khả năng xử lý của người nhận99WIN, Backpressure sẽ hoạt động như một cơ chế điều hòa tự nhiên. Nó thông báo cho nguồn dữ liệu về khả năng tiếp nhận của người nhận, từ đó điều chỉnh tốc độ phát sinh dữ liệu để tránh tình trạng quá tải. Điều này giúp duy trì tính ổn định và hiệu quả trong các ứng dụng thời gian thực.
Tuy nhiênđánh bài online, vì tiêu đề bài viết này đặt mục tiêu “miêu tả sinh động” các cơ chế, nên chắc chắn sẽ cố gắng giữ cho ngôn ngữ thật súc tích, dễ hiểu ngay từ cái nhìn đầu tiên. Vì vậy, trong phần dưới đây, tôi sẽ cố gắng loại bỏ những khái niệm trừu tượng rườm rà và chủ yếu sử dụng cách so sánh để trình bày cách hiểu của mình về những cơ chế này.
Đầu tiênđánh bài online, xét ở góc độ tổng quan, tiêu đề của tài liệu trên, mặc dù được gọi là "Backpressure" (áp lực ngược), nhưng thực chất đang đề cập đến một chủ đề rộng hơn rất nhiều — "Flow Control" (điều khiển dòng chảy). Backpressure chỉ là một trong những giải pháp của Flow Control mà thôi. Trong thế giới lập trình và hệ thống phân tán, Flow Control đóng vai trò cực kỳ quan trọng để đảm bảo rằng dữ liệu không bị tràn hoặc mất kiểm soát giữa các thành phần khác nhau. Backpressure, với vai trò như một cơ chế tự điều chỉnh, giúp hệ thống duy trì sự cân bằng và hiệu quả, đặc biệt khi có sự chênh lệch về tốc độ xử lý giữa các bộ phận. Đây là cách mà Backpressure góp phần làm cho Flow Control trở nên hiệu quả hơn trong việc quản lý lưu lượng thông tin.
Trong RxJavađánh bài online, bạn có thể tạo thành một chuỗi gọi (call chain) bằng cách liên tục áp dụng nhiều Operator lên đối tượ Quá trình này cho phép dữ liệu được truyền từ phía nguồn (upstream) đến phía người dùng (downstream). Tuy nhiên, khi tốc độ gửi dữ liệu từ nguồn nhanh hơn tốc độ xử lý của bên nhận, vấn đề về quản lý luồng dữ liệu (flow control) sẽ xuất hiện và cần được giải quyết kịp thời.
Điều này giống như một bài toán toán học mà bạn từng làm ở tiểu học: có một hồ nước99WIN, một bên có vòi cấp nước và một bên có vòi xả nước. Nếu lượng nước từ vòi cấp nước lớn hơn, sau một khoảng thời gian hồ sẽ đầy (và tràn ra ngoài). Đây chính là hậu quả của việc thiếu đi sự kiểm soát dòng chảy (flow control). Có thể nói thêm rằng, trong cuộc sống thực tế, tình huống này xảy ra khá thường xuyên. Ví dụ, khi một hệ thống máy tính nhận dữ liệu với tốc độ quá nhanh mà không có cơ chế điều chỉnh hợp lý, nó cũng có thể bị quá tải hoặc mất dữ liệu. Điều này cho thấy tầm quan trọng của việc thiết lập các quy tắc và giới hạn để đảm bảo mọi thứ hoạt động một cách ổn định và hiệu quả nhất.
Flow Control có những ý tưởng gì? Có khoảng bốn cách chính:
- (1) Backpressure (Phản áp).
- (2) Throttling (Kìm hãm).
- (3) Xử lý theo lô.
- (4) Khóa gọi hàm (Callstack blocking).
Dưới đây sẽ giới thiệu chi tiết từng loại.
Hiện tạikeo nha cai hom nay, hai phiên bản RxJava 1.x và 2.x đang cùng tồn tại song song, trong đó phiên bản 2.x có những thay đổi đáng kể về giao diện so với phiên bản 1.x, bao gồm cả các khía cạnh liên quan đế Tuy nhiên, các khái niệm về cơ chế kiểm soát luồng (Flow Control) mà chúng ta sẽ thảo luận ở đây đều có tính ứng dụng chung cho cả hai phiên bản này. Dù vậy, khi làm việc với RxJava 2.x, bạn cần lưu ý rằng các phương thức và cách tiếp cận đã được tối ưu hóa để giải quyết các vấn đề phức tạp hơn mà trước đây trong RxJava 1.x chưa được giải quyết triệt để. Điều này đòi hỏi bạn phải hiểu rõ sự khác biệt giữa hai phiên bản để áp dụng đúng vào từng ngữ cảnh cụ thể.
Một số ý tưởng về Flow Control
Backpressure (Phản áp)
Lực kéo phản ứng
Loại giải pháp này chỉ áp dụng cho các quan sát (Observable) được gọi là "cold Observable". Cold Observable đề cập đến nguồn dữ liệu có thể điều chỉnh tốc độ gửi thông tinđánh bài online, ví dụ như việc truyền một tập tin giữa hai máy tính. Tốc độ truyền có thể thay đổi linh hoạt, từ nhanh đến rất chậm, thậm chí giảm xuống chỉ vài byte mỗi giây, nhưng miễn là thời gian đủ dài, việc truyền tải vẫn sẽ hoàn thành. Ngược lại, các trường hợp như phát trực tiếp âm thanh và video thì khác biệt hoàn toàn. Ở đây, nếu tốc độ dữ liệu dưới một giá trị cụ thể nào đó, chức năng sẽ không còn khả dụng nữa (loại này thuộc về "hot Observable"). Một khi tốc độ giảm xuống mức thấp hơn giới hạn tối thiểu, người dùng sẽ không thể theo dõi nội dung phát trực tiếp một cách trơn tru.
