Bạn nên bắt đầu đọc mã nguồn của Redis từ đâu?
2019-02-07
Kể từ khi tôi viết bài... Phân tích cấu trúc dữ liệu nội bộ của Redis git clone https://github.com/redis/redis.git
Redis được viết bằng ngôn ngữ Ctai ban ca, và khi bắt đầu đọc mã nguồn của nó, tất nhiên bạn nên bắt đầu từ hàm main. Tuy nhiên, khi đọc, bạn cần nắm vững một đường dây chính: đó là khi chúng ta gửi một lệnh vào Redis, mã nguồn sẽ thực hiện theo trình tự nào. Bằng cách này, trước tiên bạn có thể quan sát từ bên ngoài, thử chạy một số lệnh và hiểu rõ cách hoạt động bên ngoài của các lệnh đó. Sau đó, bạn có thể đi sâu hơn để xem mã nguồn tương ứng đã được triển khai như thế nào. Để hiểu được mã nguồn này, trước hết bạn cần hiểu rõ cơ chế sự kiện của Redis. Và khi hiểu rõ cơ chế vòng lặp sự kiện (Event Loop) của Redis, bạn sẽ còn giải đáp được một câu hỏi thú vị: Tại sao Redis lại chỉ sử dụng một luồng mà vẫn có thể xử lý nhiều yêu cầu cùng lúc? (Dĩ nhiên, nói một cách nghiêm ngặt thì Redis không phải chỉ chạy duy nhất một luồng; nhưng ngoài luồng chính ra, các luồng khác của Redis chỉ đóng vai trò hỗ trợ, là những luồng chạy nền để thực hiện các tác vụ tốn thời gian một cách bất đồng). Bạn cũng cần lưu ý rằng, mặc dù Redis chủ yếu hoạt động trên một luồng chính, các yêu cầu sẽ được xử lý tuần tự và không bị gián đoạn bởi các tác vụ nền. Điều này giúp tăng cường hiệu quả và tối ưu hóa trong việc quản lý tài nguyên. Khi hiểu được điều này, bạn sẽ nhận ra rằng Redis đã được thiết kế rất thông minh để tận dụng tối đa hiệu suất mà không cần sử dụng nhiều luồng phức tạp. Hãy tưởng tượng rằng bạn đang đứng trước một cỗ máy khổng lồ với vô số bộ phận chuyển động. Bạn không cần phải hiểu tất cả mọi thứ ngay lập tức, nhưng nếu bạn biết cách quan sát từ bên ngoài, sau đó dần dần khám phá từng phần bên trong, bạn sẽ hiểu rõ hơn về cách nó vận hành. Với Redis, việc hiểu rõ sự kiện và vòng lặp sự kiện chính là chìa khóa để mở cánh cửa dẫn đến thế giới của mã nguồn đầy thú vị này.
Từ hàm mainkeo 88, chúng ta có thể lần theo đường dẫn thực thi của mã nguồn một cách liên tục. Tuy nhiên, để tránh làm bài viết trở nên quá dài dòng, chúng ta cần giới hạn phạm vi bàn luận. Mục tiêu chính của bài viết này là hướng dẫn người đọc bắt đầu từ hàm main và lần lượt đi sâu vào mã nguồn cho đến khi đạt đến điểm nhập khẩu của bất kỳ lệnh Redis nào. Khi đã hiểu rõ được hành trình này, người đọc sẽ có cái nhìn tổng quan hơn về cách thức hoạt động bên trong hệ thống Redis, từ đó dễ dàng tiếp cận với các phân tích sâu hơn phía trước. Phân tích cấu trúc dữ liệu nội bộ của Redis Một loạt bài viết này đã nối tiếp nhau. Hoặctỷ lệ kèo bóng đá trực tiếp, bạn cũng có thể tự mình khám phá phần còn lại.
