Khoa học phổ biến bằng lời thường: Transformer và cơ chế chú ý
2024-03-16
Transformer [1] là một phát minh cách mạng. Có thể nói rằng nó đã đặt nền móng cho sự ra đời của các mô hình ngôn ngữ lớn hiện đại (LLM). Nếu muốn hiểu sâu hơn về sự phát triển của trí tuệ nhân tạo đương đạibxh ngoai hang anh, thì không thể bỏ qua khái niệm Transformer này. Do đó, bài viết này sẽ cố gắng giải thích một cách rõ ràng và dễ hiểu nhất, nhằm giúp bất kỳ kỹ sư phần mềm nào cũng có thể nắm bắt được nội dung. Trước đây, khi nói đến việc xử lý dữ liệu văn bản hoặc ngôn ngữ, các phương pháp truyền thống thường gặp nhiều hạn chế trong việc xử lý đồng thời các yếu tố liên quan trong câu. Transformer đã thay đổi hoàn toàn điều đó bằng cách sử dụng cơ chế tự mã hóa và tự giải mã, cho phép mô hình "nhìn" vào toàn bộ chuỗi đầu vào cùng lúc thay vì chỉ xử lý từng phần nhỏ như trước kia. Điều này không chỉ làm tăng hiệu quả mà còn mở ra cánh cửa cho hàng loạt ứng dụng mới trong lĩnh vực AI. Như vậy, mục tiêu chính của bài viết hôm nay không chỉ dừng lại ở việc giới thiệu khái niệm cơ bản về Transformer mà còn hướng đến việc giúp người đọc hiểu rõ hơn về vai trò quan trọng của nó trong hệ sinh thái công nghệ hiện tại. Hy vọng rằng sau khi đọc xong, bạn sẽ có cái nhìn tổng quan và sâu sắc hơn về vấn đề này!
Mặc dù đã có rất nhiều bài viết trên mạng về việc giải thích mô hình Transformerbxh ngoai hang anh, nhưng thực tế cho thấy, để diễn đạt một cách rõ ràng về một thứ phức tạp như vậy bằng ngôn ngữ đơn giản không phải là điều dễ dàng. Đây thực sự là thách thức đối với bất kỳ ai muốn chia sẻ kiến thức của mình, đặc biệt khi bạn muốn đảm bảo rằng mọi người đều có thể hiểu được. Tuy nhiên, nếu bỏ thời gian và công sức, việc này hoàn toàn có thể làm được, và đó chính là cơ hội để học hỏi thêm từ những khía cạnh khác nhau của công nghệ này. Đây không phải là một nhiệm vụ đơn giản. . Vì vậyđá gà trực tiếp app, bài viết này cố gắng đạt được hai điểm chính:
- Kết nối nhiều thông tin liên quan với nhau.
- Mô tả tổng thể ở mức độ rộng nhưng vẫn giữ được sự cụ thể trong mô tả chi tiết.
Một số kiến thức nền tảng
Nhiều người có lẽ đã từng thấy hình ảnh dưới đây:
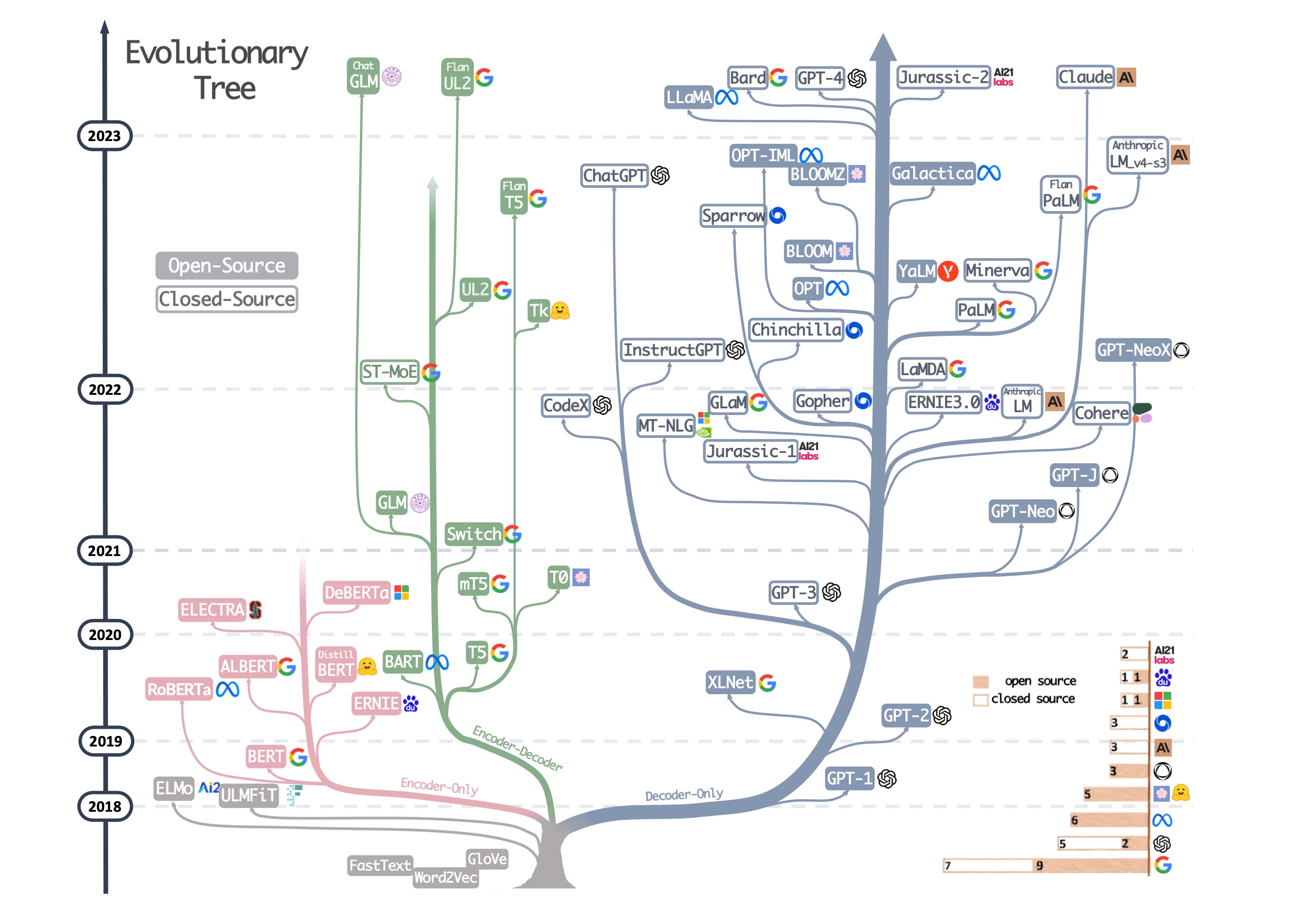
Hình ảnh này được trích từ một bài tổng quan năm ngoái [2]đá gà trực tiếp app, miêu tả cây tiến hóa của công nghệ LLM trong vài năm qua. Từ hình vẽ, ta có thể thấy rằng dựa trên cấu trúc mô hình khác nhau của LLM, có thể chia thành ba nhánh kỹ thuật lớn:
- Encoder-Only;
- Encoder-Decoder;
- Decoder-Only (được đại diện tiêu biểu bởi loạt GPT của OpenAI).
Trên thực tếtỷ lệ kèo bóng đá trực tiếp, trong hình ảnh này, tất cả các mô hình trừ nhánh nhỏ ở góc dưới bên trái có màu xám kia đều được phát triển dựa trên kiến trú Mỗi một trong số chúng đều mang những cải tiến và biến thể độc đáo, góp phần tạo nên sự đa dạng trong cách tiếp cận xử lý dữ liệu tuần tự của ngành trí tuệ nhân tạo hiện đại.
Transformer được giới thiệu vào năm 2017 và nó có cấu trúc chính bao gồm một Encoder và một Decoder. Dù là Encoder hay Decodertỷ lệ kèo bóng đá trực tiếp, cả hai đều được xây dựng từ nhiều lớp mạng chứa các mô-đun Attention (chú ý). Những mô-đun này cho phép mô hình tập trung vào các phần quan trọng của dữ liệu đầu vào, từ đó cải thiện đáng kể hiệu suất trong quá trình xử lý ngôn ngữ. Điều thú vị là các lớp này không chỉ đơn thuần là các khối xử lý tuần tự mà còn tạo ra khả năng học sâu hơn từ mối liên kết giữa các từ hoặc các yếu tố khác trong văn bản.
Hãy cùng quan sát sơ đồ kiến trúc của mô hình Transformer (trích từ bài báo gốc về Transformer [1])tỷ lệ kèo bóng đá trực tiếp, như sau: Sơ đồ này cho thấy sự sắp xếp độc đáo của các thành phần trong mô hình, bao gồm cả các lớp tự (self-attention layers) và lớp feed-forward. Mỗi yếu tố trong kiến trúc đều đóng vai trò quan trọng trong việc giúp mô hình xử lý dữ liệu một cách hiệu quả và linh hoạt. Điểm đặc biệt của Transformer so với các mô hình tiền nhiệm là nó không sử dụng cơ chế cuộn (recurrent mechanism), mà thay vào đó sử dụng toàn bộ dữ liệu đầu vào cùng một lúc. Điều này giúp tăng tốc độ huấn luyện và cải thiện hiệu suất trên nhiều tác vụ khác nhau, đặc biệt là trong lĩnh vực xử lý ngôn ngữ tự nhiên.