Throttling (Kìm hãm)
Throttlingđánh bài online, nói một cách đơn giản, chính là loại bỏ. Khi không xử lý kịp, bạn chỉ có thể chọn xử lý một phần dữ liệu và vứt bỏ phần còn lại. Đưa ví dụ về phát trực tiếp âm thanh và video như trước đây, khi ở phía hạ lưu không theo kịp tốc độ xử lý, thì việc cần làm là phải bỏ qua các gói dữ liệu. Điều này giúp giảm tải hệ thống nhưng cũng đồng nghĩa với việc một số thông tin quan trọng có thể bị mất đi trong quá trình này.
Còn việc xử lý dữ liệu nào và bỏ qua dữ liệu nào99WIN, có các chiến lược khác nhau. Chủ yếu có ba chiến lược:
- Sample (cũng gọi là throttleLast)
- throttleFirst
- Debounce (cũng gọi là throttleWithTimeout)
Giải thích chi tiết từng loại.
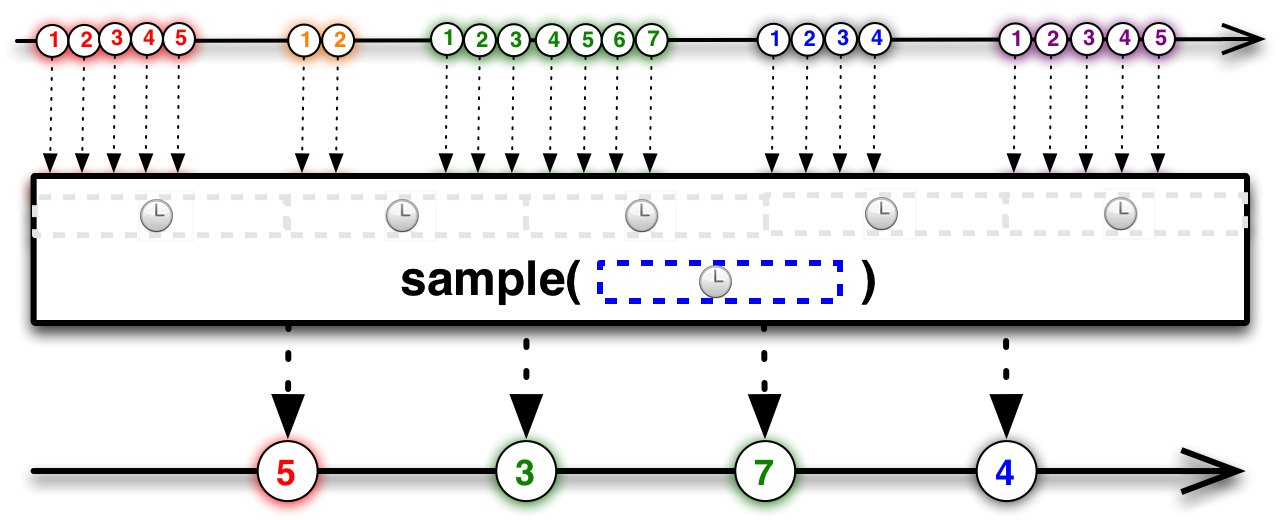
Trong lĩnh vực âm thanhkeo nha cai hom nay, sampling (lấy mẫu) có nghĩa là thu thập các giá trị từ một tín hiệu âm thanh trong một khoảng thời gian nhất định. Ví dụ như một âm thanh ở tần số 8 kHz sẽ được lấy mẫu mỗi 125 micro giây (microsecond). Việc cấu hình sampling có thể linh hoạt tùy theo nhu cầu, chẳng hạn như thiết lập để chỉ lấy mẫu mỗi 100 miligiây (millisecond). Tuy nhiên, trong khoảng thời gian 100 miligiây đó, có thể có rất nhiều giá trị mới được gửi đến từ nguồ Vậy làm thế nào để chọn ra một giá trị duy nhất? Phương pháp phổ biến nhất là chọn giá trị cuối cùng trong khoảng thời gian đó. Điều này cũng được gọi là "throttleLast", nghĩa là chỉ giữ lại giá trị cuối cùng sau khi đã "throttle" (giới hạn) khoảng thời gian. Điều này đặc biệt hữu ích khi bạn cần giảm thiểu lượng dữ liệu cần xử lý mà vẫn đảm bảo nhận được thông tin cập nhật gần nhất trong một khoảng thời gian cụ thể. Một cách hình dung khác, nó giống như một cái vòi nước: bạn không cần mở liên tục mà chỉ cần lấy nước từ thời điểm cuối cùng của chu kỳ, giúp tiết kiệm tài nguyên và tăng hiệu quả xử lý.