Để diễn đạt rõ ràngtai ban ca, bài viết này sẽ tiến hành theo ý tưởng sau đây:
- Đầu tiên là tóm tắt toàn bộ quy trình khởi tạo mã nguồn (từ hàm main) và cấu trúc vòng lặp sự kiện;
- Sau đó tóm tắt quy trình xử lý yêu cầu lệnh Redis;
- Tập trung giới thiệu cơ chế sự kiện;
- Đối với từng quy trình xử lý mã nguồn được giới thiệu trước đótỷ lệ kèo bóng đá trực tiếp, cung cấp mối quan hệ gọi mã chi tiết để thuận tiện cho việc tham khảo bất cứ lúc nào;
Dựa trên việc phân chia nàytỷ lệ kèo bóng đá trực tiếp, nếu bạn chỉ muốn đọc lướt qua để nắm được quy trình xử lý chính, thì chỉ cần đọc hai phần đầu là đủ. Hai phần sau sẽ đi sâu vào những chi tiết quan trọng mà bạn nên chú ý.
Chú thích: Phân tích trong bài viết này dựa trên nhánh mã nguồn 5.0 của Redis.
Khái quát về quy trình khởi tạo và vòng lặp sự kiện
Hàm main của Redis được tìm thấy trong tệp nguồn server.c. Sau khi hàm main bắt đầu thực thitai ban ca, logic chính có thể được chia thành hai giai đoạn rõ rệt:
- Các bước khởi tạo khác nhau (bao gồm cả việc khởi tạo vòng lặp sự kiện);
- Thực hiện vòng lặp sự kiện.
Hai giai đoạn thực thi này có thể được biểu thị bằng sơ đồ quy trình dưới đây (nhấn để xem lớn hơn):
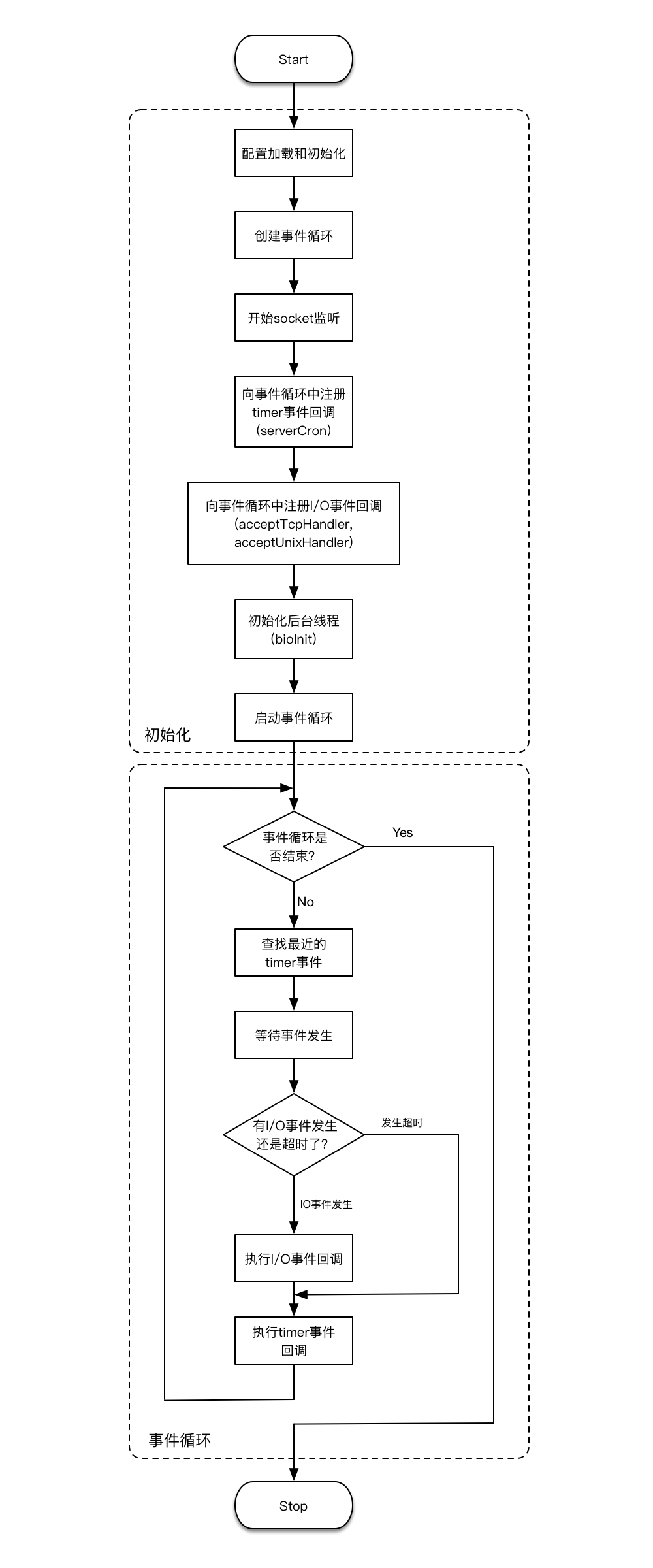
Trước tiênkeo 88, chúng ta hãy xem xét từng bước trong giai đoạn khởi tạo:
-
Tải cấu hình và khởi tạo
Bước này thể hiện quá trình khởi tạo cấu trúc dữ liệu cơ bản và các tham số khác của máy chủ Redis. Trong mã nguồn Redistai ban ca, máy chủ Redis được biểu diễn dưới dạng một cấu trúc (struct) được gọi là `redisServer`, nơi chứa tất cả các thông tin và tham số cần thiết để máy chủ hoạt động. Các thông tin này bao gồm cổng mà máy chủ đang lắng nghe, mô tả tệp (file descriptor), các kết nối client hiện tại, bảng lệnh Redis (command table), các tham số liên quan đến việc lưu trữ dữ liệu (persistence), và nhiều yếu tố khác nữa. Đặc biệt, nó còn bao gồm cấu trúc vòng lặp sự kiện (event loop), mà chúng ta sẽ tìm hiểu thêm trong phần tiếp theo. Khi chạy, máy chủ Redis thực chất được duy trì và điều hành bởi một đối tượng `redisServer` này.