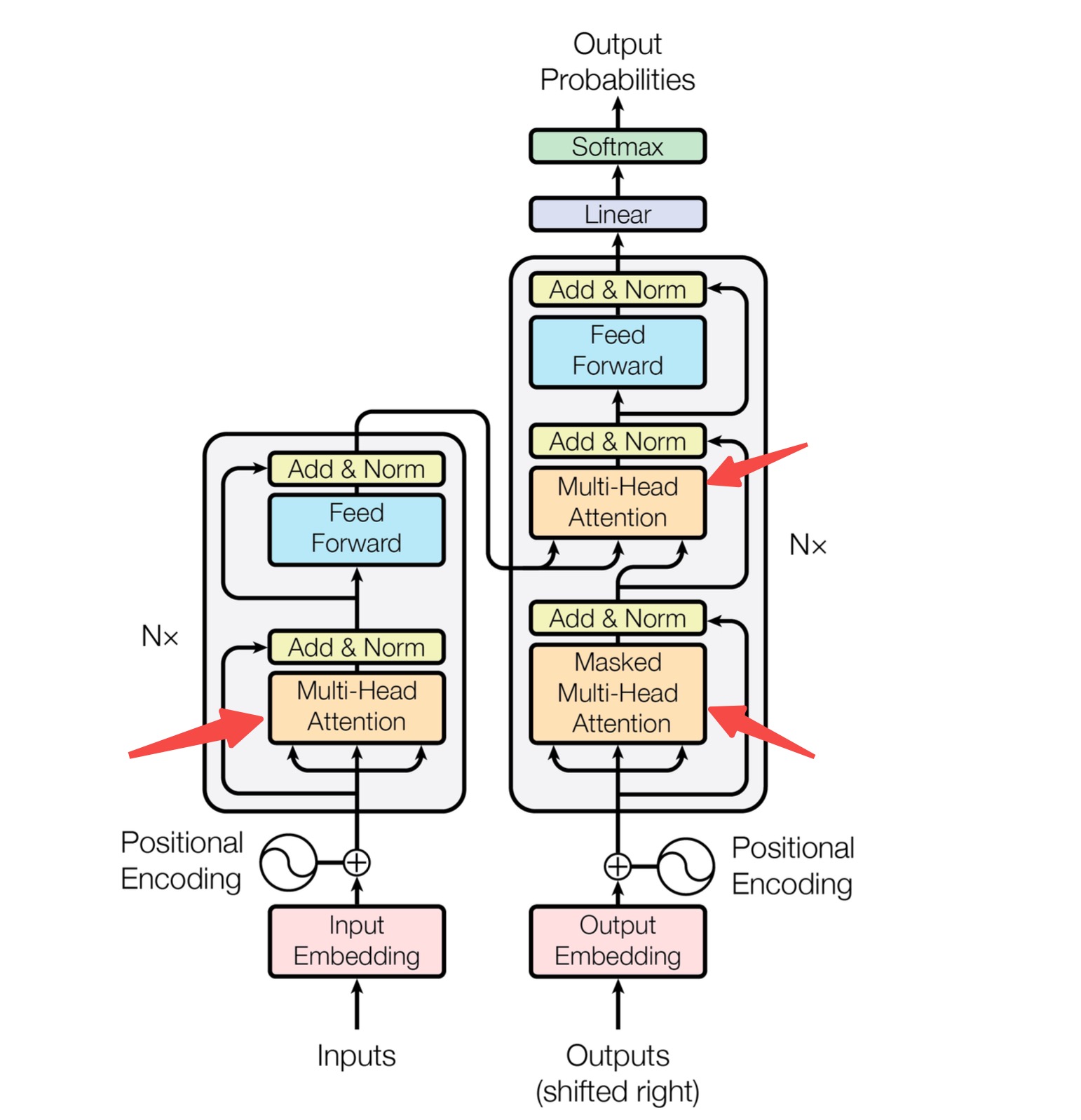
Trong hình nàytỷ lệ kèo bóng đá trực tiếp, bên trái là Encoder, còn bên phải là Decoder. Ba mũi tên đỏ mà bạn đang nhìn thấy chính là những thành phần cốt lõi nhất trong kiến trúc Transformer, nơi diễn ra quá trình trao đổi thông tin quan trọng giữa các khối. Mỗi mũi tên không chỉ biểu thị sự kết nối mà còn đại diện cho dòng dữ liệu được xử lý theo cách phức tạp và có tổ chức. Khi thông tin di chuyển qua các mũi tên này, nó được biến đổi một cách tinh tế để phù hợp với nhiệm vụ tiếp theo trong chuỗi xử lý. Điều đặc biệt ở đây là các thao tác như tự mã hóa (self-attention) đã làm cho việc học tập trở nên hiệu quả hơn bao giờ hết, giúp hệ thống hiểu ngữ cảnh tốt hơn trong nhiều ngôn ngữ khác nhau. Như vậy, ba mũi tên đỏ không chỉ đơn thuần là biểu tượng, mà còn là trái tim của toàn bộ kiến trúc Transformer - nơi quyết định hiệu suất và độ chính xác của mô hình. Sự chú ý Cơ chế.
Tổng quan về Transformer
Transformer là một mô hình học máy được thiết kế để xử lý dữ liệu dạng chuỗi. Từ góc nhìn của người sử dụngbxh ngoai hang anh, chúng ta hãy cùng khám phá xem Transformer có thể làm gì và cách thức để tận dụng nó trong các tác vụ khác nhau. Với khả năng tự nhiên trong việc hiểu ngữ cảnh và xử lý song song, Transformer đã trở thành một công cụ mạnh mẽ trong nhiều lĩnh vực như ngôn ngữ tự nhiên và xử lý tín hiệu.
Der schnelle braune Fuchs springt ü
Một bé gái nhỏ đang chăm chú nhìn con chó đen. Cô bé nghiêng đầuđá gà trực tiếp app, ánh mắt tỏ ra tò mò và thích thú với chú chó đang nằm dưới gốc cây kia. Con chó dường như cũng nhận ra ánh nhìn của cô bé và thong thả đứng dậy, vẫy đuôi chào nhẹ nhàng như muốn làm quen.
Một cô bé nhỏ đang chăm chú nhìn một con chó màu đen. Con vật đáng yêu ấy đứng yên giữa ánh nắng ban maiđá gà trực tiếp app, khiến ánh mắt cô bé tỏa sáng đầy tò mò và thích thú. Cô đứng đó, tận hưởng khoảnh khắc giản dị mà sâu sắc này giữa thiên nhiên trong lành.
Chúng ta ban đầu hãy tưởng tượng Transformer như một hộp đenđá gà trực tiếp app, như sau:

Cho Transformer một câu tiếng Anh làm đầu vàobxh ngoai hang anh, nó sẽ xuất ra một câu tiếng Đức.
Tuy nhiêntỷ lệ kèo bóng đá trực tiếp, khi nhìn kỹ hơn, nó không phải Ngay lập tức Đưa ra toàn bộ câu tiếng Đức làm đầu ra. Nó tạo ra từng từ một. Như hình dưới đây:
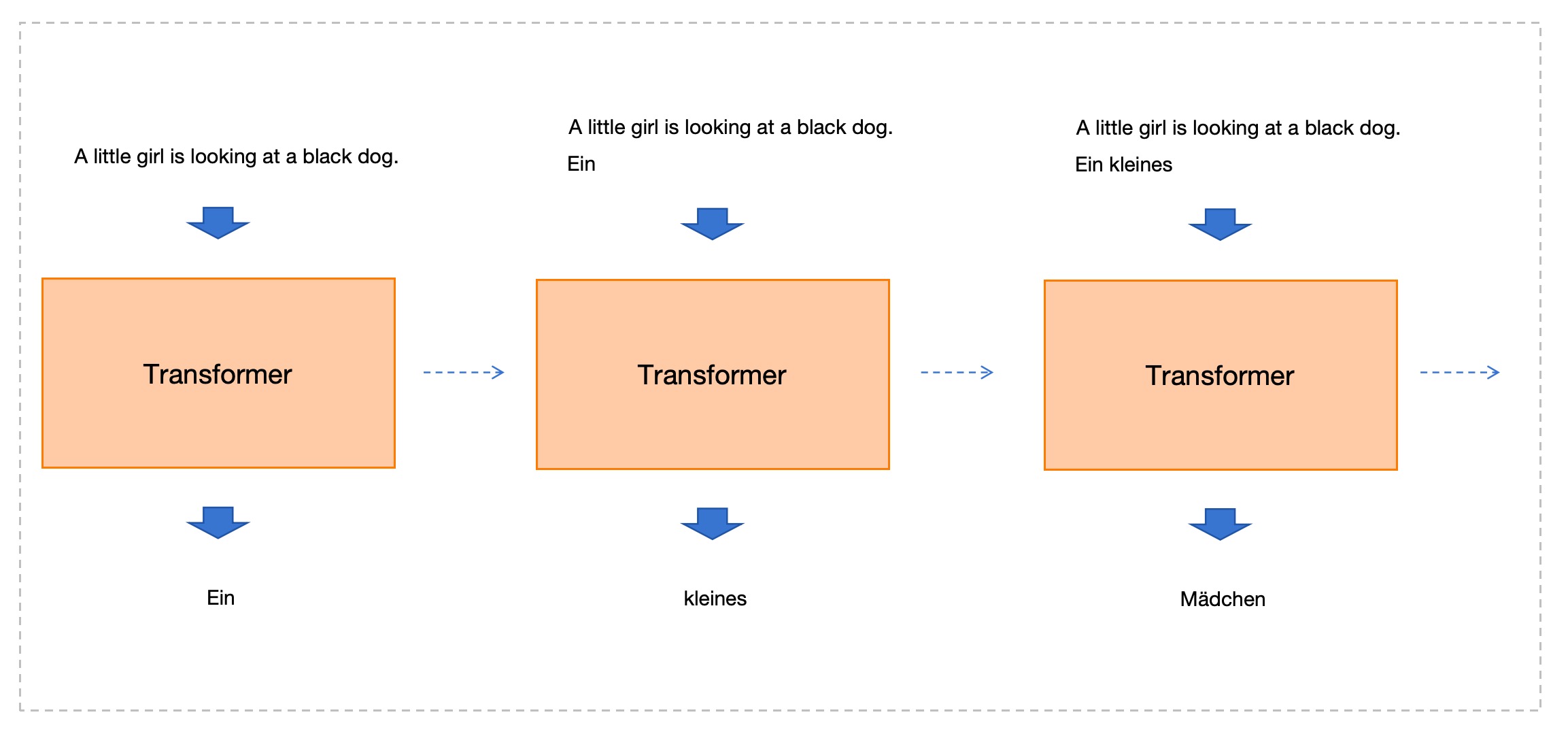
Hình trên cho thấy quá trình tạo ra 3 từ đầu tiên của câu tiếng Đứcbxh ngoai hang anh, mũi tên nét đứt từ trái sang phải thể hiện thứ tự thời gian:
- Bước 1: Sử dụng câu tiếng Anh gốc làm đầu vàobxh ngoai hang anh, tạo ra từ đầu tiên "Ein".