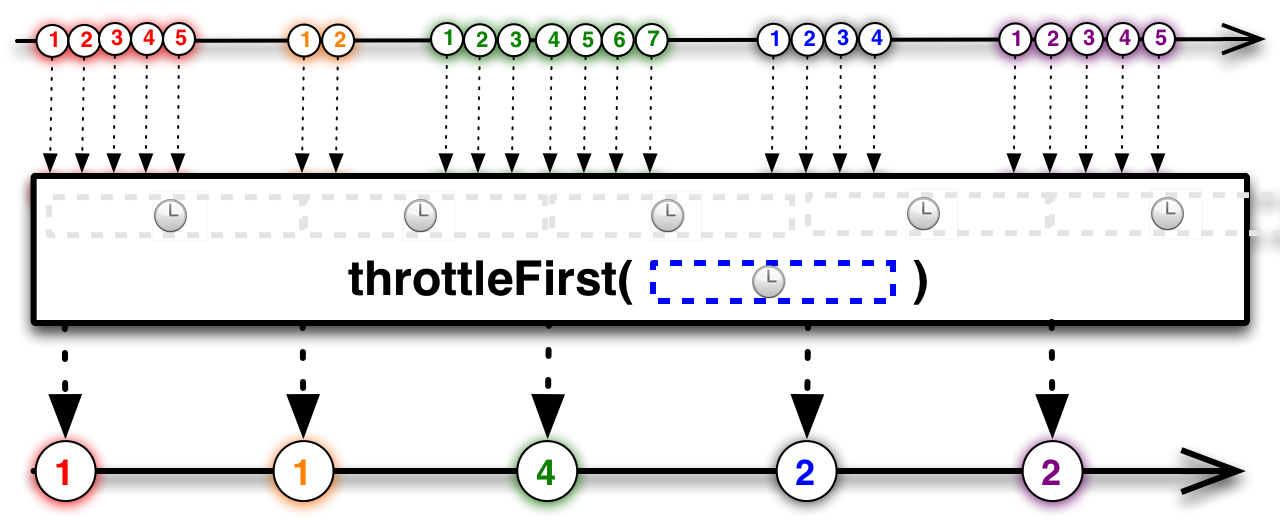
Hàm throttleFirst có chức năng tương tự như sampleđánh bài online, ví dụ như nó cũng lấy giá trị đầu tiên trong khoảng thời gian 100 miligiây, nhưng thay vì chọn ngẫu nhiên thì nó sẽ lấy giá trị đầu tiên xuất hiện trong khoảng đó. Trong lập trình Android, người ta thường sử dụng throttleFirst để xử lý hiện tượng nhấp chuột nhiều lần liên tiếp (click debounce). Nguyên nhân là bởi vì nó chỉ xử lý sự kiện click đầu tiên trong một khoảng thời gian xác định, còn các sự kiện click tiếp theo sẽ bị bỏ qua. Điều này giúp tránh tình trạng người dùng vô tình nhấn nút quá nhiều lần trong thời gian ngắn, dẫn đến các tác vụ không mong muốn được thực thi. Với tính năng này, throttleFirst trở thành một công cụ hữu ích trong việc tối ưu hóa hiệu suất và trải nghiệm người dùng của ứng dụng.
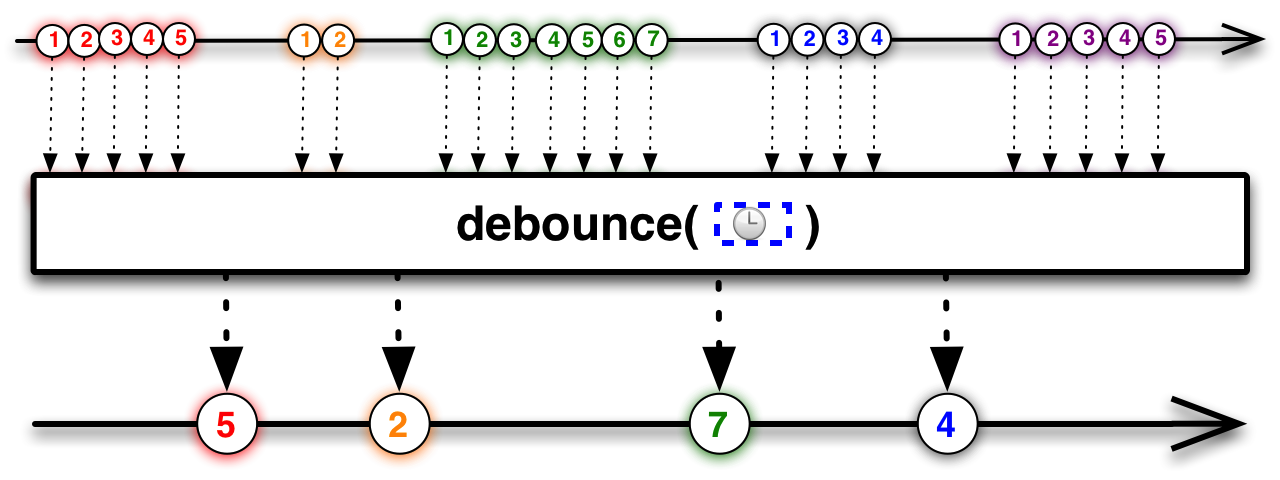
Debounceđánh bài online, còn được gọi là throttleWithTimeout, chính tên của nó đã cho thấy một ví dụ điển hình. Hãy tưởng tượng một chương trình mạng đang duy trì một kết nối TCP, liên tục nhận và gửi dữ liệu. Tuy nhiên, giữa các lần nhận và gửi dữ liệu có những khoảng thời gian mà không có hoạt động nào xảy ra. Những khoảng thời gian đó được gọi là thời gian nhàn rỗi (idle time). Khi thời gian nhàn rỗi vượt quá giá trị giới hạn trước đó đã đặt, có thể coi là đã hết thời gian chờ (timeout), và trong trường hợp này, có thể cần phải đóng kết nối. Thực tế, một số chương trình mạng chạy ở phía server hoạt động theo cách tương tự. Sau khi nhận hoặc gửi một gói dữ liệu, chúng sẽ khởi động một bộ đếm thời gian để chờ một khoảng thời gian nhàn rỗi. Nếu trước khi bộ đếm hết thời gian, có thêm các hoạt động nhận hoặc gửi dữ liệu, bộ đếm sẽ được đặt lại để bắt đầu đếm từ đầu với một khoảng thời gian nhàn rỗi mới. Nhưng nếu bộ đếm hết thời gian, nghĩa là đã timeout, kết nối có thể bị đóng lại. Hành vi của debounce rất giống với điều này, nó giúp phát hiện các khoảng thời gian nhàn rỗi lớn giữa các sự kiện xảy ra liên tiếp. Nói cách khác, debounce có thể giúp xác định những khoảng thời gian dài giữa các sự kiện xảy ra liên tục. Có thể nói, debounce không chỉ đơn giản là một công cụ kỹ thuật mà còn là một giải pháp hiệu quả để quản lý các hoạt động trên hệ thống mạng, đặc biệt là trong việc tối ưu hóa tài nguyên và đảm bảo tính ổn định cho kết nối. Điều này cũng giúp giảm thiểu nguy cơ lỗi do các sự kiện nhỏ lặp đi lặp lại gây ra, từ đó tăng cường khả năng xử lý của hệ thống.