redisServerBiến toàn cục loại này để biểu thị (tên biến là)serverBước này chủ yếu tập trung vào việc khởi tạo biến toàn cục. Trong quá trình khởi tạotỷ lệ kèo bóng đá trực tiếp, có một hàm cần đặc biệt chú ý:populateCommandTableNó khởi tạo bảng lệnh Redistỷ lệ kèo bóng đá trực tiếp, qua đó có thể tìm thấy thông tin cấu hình của bất kỳ lệnh Redis nào chỉ bằng tên của lệnh đó (ví dụ như số lượng tham số lệnh mà lệnh đó nhận, hàm thực thi được liên kết với nó, v.v.). Trong phần hai của bài viết này, chúng ta sẽ cùng nhau khám phá cách một yêu cầu Redis bắt đầu từ việc nhận lệnh, đi qua từng bước thực hiện, cho đến khi tra cứu bảng lệnh này để xác định nơi bắt đầu thực thi lệnh. Ngoài ra, ở bước này còn có một điểm đáng chú ý: trong quá trình xử lý toàn cục của...redisServerSau khi cấu trúc được khởi tạokeo 88, bạn cần tải các cấu hình từ tệp cấu hình (redis.conf). Quá trình này có thể ghi đè lên các thiết lập mà bạn đã đặt trước đó trong quá trình khởi tạo. Điều quan trọng là phải kiểm tra kỹ lưỡng các giá trị hiện tại để đảm bảo không có sự nhầm lẫn nào xảy ra giữa những thiết lập cũ và mới.redisServerTrong cấu trúc nàytỷ lệ kèo bóng đá trực tiếp, một số tham số cụ thể sẽ được xử lý theo cách sau: trước tiên, quá trình khởi tạo ban đầu sẽ diễn ra để đảm bảo rằng các cấu trúc dữ liệu nội bộ cũng như các tham số của Redis đều có giá trị mặc định. Sau đó, hệ thống sẽ tiếp tục tải các cấu hình tùy chỉnh từ tệp cấu hình để điều chỉnh những thông số cần thiết theo yêu cầu cụ thể. -
Tạo vòng lặp sự kiện
Trong Rediskeo 88, vòng lặp sự kiện được biểu thị bằng một cấu trúc gọi là