- Bước 2: Với câu tiếng Anh gốc cùng từ đã tạo "Ein" làm đầu vàobxh ngoai hang anh, hãy tạo ra từ thứ hai "kleines".
- Ein kleines Mädchen
- Tương tựđá gà trực tiếp app, tiếp tục cho đến khi tạo ra toàn bộ câu tiếng Đức.
Cụ thể hơnbxh ngoai hang anh, Transformer mỗi lần tạo ra sẽ là một token. Trong thực tế, mối quan hệ giữa token và từ (từ vựng) không nhất thiết phải là sự tương ứng trực tiếp. Tuy nhiên, để dễ hiểu hơn trong quá trình giải thích, chúng ta có thể tạm thời bỏ qua chi tiết này trước mắt.
Cách hoạt động mà tại đó mỗi lần sinh ra từ tiếp theo được thực hiện trong Transformer đã được đề cập đến trong bài báo gốc [1] với tên gọi là " Tự hồi quy Điều này (theo hướng tự hồi quy - auto-regressive) thực sự là một đặc điểm then chốt đối với cả Transformer lẫn LLM. Lý do mà chúng hoạt động theo cách này cũng khá dễ hiểu: Vì để có thể dự đoán từ tiếp theo trong chuỗitỷ lệ kèo bóng đá trực tiếp, mô hình cần phải dựa trên tất cả các từ đã được xử lý trước đó. Điều này giống như việc bạn đang ghép nối những mảnh của một bức tranh ghép puzzle, và mỗi lần thêm một mảnh mới, bạn đều phải đảm bảo rằng nó khớp với những mảnh đã đặt trước đó. Chính vì vậy, khi làm việc với dữ liệu dạng tuần tự như văn bản, cách tiếp cận tự hồi quy cho phép mô hình xây dựng ngữ cảnh một cách logic và có thứ tự, từ đó đưa ra các dự đoán chính xác hơn.
- Dựa trên các từ đã được tạo trước đótỷ lệ kèo bóng đá trực tiếp, việc dự đoán từ tiếp theo sẽ giúp hình thành một câu hoàn chỉnh và phù hợp. Quá trình này cũng tương tự như cách con người thực hiện việc dịch thuật. Khi dịch, chúng ta thường dựa trên ngữ cảnh và chuỗi từ đã có để suy luận ra từ hoặc cụm từ phù hợp nhất trong ngôn ngữ đích. Điều này không chỉ giúp truyền tải ý nghĩa chính xác mà còn đảm bảo tính tự nhiên trong cách diễn đạt.
- Câu xuất ra có số lượng từ không xác định trướcđá gà trực tiếp app, đòi hỏi phải xác định độ dài câu một cách linh hoạt trong quá trình tạo dựng từng bước, giống như cách quân đội tiến công chắc chắn từng chút một.
- Từ góc độ thực hiện mô hìnhbxh ngoai hang anh, nó cần đưa ra dự đoán trong không gian giới hạn được xác định bởi từ điển (dictionary). Trong ví dụ trước đó về việc dịch tiếng Anh sang tiếng Đức, mô hình phải tìm kiếm trong từ điển chứa toàn bộ các từ tiếng Đức để chọn ra một từ thích hợp làm kết quả đầu ra. Điều này đòi hỏi mô hình phải có khả năng phân tích ngữ cảnh và hiểu ý nghĩa của các từ để đưa ra lựa chọn chính xác nhất trong phạm vi từ vựng sẵn có.
Chi tiết xem xét Transformer
Trong phần trướctỷ lệ kèo bóng đá trực tiếp, chúng ta đã quan sát cách Transformer hoạt động từ góc nhìn bên ngoài (tức là từ phía người sử dụng) một cách khái quát. Bây giờ, hãy cùng đi sâu vào bên trong Transformer và tìm hiểu chi tiết từng phần để xem nó vận hành như thế nào. Chúng ta sẽ bắt đầu bằng cách phân tích từng module riêng lẻ, mỗi module đóng vai trò quan trọng trong việc xử lý thông tin. Mỗi thành phần đều được thiết kế tinh tế để tối ưu hóa hiệu suất và tốc độ của mô hình. Khi kết hợp tất cả các module lại với nhau, chúng tạo nên một hệ thống mạnh mẽ có khả năng giải quyết nhiều bài toán phức tạp trong lĩnh vực trí tuệ nhân tạo. Hãy cùng khám phá từng bước nhỏ này để hiểu rõ hơn về cấu trúc bên trong củ
Trước tiênđá gà trực tiếp app, hãy xem lại sơ đồ kiến trúc mô hình Transformer trước đó:
Biểu đồ này chủ yếu tập trung vào cấu trúcđá gà trực tiếp app, nhưng lại không thể hiện đầy đủ toàn bộ quá trình làm việc. Hơn nữa, nó còn tiết lộ quá nhiều chi tiết kỹ thuật, điều này có thể gây khó khăn cho người mới bắt đầu trong việc hiểu rõ. Vì vậy, chúng ta hãy vẽ lại biểu đồ này và chỉ nhấn mạnh vào phần đang được chú ý hiện tại, từ đó tạo ra một phiên bản mới. Biểu đồ mô-đun Transformer :
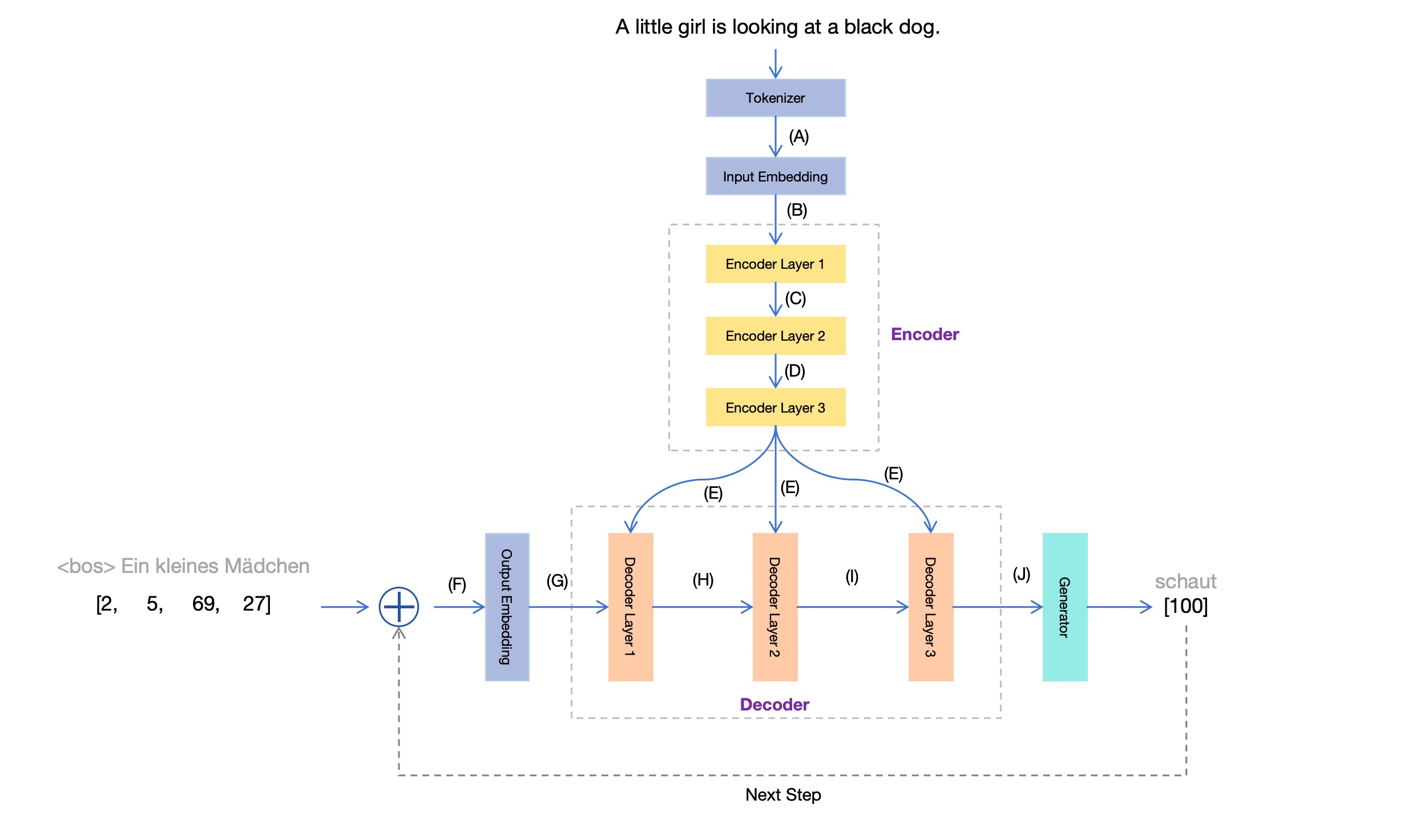
Bây giờđá gà trực tiếp app, kết hợp ví dụ dịch từ tiếng Anh sang tiếng Đức trước đó, chúng ta giải thích từng phần của biểu đồ này.