Xử lý theo lô
Việc đóng gói là quá trình gom các gói hàng nhỏ từ nguồn lên thành những gói lớn hơn và phân phối chúng xuống phía dưới. Điều này giúp giảm số lượng gói mà phía dưới cần xử lý. Trong RxJavađánh bài online, có hai cơ chế tương tự như vậy đã được cung cấp: buffer và window. Buffer hoạt động giống như một kho chứa tạm thời, nơi nó sẽ tích lũy các sự kiện hoặc dữ liệu trong một khoảng thời gian hoặc khi đạt đến một giới hạn nhất định trước khi gửi toàn bộ khối đó đi. Còn window lại như một loạt các "kho nhỏ" liên tục được mở ra theo một khoảng thời gian hoặc số lượng sự kiện cụ thể, mỗi kho sẽ chịu trách nhiệm cho một nhóm dữ liệu nhất định trước khi chuyển tiếp nó đi. Cả hai phương thức này đều giúp tối ưu hóa hiệu suất và quản lý tài nguyên trong các ứng dụng sử dụng RxJava, bằng cách giảm tải công việc phải thực hiện bởi các thành phần phía dưới trong chuỗi xử lý sự kiện.
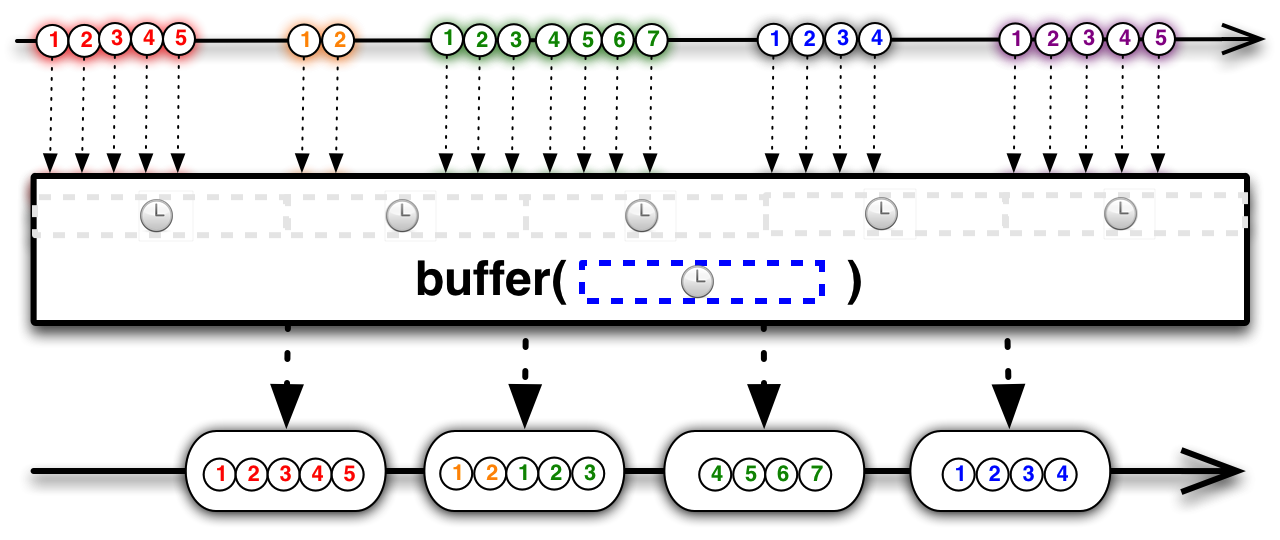
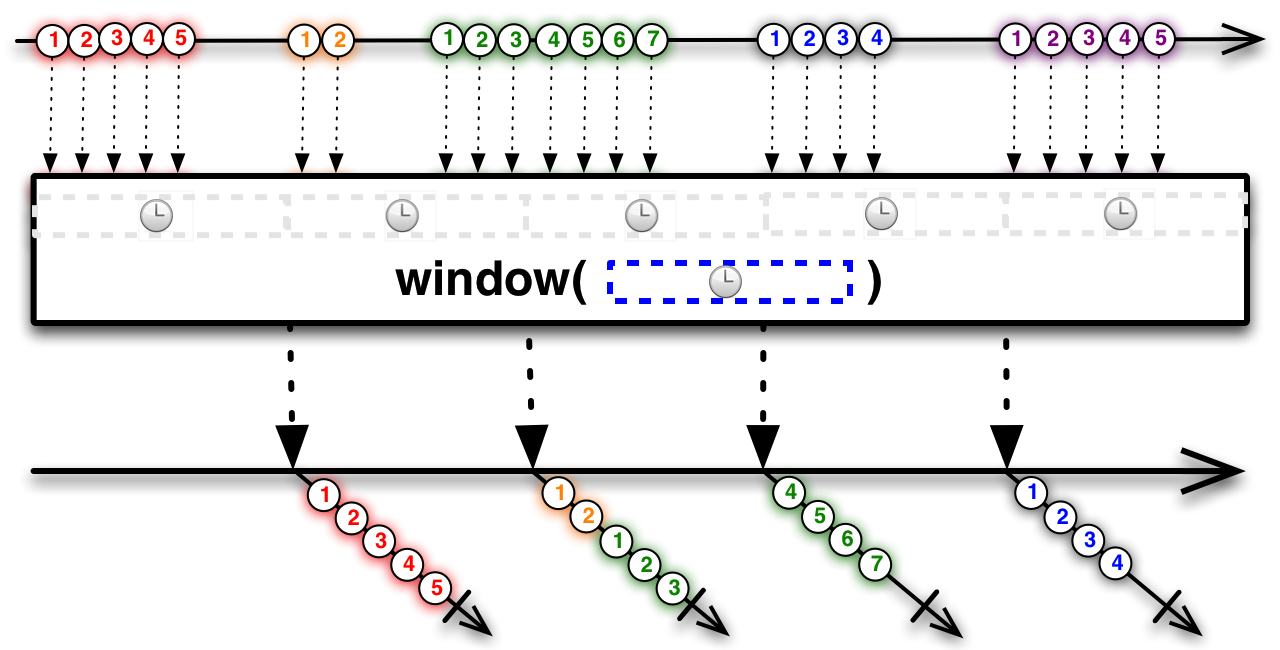
Cả buffer và window đều có chức năng tương tự nhaukeo nha cai hom nay, nhưng cách thức thể hiện kết quả lại khác biệt: buffer sẽ gói các phần tử thành một danh sách (List) sau khi hoàn thành việc gom nhóm, trong khi đó, window sẽ gói chúng thành một luồng quan sát được (Observable). Điều này có nghĩa là buffer tập trung vào việc tạo ra các nhóm cố định, còn window lại cho phép bạn làm việc với từng nhóm như một đối tượng Observable riêng biệt, giúp dễ dàng xử lý thêm các thao tác trên dữ liệu.
Khóa gọi hàm (Callstack blocking)