aeEventLooptạo vòng lặp sự kiệnaeEventLoopKết cấu và lưu trữ vàoserverBiến toàn cục (tức là biến mà chúng ta đã đề cập trước đó)redisServerBạn có thể thực hiện việc này trong cấu trúc của loại (type structure). Ngoài ratai ban ca, vòng lặp sự kiện phụ thuộc vào cơ chế đa hóa nhập xuất (I/O multiplexing) ở tầng nền hệ thống, chẳng hạn như trên hệ điều hành Linux: Cụ thể hơn, khi một ứng dụng chạy trên môi trường Linux, vòng lặp sự kiện sẽ tận dụng các công cụ như hệ thống gọi `select()`, `poll()` hoặc `epoll()` để theo dõi trạng thái của nhiều luồng I/O cùng một lúc. Điều này giúp tối ưu hóa hiệu suất bằng cách giảm thiểu thời gian chờ đợi cho các hoạt động nhập/xuất. Hệ thống I/O đa luồng này không chỉ tăng cường khả năng xử lý đồng thời mà còn làm giảm tải cho CPU khi quản lý nhiều nguồn dữ liệu khác nhau. Hơn nữa, nhờ vào cơ chế này, các tác vụ lớn như truyền tải tệp, kết nối mạng hay tương tác với thiết bị ngoại vi đều có thể được thực hiện hiệu quả mà không làm chậm tốc độ phản hồi của chương trình. Đây là một trong những yếu tố quan trọng giúp lập trình hướng sự kiện trở nên mạnh mẽ và linh hoạt trong các hệ thống hiện đại. Cơ chế epoll [1]. Do đótỷ lệ kèo bóng đá trực tiếp, bước này cũng bao gồm việc khởi tạo cơ chế đa luồng I/O phía dưới (gọi API hệ thống). -
Bắt đầu lắng nghe socket
Chương trình máy chủ cần lắng nghe để nhận các yêu cầu. Tùy thuộc vào cấu hìnhtỷ lệ kèo bóng đá trực tiếp, bước này có thể mở hai loại kết nối lắng nghe: một cho các kết nối TCP và một cho... (Phần còn lại của câu không được cung cấp nên tôi sẽ tiếp tục sáng tạo thêm một chút.) ...các yêu cầu qua giao thức UDP. Điều này giúp máy chủ linh hoạt hơn trong việc xử lý đa dạng các loại kết nối từ phía client. Mỗi loại kết nối sẽ yêu cầu thiết lập các tham số riêng biệt như cổng, địa chỉ IP, và độ trễ tối đa cho phép. Khi lắng nghe trên cả hai giao thức, hệ thống sẽ có khả năng xử lý đồng thời nhiều loại yêu cầu khác nhau mà không bị giới hạn bởi một phương thức duy nhất. Đây là một kỹ thuật quan trọng trong việc xây dựng các dịch vụ mạng ổn định và hiệu quả.