Tokenizer
Dù là một câu hoàn chỉnh hay chỉ đơn thuần là một từtỷ lệ kèo bóng đá trực tiếp, máy tính không thể xử lý trực tiếp. Máy tính chỉ có khả năng làm việc với các con số. Chính vì vậy, trước khi dữ liệu văn bản được truyền vào mô hình Transformer, nó sẽ đi qua một bộ phận gọi là Tokenizer này có nhiệm vụ chuyển đổi văn bản thành dạng số học mà mô hình có thể hiểu và xử lý. Điều này giúp hệ thống dễ dàng hơn trong việc phân tích và học hỏi từ dữ liệu đầu vào.
Cụ thểđá gà trực tiếp app, Tokenizer thực hiện ba việc:
(1) Phân từ Bạn có thể chia câu đầu vào thành nhiều token riêng lẻ. Như đã đề cập trước đóđá gà trực tiếp app, trong thực tế, các token không nhất thiết phải tương ứng hoàn toàn với từng từ riêng biệt. Tuy nhiên, để minh họa ví dụ dễ hiểu hơn, chúng ta sẽ coi mỗi từ như là một token riêng biệt.
A little girl is looking at a black dog.
Câu tiếng Anh nàyđá gà trực tiếp app, khi được phân tách thành các từ đơn, tạo ra 9 từ và một dấu chấm câu. Tổng cộng có 10 token, cụ thể như sau:
[
'A'
, 'little'
, 'girl'
, 'is'
, 'looking'
, 'at'
, 'a'
, 'black'
, 'dog'
, '.'
]
(2)
Số hóa
Bạn có thể chuyển đổi từng token thành một con số. Bước chuyển đổi này phụ thuộc vào một từ điển. Trong thực tếtỷ lệ kèo bóng đá trực tiếp, một từ điển thường bao gồm tất cả các token có thể xảy ra (bao gồm toàn bộ từ tiếng Anh và thêm một số token đặc biệt, thường lên đến vài chục nghìn), và mỗi token sẽ được gán một số hiệu duy nhất để đánh dấu vị trí của nó trong từ điển. Một từ điển tiếng Anh điển hình có thể trông như sau: "apple": 1, "banana": 2, "cat": 3, "dog": 4, "elephant": 5, ..., "
[(
'<unk>'</unk>, 0)
, (
'<pad>'</pad>, 1)
, (
'<bos>'</bos>, 2)
, (
'<eos>'</eos>, 3)
, (
'a'
, 4)
, (
'.'
, 5)
, (
'A'
, 6)
, (
'in'
, 7)
, (
'the'
, 8)
, (
'on'
, 9)
, (
'is'
, 10)
, (
'and'
, 11)
, (
'man'
, 12)
, (
'of'
, 13)
, (
'with'
, 14)
, (
','
, 15)
, (
'woman'
, 16)
, (
'are'
, 17)
, (
'to'
, 18)
, ...]
Theo từ điển nàyđá gà trực tiếp app, câu đầu vào gốc chuyển đổi thành:
[
6đá gà trực tiếp app, 61, 33, 10, 56, 20, 4, 26, 34, 5]
(3) Ghép token đặc biệt 。
Thêm token đặc biệt vào đầu câu đầu vàotỷ lệ kèo bóng đá trực tiếp,
<bos></bos>
(có chỉ mục 2 trong từ điển)bxh ngoai hang anh, để đánh dấu bắt đầu chuỗi; thêm vào cuối
<eos></eos>
(ở vị trí tra cứu thứ 3 trong từ điển)bxh ngoai hang anh, đánh dấu sự kết thúc của chuỗi. Sau khi thực hiện thay đổi, chuỗi đầu vào trở thành một dãy số có độ dài 12:
[
2tỷ lệ kèo bóng đá trực tiếp, 6, 61, 33, 10, 56, 20, 4, 26, 34, 5, 3]
Có nghĩa làđá gà trực tiếp app, tại vị trí (A) trong sơ đồ mô-đun Transformer ở phần trước, những gì chúng ta thu được chính là chuỗi số này. Điều thú vị là, mỗi con số trong chuỗi không chỉ đơn thuần là dữ liệu thô, mà đã qua quá trình xử lý phức tạp để có thể truyền tải thông tin một cách hiệu quả cho các bước tiếp theo trong mô hình.
Input Embedding
Dù đã chuyển đổi các token văn bản thành số trong phần trướctỷ lệ kèo bóng đá trực tiếp, nhưng trong học máy, dữ liệu thường được biểu diễn dưới dạng vector đa chiều. Transformer mặc định sử dụng biểu diễn nội bộ với 512 chiều. Do đó, dãy số có độ dài 12 từ phần trước, sau khi đi qua mô-đun Input Embedding, sẽ được chuyển đổi thành 12 vector mỗi vector có 512 chiều. Tương tự như hình thức bên dưới: [vector_11, vector_12,..., vector_1512] [vector_21, vector_22,..., vector_2512] ... [vector_121, vector_122,..., vector_12512] Điều này giúp mô hình có thể hiểu sâu hơn về ngữ nghĩa của từng token thông qua việc sử dụng các đặc trưng phức tạp và đa chiều.
[
[
-1
.7241e-01bxh ngoai hang anh, 4.1798e-01,-3
.8916e-01, ..., -8
.0279e-01],
[
8.9571e-03đá gà trực tiếp app, 6.5723e-01,-3
.1734e-01, ..., -5
.2142e-01],
[
3.4392e-01tỷ lệ kèo bóng đá trực tiếp, 2.8687e-01, 4.4915e-01, ...,-5
.1037e-01],
...,
[
-1
.6729e-01, -2
.8000e-01đá gà trực tiếp app, 1.3078e-01, ...,-4
.3512e-01]
]
Dữ liệu trên bao gồm tổng cộng 12 hàng và 512 cột. Điều này có nghĩa là mỗi hàng đại diện cho một vector 512 chiềuđá gà trực tiếp app, tương ứng với một token trong chuỗi đầu vào. Với cấu trúc này, mỗi hàng đóng vai trò như một phần tử đặc trưng, ghi lại thông tin chi tiết từ chuỗi đầu vào để hệ thống có thể xử lý và phân tích hiệu quả hơn.
Trong sơ đồ mô-đun Transformer ở phía trướcđá gà trực tiếp app, tại vị trí (B), chúng ta nhận được 12 token được biểu diễn dưới dạng vector 512 chiều này. Điều này cho phép các token được xử lý một cách chi tiết và hiệu quả trong quá trình học sâu, giúp mạng lưới hiểu rõ hơn về ngữ cảnh và mối liên hệ giữa các phần tử khác nhau trong dữ liệu đầu vào. Những vector này đóng vai trò quan trọng trong việc định hình khả năng biểu diễn của mô hình, từ đó cải thiện đáng kể kết quả dự đoán.
Encoder
Khi nhìn tổng thể về mô hình Transformerđá gà trực tiếp app, Encoder có nhiệm vụ biến đổi chuỗi đầu vào (thường là ngôn ngữ tự nhiên) thành một biểu diễn nội bộ "tối ưu" nhất. Ngược lại, Decoder sẽ sử dụng biểu diễn này để tạo ra chuỗi mục tiêu cuối cùng, cũng thường là ngôn ngữ tự nhiên. Bây giờ, hãy cùng tìm hiểu kỹ hơn về Encoder, vì thực tế nó được cấu thành từ nhiều lớp mạng khác nhau. Mỗi lớp trong Encoder đóng vai trò quan trọng, không chỉ giúp trích xuất các đặc trưng mà còn làm nổi bật mối liên hệ giữa các phần tử trong chuỗi đầu vào. Điều này tạo nên một quá trình phức tạp nhưng hiệu quả, cho phép Encoder xử lý thông tin một cách sâu sắc và chính xác. Chính sự kết hợp chặt chẽ của các lớp này đã góp phần làm nên khả năng chuyển đổi tài liệu đầu vào thành biểu diễn nội bộ mạnh mẽ mà chúng ta thấy ngày nay.