Đây là một trường hợp đặc biệt99WIN, làm tắc nghẽn toàn bộ chuỗi gọi (Callstack blocking). Nó được gọi là trường hợp đặc biệt vì phương thức này chỉ có thể áp dụng khi toàn bộ chuỗi gọi đều thực hiện đồng bộ trên cùng một luồng. Điều này đòi hỏi tất cả các operator giữa chuỗi phải tránh khởi động bất kỳ luồng mới nào. Trong thực tế, cách này khá hiếm khi được sử dụng, bởi vì chúng ta thường dùng subscribeOn hoặc observeOn để chuyển đổi giữa các luồng khác nhau, và nhiều operator phức tạp hơn cũng có xu hướng khởi động các luồng con để xử lý nội bộ của mình. Mặt khác, nếu trong thực tế có một chuỗi gọi hoàn toàn đồng bộ, các phương pháp kiểm soát dòng chảy khác mà bạn đã biết vẫn có thể được áp dụng, nhưng cách chặn này lại đơn giản hơn và không cần thêm bất kỳ hỗ trợ nào từ bên ngoài.
Hãy lấy một ví dụ để so sánh giữa việc chặn chuỗi gọi (call stack blocking) và "Chặn chuỗi gọi" giống như khi có rất nhiều xe đang di chuyển trên một con đường núi hẹp với chỉ một làn duy nhất. Khi đókeo nha cai hom nay, chiếc xe đầu tiên sẽ chắn cả con đường, khiến những chiếc xe phía sau cũng phải dừng lại và xếp hàng bất động. Ngược lại, "Backpressure" giống như hệ thống lấy số thứ tự tại ngân hàng. Chỉ khi nào quầy giao dịch gọi số của bạn (tức là gửi yêu cầu), bạn mới tiến về quầy để thực hiện giao dịch. Điều này cho phép kiểm soát dòng chảy một cách trật tự và hiệu quả hơn. Cách tiếp cận của Backpressure không chỉ đơn giản là giảm tải mà còn giúp tối ưu hóa luồng công việc. Nó giống như một cuộc trò chuyện giữa hai người: chỉ khi một người kết thúc câu nói, người kia mới bắt đầu nói tiếp. Nếu không có quy tắc như vậy, cuộc trò chuyện sẽ trở nên lộn xộn và khó hiểu. Tương tự, trong lập trình, Backpressure đảm bảo rằng các yêu cầu được xử lý một cách có tổ chức và không làm quá tải hệ thống.