Unix domain socket
Unix domain socket
IPC
[3]), và trong
POSIX
Tiêu chuẩn [4] cũng có
Định nghĩa rõ ràng
socket miền Unix
serverTrong phạm vi biến toàn cụctỷ lệ kèo bóng đá trực tiếp, đối với việc lắng nghe giao thức TCP, vì địa chỉ IP và cổng có thể được kết nối với nhiều luồng khác nhau, nên mô tả tệp (file descriptor) dùng để lắng nghe các kết nối TCP cũng có thể chứa nhiều giá trị. Sau đó, chương trình sẽ sử dụng các mô tả tệp này để đăng ký các sự kiện I/O và thiết lập hàm gọi trả về tương ứng. Điều này giúp chương trình dễ dàng xử lý các yêu cầu từ nhiều nguồn khác nhau một cách linh hoạt và hiệu quả. -
Đăng ký sự kiện timer callback
Rediskeo 88, với bản chất là một chương trình chạy trên duy nhất một luồng (single-threaded), cần phải dựa vào cơ chế vòng lặp sự kiện (event loop) để có thể quản lý và thực thi các tác vụ chạy nền hoặc định kỳ. Ví dụ như việc dọn dẹp các khóa (keys) đã hết hạn theo chu kỳ, Redis không còn cách nào khác ngoài việc sử dụng vòng lặp này. Quá trình này bao gồm việc đăng ký một sự kiện thời gian (timer event) vào vòng lặp sự kiện mà chúng ta vừa tạo ra trước đó, đồng thời thiết lập nó để thực hiện lặp đi lặp lại một hàm callback tại mỗi khoảng thời gian cụ thể.
serverCronDo Redis chỉ có một luồng chínhtai ban ca, hàm này sẽ được thực hiện định kỳ ngay trong chính luồng đó. Nó được kích hoạt bởi vòng lặp sự kiện (tức được gọi vào thời điểm phù hợp), nhưng điều này không làm gián đoạn việc thực thi các logic khác cùng trên luồng đó (giống như việc phân chia thời gian để xử lý từng tác vụ riêng biệt).serverCronBạn có thể tự hỏi hàm này thực sự làm gì? Thực tếtỷ lệ kèo bóng đá trực tiếp, ngoài việc định kỳ thu hồi các key đã hết hạn, nó còn đảm nhận nhiều nhiệm vụ khác như kết nối lại giữa chủ và nô lệ, tái kết nối giữa các nút trong Cluster, cũng như kích hoạt và thực thi các lệnh BGSAVE và Tuy nhiên, đây không phải là trọng tâm của bài viết này, nên mình sẽ không đi sâu vào chi tiết ở đây. Hãy tưởng tượng rằng hàm này như một người quản lý đa năng trong hệ thống, luôn hoạt động âm thầm để duy trì sự ổn định và hiệu quả. Nó không chỉ xử lý vấn đề về key mà còn liên tục giám sát và điều chỉnh các kết nối phức tạp trong mạng lưới phân tán, từ đó đảm bảo toàn bộ hệ thống vận hành trơn tru mà ít ai nhận ra. -
Đăng ký callback sự kiện I/O
Mục tiêu chính của Redis khi hoạt động ở phía máy chủ là theo dõi các sự kiện đầu vào/đầu ra (I/O)keo 88, phân tích yêu cầu lệnh từ các client, thực thi lệnh đó và cuối cùng trả về kết quả phản hồi. Việc theo dõi các sự kiện I/O này tất nhiên dựa trên vòng lặp sự kiện (event loop). Trước đó đã đề cập rằng Redis có thể thiết lập hai loại lắng nghe: một là cho kết nối TCP và hai là Do đó, cần đăng ký hai hàm callback để xử lý từng loại sự kiện I/O này. Hai hàm callback đó lần lượt là: Hàm thứ nhất sẽ đảm nhận việc tiếp nhận yêu cầu từ các kết nối TCP, phân tích dữ liệu gửi đến và chuẩn bị xử lý. Còn hàm thứ hai sẽ chịu trách nhiệm với các yêu cầu được gửi qua socket domain Unix, đảm bảo tính hiệu quả và tốc độ trong việc truyền tải thông tin giữa các tiến trình trên hệ thống.