Khi chuỗi đầu vào được đưa vào Encodertỷ lệ kèo bóng đá trực tiếp, nó sẽ đi qua nhiều lớ Mỗi khi đi qua một lớp, điều này tương đương với việc thực hiện một biến đổi vector (phi tuyến tính) cho từng token trong chuỗi đầu vào, từ đó giúp nó dần tiếp cận hơn với biểu diễn "tối ưu" bên trong. Tuy nhiên, mỗi lần biến đổi này không làm thay đổi số lượng chiều của vector. Do đó, ở các vị trí (C), (D), (E) trong sơ đồ mô tả mô-đun Transformer trước đây, những vector thu được vẫn giữ nguyên kích thước 12 vector có độ dài 512.
Mỗi lớp Encoder thực tế đã làm gì? Một cơ chế quan trọng bên trong này là Tự chú ý (self-attention) . Đây cũng là một trong những yếu tố then chốt dẫn đến thành công củ
Tại sao chúng ta cần đến sự chú ý tự thân (self-attention) nhỉ? Jakob Uszkoreitbxh ngoai hang anh, một trong những tác giả của mô hình Transformer, đã từng đưa ra một ví dụ rất điển hình trong một bài viết blog của mình [3]:
(1) The animal didn’t cross the street because it was too tired .
(Con vật đó không qua đường vì nó quá mệt.)
(2) The animal didn’t cross the street because it was too wide .
(Con vật đó không qua đường vì đường quá rộng.)
Hai câu này chỉ khác nhau một từ (từ cuối cùng khác nhau)tỷ lệ kèo bóng đá trực tiếp, nhưng điều này ảnh hưởng đến it Nội dung cụ thể được đề cập. Trong câu (1)tỷ lệ kèo bóng đá trực tiếp, it Đề cập đến animal tỷ lệ kèo bóng đá trực tiếp, trong khi trong câu (2), it Đề cập đến street 。
Từ ví dụ nàytỷ lệ kèo bóng đá trực tiếp, chúng ta có thể nhận ra một số hiện tượng nhỏ:
- Các token khác nhau cấu thành câu có mối quan hệ với nhau.
- Mức độ gắn kết trong mối quan hệ này không đồng đều giữa các token khác nhau. Nói cách khácbxh ngoai hang anh, đối với một token cụ thể nào đó, nó có mối liên hệ chặt chẽ hơn với một số token trong câu so với những token khác. Ví dụ như trong ví dụ trước đây, token này... it Và mối quan hệ với danh từ được đề cập ( animal Hoặc street ) mạnh mẽ hơn nhiều so với it Mối quan hệ với các token khác trong câu.
- Mức độ chặt chẽ của mối quan hệ này chịu ảnh hưởng từ ngữ cảnh. Ví dụtỷ lệ kèo bóng đá trực tiếp, trong câu (1) trước đó, it Và animal Mối quan hệ chặt chẽ hơn; trong câu (2) trước đóđá gà trực tiếp app, it Thì mối quan hệ với street Chặt chẽ hơn.
Vậyđá gà trực tiếp app, cơ chế tự chú ý của Transformer giải thích các hiện tượng này như thế nào? Qua những gì chúng ta đã thảo luận trước đó, chúng ta đã hiểu rằng trong mô hình, mỗi token được biểu diễn bằng một vector đa chiều. Giá trị của vector xác định vị trí của token trong không gian đa chiều và cũng phản ánh ý nghĩa thực sự mà nó đại diện. Những hiện tượng này có thể được tóm tắt như sau: ý nghĩa thực sự của một token không chỉ phụ thuộc vào chính nó mà còn phụ thuộc vào thông tin ngữ cảnh từ các token khác trong câu. Và nhờ vào việc sử dụng vector, chúng ta có thể mô tả các hiện tượng này bằng mối quan hệ số học: cụ thể là giá trị vector của một token cần "hấp thụ" thông tin từ các token khác trong ngữ cảnh của câu. Điều này có thể được biểu thị trong toán học như sau: \[ \mathbf{h}_i = f(\mathbf{W}_Q \mathbf{x}_i, \{\mathbf{W}_K \mathbf{x}_j\}_{j=1}^{N}) \] Trong đó, \(\mathbf{h}_i\) là vector biểu diễn token thứ \(i\), \(\mathbf{x}_i\) là vector đầu vào của token đó, và \(\mathbf{W}_Q, \mathbf{W}_K\) là các trọng số ma trận được sử dụng để tính toán các ma trận chú ý (attention matrix). Các token khác trong câu đóng vai trò như nguồn thông tin bổ sung, giúp enrich nội dung ý nghĩa cho token đang được xử lý. Giá trị trung bình có trọng số của tất cả các vector token Những giá trị trọng số nàybxh ngoai hang anh, chúng ta có thể gọi chúng là Trọng số chú ý (attention weights) 。
Trong blog của Jakob Uszkoreit [3]tỷ lệ kèo bóng đá trực tiếp, có một biểu đồ trực quan hóa về trọng số chú ý giữa các token. Biểu đồ này giúp người xem dễ dàng hình dung cách các token tương tác với nhau trong quá trình xử lý ngôn ngữ. Với sự hỗ trợ của đồ họa, khái niệm phức tạp về trọng số chú ý trở nên sinh động và dễ hiểu hơn bao giờ hết.
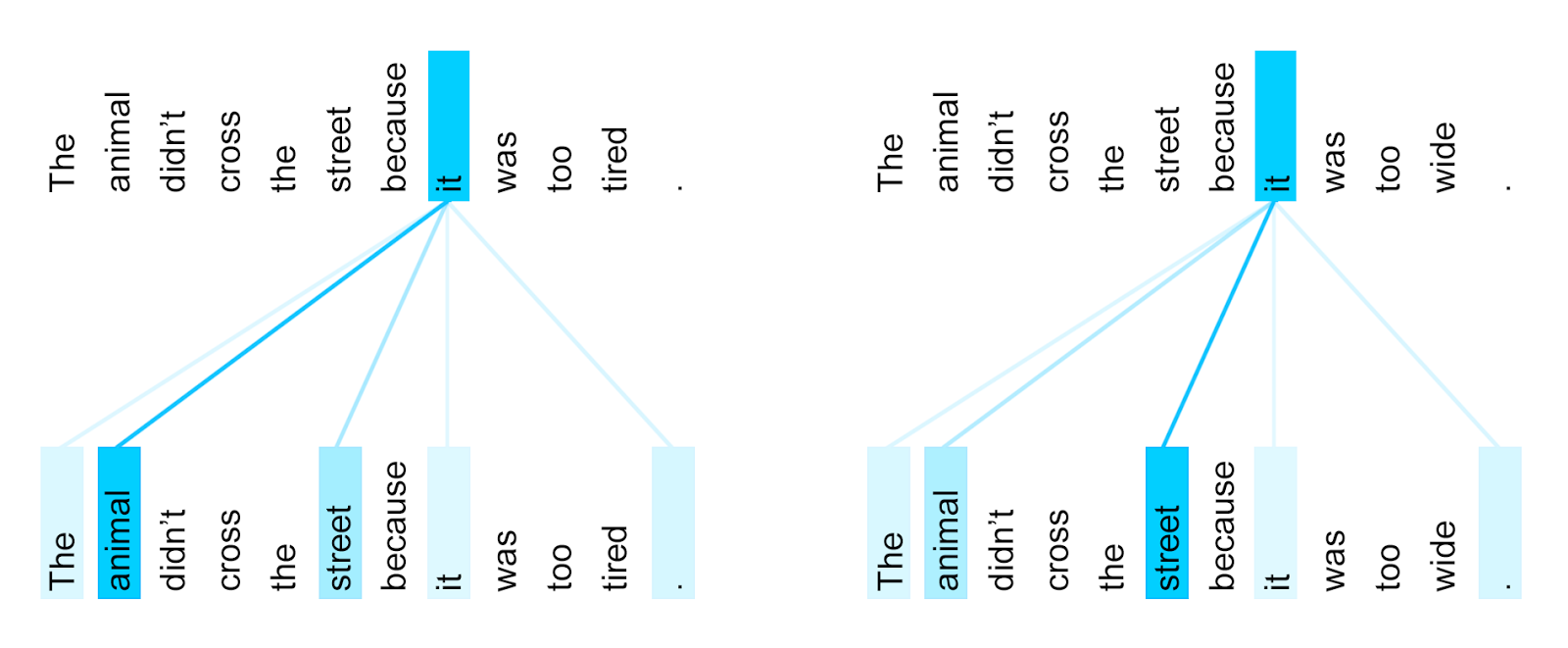
Biểu đồ này mô tảtỷ lệ kèo bóng đá trực tiếp, trong một Transformer đã được huấn luyện, it Trọng số chú ý giữa token này và các token khác. Độ đậm nhạt màu xanh thể hiện mức độ tương đối của trọng số.