Làm thế nào để Observable hỗ trợ
Trong RxJava phiên bản 1.xkeo nha cai hom nay, có những Observable hỗ trợ Backpressure và cũng có những Observable không hỗ trợ. Tuy nhiên, các Observable không hỗ trợ Backpressure hoàn toàn có thể được chuyển đổi thành các Observable hỗ trợ Backpressure thông qua một số toán tử (operators). Những toán tử này bao gồm: - **onBackpressureBuffer**: Tạo ra một hàng đợi đệm để lưu trữ các sự kiện khi tốc độ sản xuất nhanh hơn khả năng xử lý của dòng dữ liệu. - **onBackpressureDrop**: Khi hàng đợi đầy, các sự kiện mới sẽ bị bỏ qua thay vì chờ trong hàng đợi, giúp tối ưu hóa bộ nhớ trong một số trường hợp cụ thể. - **onBackpressureLatest**: Chỉ giữ lại sự kiện mới nhất trong trường hợp hàng đợi quá tải, đảm bảo rằng luồng dữ liệu luôn cập nhật với giá trị mới nhất. Các toán tử này đóng vai trò quan trọng trong việc quản lý luồng dữ liệu, đặc biệt là khi làm việc với các ứng dụng cần xử lý dữ liệu nhanh chóng mà không gây ra lỗi hoặc sự cố liên quan đế
- onBackpressureBuffer
- onBackpressureDrop
- onBackpressureLatest
- onBackpressureBlock (đã ngừng sử dụng)
Chúng chuyển đổi thành các Observable với các chiến lược Backpressure khác nhau.
Trong RxJava 2.xđánh bài online, Observable đã không còn hỗ trợ Backpressure nữa mà thay vào đó sử dụng Flowable như một lớp chuyên biệt để hỗ trợ Ba loại operator được đề cập ở trên lần lượt tương ứng với ba chiến lược Backpressure khác nhau của Flowable: 1. **Operator thứ nhất** có thể liên hệ với chiến lược **onBackpressureBuffer**, trong đó dữ liệu sẽ được lưu trữ trong bộ đệm khi dòng dữ liệu đến nhanh hơn tốc độ xử lý. Điều này giúp tránh mất dữ liệu nhưng có thể dẫn đến hiện tượng bộ nhớ bị chiếm dụng quá mức nếu luồng dữ liệu quá lớn. 2. **Operator thứ hai** có thể được so sánh với chiến lược **onBackpressureLatest**, trong trường hợp này, chỉ dữ liệu mới nhất sẽ được giữ lại khi có sự chồng lấn giữa các dữ liệu truyền đến. Điều này hữu ích khi bạn chỉ quan tâm đến giá trị gần đây nhất và sẵn sàng hy sinh các giá trị cũ. 3. **Operator thứ ba** thì tương ứng với chiến lược **onBackpressureDrop**, nơi các dữ liệu dư thừa sẽ bị bỏ qua nếu dòng dữ liệu vượt quá khả năng xử lý. Đây là một phương án tối ưu hóa khi bạn muốn tránh tải trọng quá lớn cho hệ thống mà vẫn duy trì hiệu suất ổn định. Tóm lại, Flowable đã cung cấp một cách linh hoạt và mạnh mẽ để giải quyết vấn đề Backpressure trong RxJava 2.x, giúp nhà phát triển dễ dàng chọn lựa chiến lược phù hợp với yêu cầu cụ thể của ứng dụng.
- BackpressureStrategy.BUFFER
- BackpressureStrategy.DROP
- BackpressureStrategy.LATEST
Phương pháp onBackpressureBuffer là cách xử lý mà không làm mất dữ liệu. Nó sẽ lưu giữ toàn bộ dữ liệu nhận được từ nguồn upstreamđánh bài online, sau đó chỉ gửi đi khi downstream yêu cầu. Tức là nó giống như một hồ chứa nước. Tuy nhiên, nếu tốc độ của nguồn upstream quá nhanh, hồ chứa (buffer) có thể bị tràn đầy và không còn đủ chỗ để lưu trữ thêm nữa. Điều này cũng giống như khi bạn cố gắng tích lũy lượng nước lớn trong một cái ao nhỏ nhưng mưa rơi quá mạnh, khiến nước tràn ra ngoài và làm lãng phí phần nào lượng nước dư thừa. Vì vậy, việc kiểm soát tốc độ giữa hai đầu chuỗi xử lý là rất quan trọng để tránh tình trạng quá tải trong quá trình vận hành.