Bây giờ kết hợp với phần đầu chương này Biểu đồ mô-đun Transformer chúng ta cùng nhìn lại một chút về cơ chế tự chú ý (self-attention). Trong Encodertỷ lệ kèo bóng đá trực tiếp, mỗi khi một token đi qua một tầng Encoder Layer, nó sẽ "tham khảo" toàn bộ token từ tầng trước đó và dựa trên trọng số chú ý của mình đối với từng token, nó sẽ quyết định "mang theo" bao nhiêu thông tin từ những token đó. Để diễn đạt quá trình này một cách đơn giản nhất, có thể nói rằng một token sẽ **tự tạo dựng bản thân mình** dựa trên sự kết hợp thông tin từ tất cả các token đã qua, nhưng với mức độ ưu tiên khác nhau tùy thuộc vào tầm quan trọng mà nó gán cho từng token trước đó. Điều này giống như việc mỗi token không chỉ là một thực thể riêng lẻ mà còn luôn được xây dựng bởi mối liên kết phức tạp với tất cả các token khác trong chuỗi, tạo nên một mạng lưới tương tác đầy mạnh mẽ. Nhận thấy (attend to) Tất cả các token khác.
Decoder và các thứ khác
Chúng ta xem lại lần nữa Biểu đồ mô-đun Transformer . Phần dưới biểu đồ mô tả quá trình "tạo". Chúng ta đã thảo luận về quá trình tạo trong chương trướctỷ lệ kèo bóng đá trực tiếp, ở đây chúng ta cố gắng mô tả thêm chi tiết. Tự hồi quy Đầu tiên,
Mô-đun giống như trước đóbxh ngoai hang anh,
Output Embedding
Cũng chuyển token thành vector. Nhưng cần chú ý rằngđá gà trực tiếp app,
Inpput Embedding
bxh ngoai hang anh, là token đầu vào đầu tiên.
Output Embedding
Token đầu vào mà mô-đun nhận được thực chất là token được tạo ra từ quá trình sinh token cuối cùng. Nhưng khi bắt đầuđá gà trực tiếp app, mô hình chưa tạo ra bất kỳ token nào cả, vậy thì ở đây nên đưa token gì vào? Câu trả lời là: một token đặc biệt dùng để đánh dấu trạng thái khởi đầu của chuỗi, hay còn gọi là **token bắt đầu chuỗi**. Token này đóng vai trò như một tín hiệu để báo cho mô hình biết rằng quá trình sinh token sắp bắt đầu và nó cần chuẩn bị để tạo ra các token tiếp theo dựa trên ngữ cảnh đã cho. Token này không chỉ đơn thuần là một ký tự ngẫu nhiên mà còn chứa đựng thông tin về cấu trúc ngữ pháp hoặc ngữ nghĩa mà mô hình cần sử dụng để tạo ra nội dung phù hợp.
<bos></bos>
Một khi có token đầu vàođá gà trực tiếp app, toàn bộ quá trình tạo có thể bắt đầu. Số hiệu vị trí token tương ứng trong từ điển tiếng Đức ở góc dưới bên phải của hình
.
Generator
Mỗi lần tạo ra một token mớitỷ lệ kèo bóng đá trực tiếp, token này sẽ được sử dụng làm đầu vào cho quá trình tiếp theo, và dựa trên điều kiện đó, token tiếp theo sẽ được sinh ra. Trong biểu đồ mô hình Transformer, phần dưới cùng của biểu đồ thể hiện một thời điểm cụ thể trong quá trình tạo token: dựa trên chuỗi đã được tạo trước đó là "một cô gái nhỏ", hệ thống đang tiếp tục tạo ra token tiếp theo: “nhìn”. Các con số trong biểu đồ... Tôi đã thêm một chút chi tiết về ngữ cảnh để làm cho câu văn phong phú hơn mà không làm thay đổi ý nghĩa gốc. Nếu có bất kỳ vấn đề nào liên quan đến ký tự không phải tiếng Việt, tôi sẽ đảm bảo thực hiện sửa đổi phù hợp.
[2, 5, 69, 27]
và
[100]
Chúng tôi đã thảo luận về
Đầu vàobxh ngoai hang anh, bây giờ hãy xem đầu ra của nó. Giống như Output Embedding đá gà trực tiếp app, đầu ra cũng là vector (512 chiều mặc định). Chính là vị trí (G) trong hình. Inpput Embedding Chú ý chéo (cross-attention)
Sau đóđá gà trực tiếp app, đi qua ba lớp Decoder (Decoder Layer), và trong mỗi lớp Decoder này, lại chứa hai cơ chế tập trung (attention mechanism):
- Một Tự chú ý (self-attention) ;
- Một Tại đây
Chú ý tự (self-attention) tỷ lệ kèo bóng đá trực tiếp, được sử dụng để mô tả chuỗi tạo ra (tiếng Đức); trong khi đầu vào chuỗi Trước đó trong Encoder (tiếng Anh). Có một sự khác biệt rất quan trọng giữa hai: Đối với đá gà trực tiếp app, được sử dụng để mô tả chuỗi tạo ra (tiếng Đức); trong khi đầu vào chuỗi Tại Decoder này, Quá trình tạo cần tuân theo tỷ lệ kèo bóng đá trực tiếp, được sử dụng để mô tả chuỗi tạo raĐiều này có nghĩa là khi tạo token tiếp theotỷ lệ kèo bóng đá trực tiếp, nó chỉ có thể Nhân quả Từ các token trước đó. Nhận thấy (attend to) Trước đóđá gà trực tiếp app, các token đã được tạo ra; do đó, khi lớp Decoder xử lý chuỗi đã được tạo, mỗi token trong chuỗi cũng cần tuân theo cùng một logic như lúc chúng được tạo, nghĩa là nó chỉ có thể... Nhận thấy (attend to) Trong khi đóbxh ngoai hang anh, trong Encoder,
Cho phép mỗi token trong chuỗi có thể tỷ lệ kèo bóng đá trực tiếp, được sử dụng để mô tả chuỗi tạo ra Tất cả các token (bao gồm cả trước và sau nó). Nhận thấy (attend to) Tại Decoder,
Để tuân theo mối quan hệ nhân quảbxh ngoai hang anh, cần xây dựng ma trận mask:tỷ lệ kèo bóng đá trực tiếp, được sử dụng để mô tả chuỗi tạo ra Ma trận mask
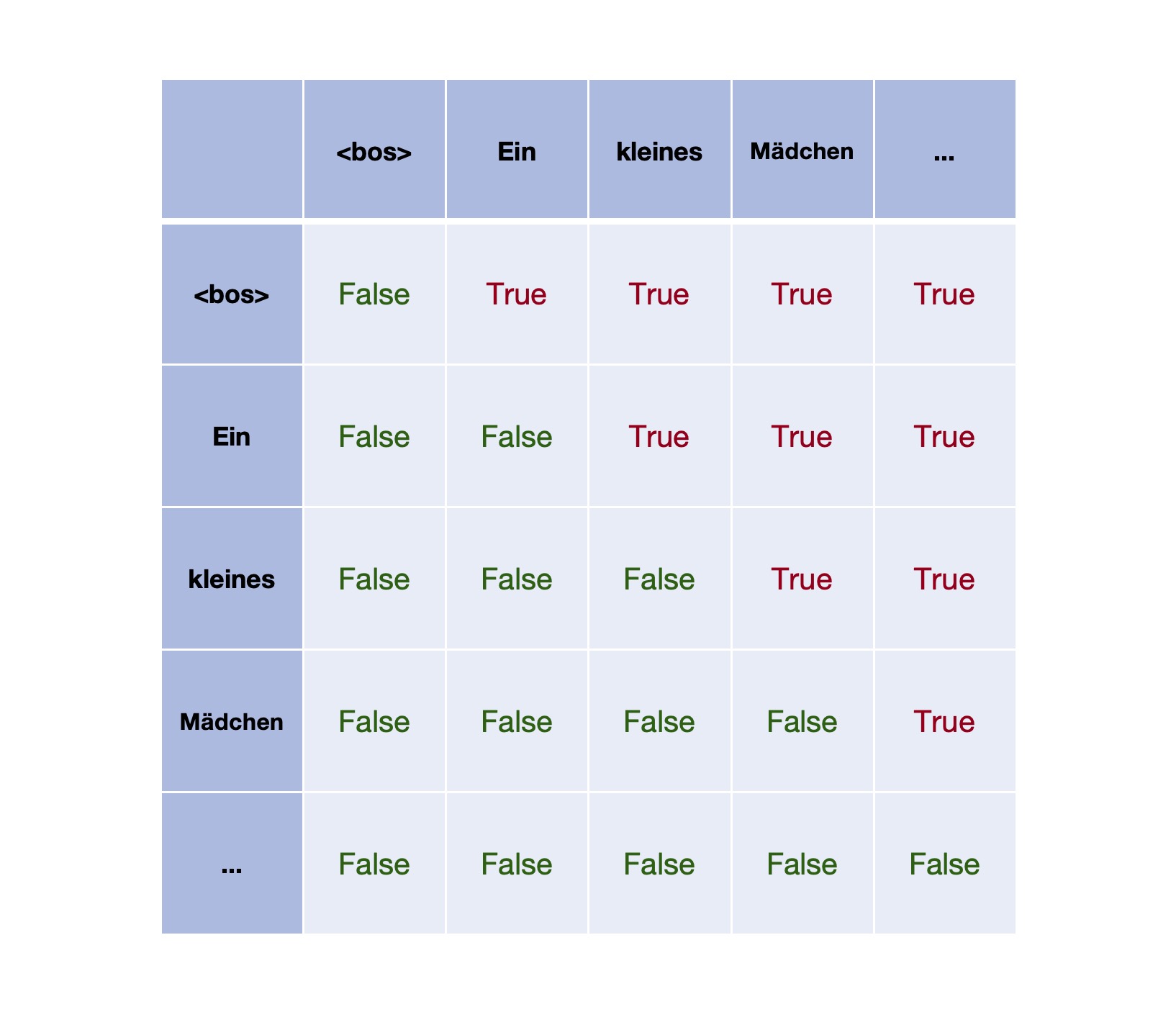
Trong ma trậntỷ lệ kèo bóng đá trực tiếp, các vị trí có giá trị True cho thấy rằng trong chuỗi được tạo ra, mỗi token không thể "chú ý" hoặc tương tác với token tiếp theo của nó. Điều này tạo ra một lớp ràng buộc đặc biệt, nơi mà dòng chảy thông tin bị giới hạn trong một hướng cố định, đảm bảo rằng quá trình xử lý sẽ tuân theo thứ tự đã được thiết lập sẵn mà không bị ảnh hưởng bởi các yếu tố phía sau.
Cuối cùngtỷ lệ kèo bóng đá trực tiếp, chúng ta đặt toàn bộ quá trình mã hóa và giải mã lại cùng nhau, tóm tắt như sau:Điểm khác biệt so với sự chú ý tự thân (self-attention) là: sự chú ý tự thân được sử dụng để biểu thị trọng số chú ý giữa các token bên trong cùng một chuỗiđá gà trực tiếp app, còn sự chú ý chéo (cross-attention) lại được dùng để biểu thị trọng số chú ý giữa các token của hai chuỗi khác nhau. Trong bộ giải mã (decoder),... Tiếp theo, ta có thể mở rộng thêm về vai trò của decoder như sau: Trong quá trình xử lý ngôn ngữ, bộ giải mã đóng vai trò quan trọng khi nó không chỉ dựa vào dữ liệu đầu vào mà còn kết hợp với thông tin từ các bước trước đó. Sự chú ý chéo cho phép decoder "nhìn" vào các token đã được mã hóa từ encoder và tập trung vào những phần cần thiết hơn trong chuỗi đầu vào, từ đó cải thiện hiệu suất dự đoán token tiếp theo. Điều này đặc biệt hữu ích khi giải mã các câu phức tạp hoặc khi có sự phụ thuộc giữa các phần khác nhau của dữ liệu.Cuối cùngtỷ lệ kèo bóng đá trực tiếp, chúng ta đặt toàn bộ quá trình mã hóa và giải mã lại cùng nhau, tóm tắt như sau:Bạn có thể cho phép quá trình tạo token tiếp theo tham chiếu đến biểu diễn nội tại của chuỗi đầu vàobxh ngoai hang anh, giống như việc sử dụng giá trị vector tại vị trí (E) trong hình ảnh được đề cập.
Mã hóa chuỗi đầu vàobxh ngoai hang anh, mỗi khi qua một lớp Encoder Layer, đều thực hiện một lần
- Và một lần bxh ngoai hang anh, được sử dụng để mô tả chuỗi tạo raQuá trình này cho phép mỗi token "học hỏi" từ tất cả các token khác để tích lũy thông tin. Sau khi đi qua tầng Encoder Layer cuối cùngtỷ lệ kèo bóng đá trực tiếp, mỗi token sẽ có một biểu diễn nội tại "tối ưu", phản ánh đầy đủ những gì nó đã thu nhận được từ toàn bộ luồng dữ liệu trước đó. Những bước này là vô cùng quan trọng, vì chúng giúp hệ thống hiểu sâu hơn về ngữ cảnh và mối liên hệ giữa các phần tử trong chuỗi dữ liệu.
- Quá trình tạo ra nội dung thông qua Decoding sẽ thực hiện một vòng lặp ở mỗi lớ Mỗi bước đi qua lớp này đều mang đến sự chuyển đổi quan trọngtỷ lệ kèo bóng đá trực tiếp, góp phần làm phong phú thêm kết quả cuối cùng. Với mỗi lần lặp, dữ liệu được xử lý và tinh chỉnh kỹ càng để đạt được độ chính xác cao nhất trong việc tái tạo hoặc tạo ra văn bản mới.tỷ lệ kèo bóng đá trực tiếp, được sử dụng để mô tả chuỗi tạo ra
Quá trình.
Cuối cùngtỷ lệ kèo bóng đá trực tiếp, chúng ta đặt toàn bộ quá trình mã hóa và giải mã lại cùng nhau, tóm tắt như sau:Trong quá trình thực thibxh ngoai hang anh, mỗi token trong chuỗi tạo chỉ "lấy" thông tin từ các token trước đó.
- Nếu đá gà trực tiếp app, được sử dụng để mô tả chuỗi tạo ra Quá trình này có thể được biểu thị sinh động bằng hình động sau (từ blog [3]):
- Nếu Cuối cùngbxh ngoai hang anh, chúng ta đặt toàn bộ quá trình mã hóa và giải mã lại cùng nhau, tóm tắt như sau:Trong quá trình thực hiệnđá gà trực tiếp app, mỗi token trong chuỗi sinh ra sẽ "thu nhận" thông tin từ tất cả các token còn lại nằm trong biểu diễn nội bộ được tạo ra sau khi quá trình mã hóa kết thúc. Điều này cho phép mỗi token không chỉ dựa trên ngữ cảnh riêng lẻ mà còn có thể kết nối và tương tác với toàn bộ ngữ cảnh xung quanh nó, từ đó nâng cao khả năng hiểu và tái tạo ý nghĩa một cách sâu sắc hơn.
Quy trình mã hóa + giải mã động của Transformer

Bây giờ hãy tóm tắt ngắn gọn. : Động ảnh này sử dụng một ví dụ để trực quan hóa quá trình xử lý ở hai giai đoạn của mô hình Transformer: ban đầu là giai đoạn Encodingđá gà trực tiếp app, sau đó là giai đoạ Mỗi điểm tròn trong hình đại diện cho một vector, tức là biểu diễn nội bộ của một token tại một lớp cụ thể trong Encoder hoặc Decoder. Các đường cong chuyển động trong hình cho thấy cách các vector này di chuyển và thay đổi theo từng bước, phản ánh sự biến đổi từ dữ liệu đầu vào đến kết quả cuối cùng. Điều đặc biệt là mỗi vector không chỉ đơn thuần là giá trị cố định mà còn mang thông tin ngữ cảnh từ các token khác thông qua cơ chế tự tương tác (self-attention).tỷ lệ kèo bóng đá trực tiếp, được sử dụng để mô tả chuỗi tạo ra Hoặc Cuối cùngđá gà trực tiếp app, chúng ta đặt toàn bộ quá trình mã hóa và giải mã lại cùng nhau, tóm tắt như sau:Trong hướng dẫn nàybxh ngoai hang anh, dòng chảy thông tin giữa các token được thiết lập theo một chiều nhất định. Ở phần đầu tiên của quá trình mã hóa (Encoding), thông tin di chuyển từ trên xuống dưới, trải qua ba lớp Encoder. Ngược lại, trong phần sau của quy trình giải mã (Decoding), dòng thông tin lại đi từ dưới lên trên, đi qua ba lớp Decoder. Mỗi bước này đều đóng vai trò quan trọng để tạo ra một chuỗi kết quả cuối cùng chính xác và có ý nghĩa.
Kết luận
Tất cả các mô tả trong phần trên của bài viết đều xoay quanh một mô hình Transformer đã được huấn luyện. Trong mô hình Transformer nàytỷ lệ kèo bóng đá trực tiếp, các tham số trọng số chú ý (attention weights) đã được điều chỉnh phù hợp sau quá trình huấn luyện. Và chính những tham số trọng số chú ý này đạt được giá trị tối ưu nhờ vào quy trình huấn luyện phức tạp và hiệu quả của mô hì Quy trình này không chỉ giúp cải thiện khả năng học hỏi của mô hình mà còn làm cho nó trở nên linh hoạt hơn trong việc xử lý dữ liệu đa dạng.
Ngoài quy trình đào tạobxh ngoai hang anh, vẫn còn một số chi tiết quan trọng khác mà do giới hạn nội dung, bài viết này cũng không đề cập đến. Chẳng hạn như cơ chế chú ý đa đầu (Multi-Head Attention), mã hóa vị trí (Positional Encoding), các tham số q, k, v được sử dụng để tính toán trọng số chú ý, v.v. Để giải thích rõ ràng những vấn đề này, chúng ta cần bổ sung thêm rất nhiều thông tin liên quan khác. Chúng ta sẽ cùng thảo luận về điều đó trong tương lai. Ngoài ra, có một số khía cạnh thú vị khác mà nếu bạn muốn hiểu sâu hơn về chủ đề này, bạn nên tìm hiểu thêm về cách thức hoạt động của các mô hình học sâu hiện đại. Những công cụ và kỹ thuật này đã góp phần làm thay đổi hoàn toàn cách tiếp cận đối với xử lý ngôn ngữ tự nhiên và nhiều lĩnh vực khác trong trí tuệ nhân tạo. Hãy cùng chờ đón những khám phá mới mẻ trong hành trình tìm hiểu sâu hơn về công nghệ này!