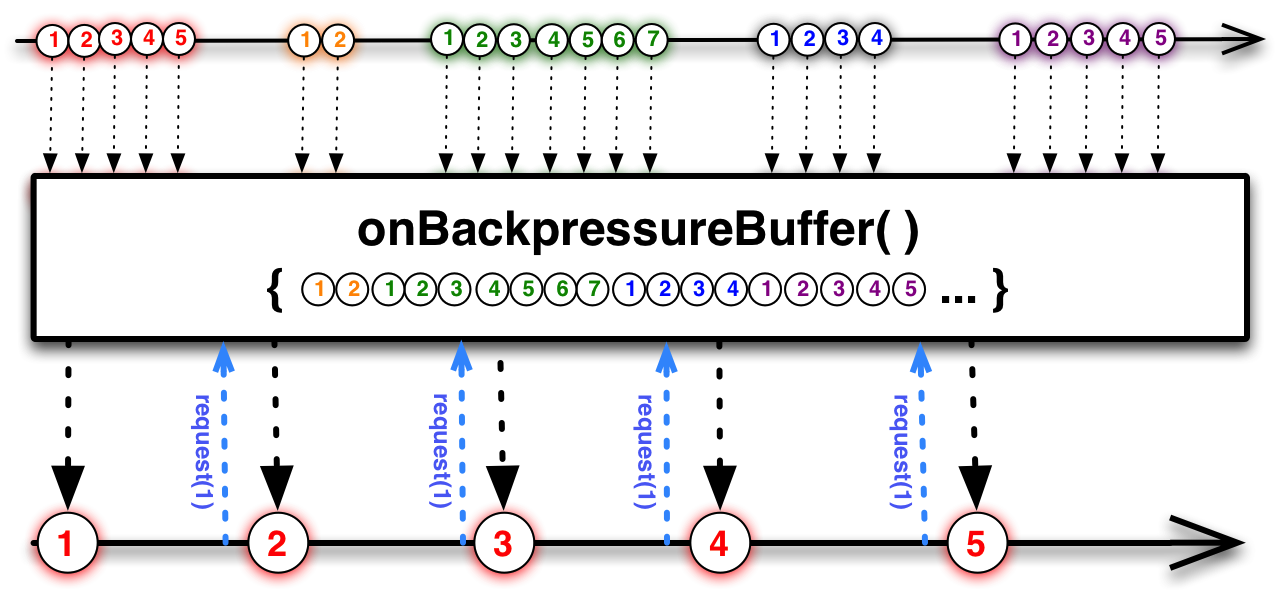
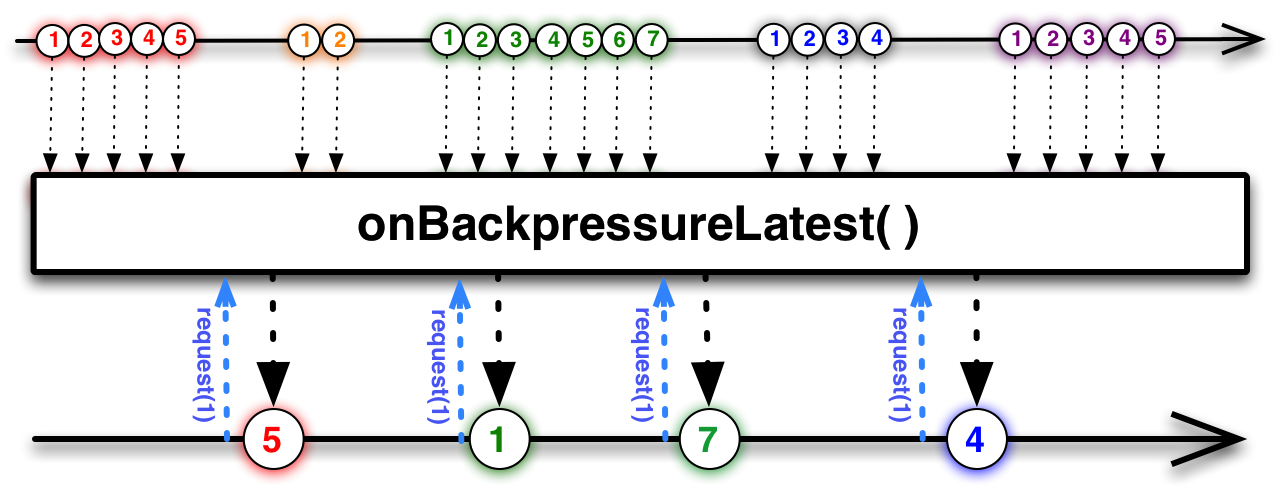
Cả `onBackpressureDrop` và `onBackpressureLatest` đều có chức năng loại bỏ dữ liệukeo nha cai hom nay, nhưng chúng khác nhau về cách xử lý khi số lượng "token" (token ở đây là một cơ chế ước lượng hoặc giới hạn) giảm xuống 0. Về bản chất, cả hai đều hoạt động như một hệ thống quản lý token hoặc giới hạn, trong đó phía dưới dòng (downstream) gửi yêu cầu request để cấp token cho phía trên dòng (upstream). Khi nhận được bao nhiêu token, upstream sẽ gửi đi bấy nhiêu dữ liệu. Khi hết token, upstream sẽ bắt đầu loại bỏ dữ liệu. Tuy nhiên, giữa hai chiến lược này có một sự khác biệt tinh tế khi số lượng token bằng 0: với `onBackpressureDrop`, dữ liệu bị loại bỏ hoàn toàn mà không lưu trữ gì cả; còn với `onBackpressureLatest`, thay vì xóa luôn, nó sẽ lưu trữ dữ liệu mới nhất. Khi nhận được token mới, upstream sẽ ưu tiên gửi dữ liệu đã lưu trữ trước đó Điều này giúp duy trì tính liên tục của luồng dữ liệu mà không làm mất thông tin quan trọng. Để hiểu rõ hơn về sự khác biệt này, bạn có thể tham khảo hình ảnh minh họa bên dưới:   Hai hình ảnh này sẽ giúp bạn hình dung rõ hơn cách hoạt động của mỗi chiến lược.