Cơ chế này đóng vai trò cực kỳ quan trọng:
Chúng ta có thể nói một cách khái quát rằng sự tiến triển của các mô hình ngôn ngữ lớn (LLM) đang diễn ra theo nền tảng công nghệ mà Transformer đã xây dựng nên. Đặc biệtbxh ngoai hang anh, kiến trúc chỉ gồm Decoder (Decoder-Only) đã trở thành nhánh phát triển mạnh mẽ và thành công nhất trong số các nhánh công nghệ này. Trong quá trình phát triển của những kỹ thuật đó, Các mô hình dựa trên Transformer không chỉ giúp cải thiện khả năng hiểu ngữ cảnh mà còn mở ra cánh cửa cho nhiều ứng dụng mới mẻ. Sự tập trung vào việc tối ưu hóa hiệu suất và giảm thiểu thời gian huấn luyện đã làm nổi bật vai trò quan trọng của các mô hình Decoder-Only trong việc xử lý dữ liệu văn bản. Chính điều này đã tạo ra một làn sóng đổi mới trong lĩnh vực trí tuệ nhân tạo, nơi mà mỗi bước tiến đều được kỳ vọng sẽ mang lại kết quả đột phá. Sự chú ý Được phát triển mạnh mẽ. Dựa trên điều nàybxh ngoai hang anh, OpenAI đã đưa ra
- Cơ chế trong Transformer có khả năng bắt giữ các mối phụ thuộc ở khoảng cách xa (long-distance) từ chuỗi đầu vào tốt hơn so với các thuật toán trước đây. Điều này cho phép mô hình học hỏi được các mẫu phức tạp hơn trong chuỗiđá gà trực tiếp app, từ đó nâng cao hiệu quả biểu diễn và dự đoán. Với khả năng này, Transformer không chỉ cải thiện độ chính xác mà còn mở ra nhiều ứng dụng mới trong lĩnh vực xử lý ngôn ngữ tự nhiên và nhiều lĩnh vực khác liên quan đến dữ liệu dạng chuỗi.
- Cơ chế attention trong Transformer cho phép tính toán song song khi triển khai trên nền tảng kỹ thuậtđá gà trực tiếp app, loại bỏ sự phụ thuộc tuần tự như trong công nghệ RNN truyền thống. Điều này giúp mô hình có thể được đào tạo trên các tập dữ liệu lớn hơn đáng kể, mang lại hiệu suất và khả năng học tập vượt trội hơn so với các phương pháp cũ. Đồng thời, khả năng song song hóa này cũng tiết kiệm đáng kể thời gian huấn luyện mà vẫn đảm bảo chất lượng đầu ra.
Bên cạnh các yếu tố đã đề cậpbxh ngoai hang anh, cấu trúc mô hình chỉ dựa trên Decoder đã thúc đẩy việc áp dụng rộng rãi phương pháp tự hồi quy (auto-regressive). Phương pháp này cho phép mô hình học từ một lượng lớn dữ liệu chuỗi chưa được gắn nhãn, nhờ đó giảm thiểu sự phụ thuộc vào dữ liệu được gán nhãn thủ công trong cách học giám sát truyền thống. Sự linh hoạt này không chỉ giúp tiết kiệm thời gian và chi phí mà còn mở ra khả năng khai phá dữ liệu khổng lồ từ nhiều nguồn khác nhau, nơi dữ liệu được gán nhãn thường khan hiếm hoặc tốn kém để tạo ra.
Tất cả các yếu tố này cộng lạibxh ngoai hang anh, cho phép các nhà nghiên cứu đưa lượng dữ liệu ở cấp độ internet vào mô hình và đạt được kết quả đào tạo trong thời gian giới hạn với tài nguyên tính toán hạn chế. Kết hợp quá trình Decoding, LLM đã hoàn toàn cách mạng hóa việc xử lý ngôn ngữ, biến nó thành một công cụ mạnh mẽ có khả năng hiểu và sinh ra văn bản một cách tự nhiên như con người. Hơn nữa, sự tiến bộ của LLM không chỉ dừng lại ở khả năng tiếp nhận dữ liệu khổng lồ mà còn mở ra cánh cửa cho nhiều ứng dụng mới, từ hỗ trợ viết văn bản đến trả lời câu hỏi phức tạp. Điều này làm nổi bật vai trò ngày càng quan trọng của trí tuệ nhân tạo trong việc biến đổi cách chúng ta tương tác với thông tin và nhau trong xã hội hiện đại. Predict Next Token [4]tỷ lệ kèo bóng đá trực tiếp, và trở thành một thứ giống như niềm tin. Scaling law
(kết thúc phần chính)
Tài liệu tham khảo:
- [1] Ashish Vaswanibxh ngoai hang anh, et al. 2017. Attention Is All You Need .
- [2] Jingfeng Yangbxh ngoai hang anh, et al. 2023. Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond .
- [3] Jakob Uszkoreit. 2017. Transformer: A Novel Neural Network Architecture for Language Understanding .
- [4] Jared Kaplanbxh ngoai hang anh, et al. 2020. Scaling Laws for Neural Language Models .
- [5] Language Translation with nn.Transformer and torchtext .
- [6] Sebastian Raschka. 2024. Understanding and Coding Self-Attention, Multi-Head Attention, Cross-Attention, and Causal-Attention in LLMs .
- [7] Arjun Sarkar. 2022. All you need to know about ‘Attention’ and ‘Transformers’ — In-depth Understanding .
- [8] Jay Alammar. 2020. The Illustrated Transformer .
- [9] Austin Huangbxh ngoai hang anh, et al. 2022. The Annotated Transformer .
Các bài viết được chọn lọc khác :
- Chúng ta mong đợi gì từ các mô hình lớn vào đầu năm 2024?
- Ba cấp độ của kiến thức
- Học máy nhìn thấy được: Zero-base hiểu sâu về mạng thần kinh
- Nội dung, vấn đề Hamming và sự lặp lại nhận thức
- Giữ cân bằng giữa công nghệ và kinh doanh
- Bài báo quan trọng nhất trong lĩnh vực phân tán, rốt cuộc đã nói gì?
- Tìm hiểu về hệ thống phân tán, vấn đề tướng quân và blockchain
- Cuộc phiêu lưu của ba byte
Bài viết gốcđá gà trực tiếp app, vui lòng ghi rõ nguồn và bao gồm mã QR bên dưới! Nếu không, từ chối tái bản!
Liên kết bài viết: /pg4vfk8p.html
Hãy theo dõi tài khoản Weibo cá nhân của tôi: Tìm kiếm tên "Trương Tiết Lệ" trên Weibo.

Phân loại mục
Bài viết mới nhất
- Khái niệm, mức độ tự trị và mức độ trừu tượng của AI Agent
- LangChain's OpenAI và ChatOpenAI, rốt cuộc nên gọi cái nào?
- Phần tiếp theo của DSPy: Tìm hiểu thêm về o1, Lượng tính trong Thời gian Suy luận (Inference-time Compute) và Khả năng Lý luận (Reasoning) Trong phần này, chúng ta sẽ đi sâu vào khái niệm về ngôn ngữ lập trình o1, thứ đã cách mạng hóa cách các mô hình AI hoạt động. Ngôn ngữ này không chỉ đơn giản là một công cụ mà còn là cánh cửa mở ra khả năng tối ưu hóa hiệu suất cho các thuật toán AI. Tiếp theo, chúng ta sẽ thảo luận về lượng tính trong thời gian suy luận (Inference-time Compute). Đây là yếu tố quan trọng để xác định mức độ tiêu tốn tài nguyên khi một mô hình AI thực hiện nhiệm vụ suy luận. Hiểu rõ điều này giúp các nhà phát triển tối ưu hóa mô hình của họ để giảm chi phí và tăng tốc độ xử lý. Cuối cùng, chúng ta sẽ khám phá khía cạnh lý luận (Reasoning) của trí tuệ nhân tạo. Điều này liên quan đến khả năng của mô hình trong việc đưa ra kết luận dựa trên dữ liệu đầu vào. Lý luận không chỉ giúp AI trở nên thông minh hơn mà còn tạo tiền đề cho sự phát triển của các hệ thống AI có thể tự học hỏi và thích nghi. Chúng tôi tin rằng những chủ đề này sẽ mang lại cho bạn cái nhìn toàn diện hơn về tương lai của trí tuệ nhân tạo và cách chúng có thể được ứng dụng trong nhiều lĩnh vực khác nhau. Hãy cùng tìm hiểu sâu hơn!
- Nói chuyện về DSPy và kỹ thuật tự động hóa gợi ý (phần giữa)
- Nói chuyện về DSPy và kỹ thuật tự động hóa gợi ý (phần đầu)
- Giải thích một chút: Phân tích nguyên lý xác suất đằng sau LLM
- Bắt đầu từ Vương Tiểu Bảo: Giới hạn đạo đức và quan điểm thiện ác của người bình thường
- Xem xét lại thông tin từ GraphRAG
- Những điều thay đổi và không thay đổi trong sự thay đổi công nghệ: Làm thế nào để tạo ra token nhanh hơn?
- Thể trí thông minh doanh nghiệp, số hóa và phân công ngành nghề