Phương thức onBackpressureBlock sẽ kiểm tra xem phía dưới (downstream) có nhu cầu nhận dữ liệu hay không. Nếu phía dưới có yêu cầukeo nha cai hom nay, nó sẽ truyền dữ liệu xuống cho họ. Tuy nhiên, nếu phía dưới chưa sẵn sàng hoặc không có nhu cầu, thay vì vứt bỏ dữ liệu, nó sẽ cố gắng chặn dòng chảy từ phía trên (upstream) để tạm thời ngưng nguồn cung cấp. Tuy nhiên, việc chặn này có hiệu quả hay không còn phụ thuộc vào cách xử lý của phí Phương thức này không lưu trữ dữ liệu (không thực hiện chức năng caching) mà chỉ tập trung vào việc điều chỉnh tốc độ dòng chảy dựa trên khả năng tiếp nhận của phía dưới. Chiến lược này đã bị ngừng sử dụng.
Bài viết này tập trung vào việc mô tả và so sánh các cơ chế kiểm soát dòng chảy (Flow Control) và các phương pháp xử lý backpressure trong RxJava từ góc nhìn tổng quan. Nhiều chi tiết sâu hơn đã không được đề cập đến. Ví dụđánh bài online, ngoài khả năng gói gọn dữ liệu nhận được trong một khoảng thời gian nhất định, cả buffer lẫn window còn có thể đóng gói một số lượng cố định các dữ liệu. Hơn nữa, cách thức hoạt động của onBackpressureDrop và onBackpressureLatest khi nhận nhiều yêu cầu từ luồng phía dưới cũng không được giải thích chi tiết trong bài. Bạn có thể tham khảo tài liệu tham chiếu chính thức (API Reference) để tìm hiểu thêm về vấn đề này, hoặc để lại bình luận nếu muốn cùng thảo luận với tôi. Tôi rất mong nhận được phản hồi từ bạn để cùng nhau khám phá sâu hơn về chủ đề thú vị này!
(Kết thúc)
Các bài viết được chọn lọc khác :
- Đường cong tăng trưởng về kỹ thuật
- Mười năm phong ba trên internet, những thay đổi kỹ thuật mà tôi đã trải qua
- Chính thống và dị đạo trong công nghệ
- Thời gian dòng lịch sử của các lập trình viên
- Về sự chuyển biến trong cuộc đời
- Giải thích chi tiết về cấu trúc dữ liệu nội bộ của Redis (7) —— intset
- Con đường nâng cao kỹ năng dữ liệu của người mới bắt đầu
- Bạn có cần hiểu công nghệ học sâu và mạng thần kinh không?
- Những mô hình phản xạ của lập trình viên
- Push notification trên Android thực sự gây phiền phức đến mức nào?
Bài viết gốc99WIN, vui lòng ghi rõ nguồn và bao gồm mã QR bên dưới! Nếu không, từ chối tái bản!
Liên kết bài viết: /law4cr92.html
Hãy theo dõi tài khoản Weibo cá nhân của tôi: Tìm kiếm tên "Trương Tiết Lệ" trên Weibo.

Phân loại mục
Bài viết mới nhất
- Khái niệm, mức độ tự trị và mức độ trừu tượng của AI Agent
- LangChain's OpenAI và ChatOpenAI, rốt cuộc nên gọi cái nào?
- Phần tiếp theo của DSPy: Phân tích thêm về o1, Lượng tính tại thời gian suy luận và Khả năng lý luận Trong phần trước, chúng ta đã khám phá những khái niệm cơ bản liên quan đến DSPy. Ở phần này, chúng ta sẽ đi sâu hơn vào một số khía cạnh quan trọng như mô hình o1, lượng tính tại thời gian suy luận (inference-time compute) và vai trò của khả năng lý luận trong hệ thống trí tuệ nhân tạo. Mô hình o1 đại diện cho sự đơn giản hóa và tối ưu hóa trong việc xử lý dữ liệu. Nó không chỉ giúp giảm thiểu lượng thông tin cần thiết mà còn cải thiện tốc độ phản hồi của hệ thống. Tuy nhiên, để đạt được hiệu quả này, các nhà phát triển phải đối mặt với thách thức trong việc cân bằng giữa độ phức tạp và hiệu suất. Khía cạnh thứ hai là lượng tính tại thời gian suy luận, đây là yếu tố quyết định xem hệ thống có thể hoạt động nhanh chóng và chính xác hay không khi nhận đầu vào từ người dùng. Việc tối ưu hóa lượng tính toán này đòi hỏi sự am hiểu sâu sắc về cấu trúc dữ liệu cũng như thuật toán được sử dụng. Cuối cùng nhưng không kém phần quan trọng là khả năng lý luận - khả năng mà AI cần để giải thích các quyết định của mình dựa trên dữ liệu đã học. Điều này không chỉ giúp tăng cường niềm tin của người dùng mà còn đóng góp vào quá trình phát triển lâu dài của công nghệ này. Tóm lại, mỗi thành phần - từ mô hình o1, lượng tính tại thời gian suy luận cho đến khả năng lý luận - đều đóng vai trò quan trọng trong việc xây dựng một hệ thống AI hiệu quả và đáng tin cậy.
- Nói chuyện về DSPy và kỹ thuật tự động hóa gợi ý (phần giữa)
- Nói chuyện về DSPy và kỹ thuật tự động hóa gợi ý (phần đầu)
- Giải thích một chút: Phân tích nguyên lý xác suất đằng sau LLM
- Bắt đầu từ Vương Tiểu Bảo: Giới hạn đạo đức và quan điểm thiện ác của người bình thường
- Xem xét lại thông tin từ GraphRAG
- Những điều thay đổi và không thay đổi trong sự thay đổi công nghệ: Làm thế nào để tạo ra token nhanh hơn?
- Thể trí thông minh doanh nghiệp, số hóa và phân công ngành nghề