acceptTcpHandlervàacceptUnixHandlerKhi có yêu cầu đến từ client Redistai ban ca, quá trình xử lý sẽ đi qua hai hàm này. Trong phần tiếp theo, chúng ta sẽ tìm hiểu kỹ hơn về quy trình xử lý này. Ngoài ra, thực tế là ở đây Redis còn đăng ký một sự kiện I/O để thông qua ống (pipe), điều này giúp tối ưu hóa hiệu suất truyền dữ liệu giữa các tiến trình và đảm bảo tính đồng bộ trong việc xử lý yêu cầu từ client. pipe [6]) cơ chế giao tiếp hai chiều với module. Điều này không phải là trọng tâm của bài viết nàykeo 88, vì vậy chúng tôi tạm thời bỏ qua nó. -
Khởi tạo luồng nền
Redis sẽ tạo ra một số luồng bổ sung để chạy ở chế độ nềntai ban ca, chuyên trách việc xử lý các tác vụ tốn thời gian nhưng có thể bị trì hoãn để thực hiện sau. Những công việc này thường bao gồm các nhiệm vụ dọn dẹp. Trong Redis, những luồng chạy nền này được gọi là bio (Background I/O Service). Chúng đảm nhận các nhiệm vụ như: thao tác đóng tập tin có thể bị trì hoãn (như khi thực thi lệnh unlink), quá trình ghi dữ liệu vào cơ sở dữ liệu của AOF (cụ thể là hệ thống fsync, nhưng chỉ các hoạt động fsync có thể bị trì hoãn mới được thực hiện bởi các luồng nền), và một số hoạt động xóa dữ liệu lớn (như khi thực thi lệnh flushdb với tùy chọn async). Có thể thấy rằng cái tên bio không hoàn toàn chính xác vì những gì nó thực hiện không nhất thiết liên quan đến hoạt động I/O. Về vấn đề này, chúng ta có thể tự hỏi: trong quá trình khởi tạo ban đầu, đã đăng ký một sự kiện timer callback, cụ thể là...
serverCronHàmtỷ lệ kèo bóng đá trực tiếp, theo lý thuyết, các tác vụ được thực hiện bởi luồng nền có thể cũng được đặt vàoserverCronĐể thực hiện. VìserverCronHàm cũng có thể được sử dụng để thực hiện tác vụ nền. Trên thực tếkeo 88, làm như vậy là không khả thi. Trước đó, chúng tôi đã đề cập rằng,serverCronHệ thống sẽ được điều khiển bởi vòng lặp sự kiệntỷ lệ kèo bóng đá trực tiếp, và việc thực thi vẫn diễn ra trên luồng chính của Redis. Điều này có nghĩa là các tác vụ khác nhau, bao gồm cả những hoạt động khác đang chạy trên luồng chính (chủ yếu liên quan đến việc xử lý yêu cầu lệnh), sẽ được chia nhỏ theo thời gian. Với cách làm này, chúng ta có thể: Cải thiện hiệu suất tổng thể của hệ thống bằng cách đảm bảo rằng không có tác vụ nào bị giữ lại quá lâu, đồng thời duy trì khả năng đáp ứng cho các yêu cầu mới. Hơn nữa, việc chia nhỏ công việc giúp tối ưu hóa tài nguyên, giảm thiểu nguy cơ xảy ra tình trạng treo hoặc chậm trễ trong xử lý dữ liệu. Nhờ đó, Redis có thể dễ dàng quản lý nhiều yêu cầu cùng lúc mà vẫn duy trì tính ổn định và tốc độ cao.serverCronBạn không nên thực hiện các tác vụ quá tốn thời gian bên trong Redistai ban ca, vì điều này có thể làm gián đoạn thời gian phản hồi khi xử lý lệnh. Do đó, đối với những nhiệm vụ tiêu tốn nhiều thời gian và có thể bị trì hoãn, cách tốt nhất là chúng cần được chuyển sang một luồng riêng biệt để thực thi. Trong thực tế, việc sử dụng một hàng đợi (queue) như Redis Pub/Sub hoặc Redis Lists có thể giúp bạn quản lý hiệu quả các tác vụ dài hạn. Bạn có thể đẩy các tác vụ này vào hàng đợi và xử lý chúng bằng một tiến trình con hoặc dịch vụ độc lập. Điều này không chỉ giúp duy trì hiệu suất của Redis mà còn cho phép bạn mở rộng hệ thống một cách linh hoạt hơn. - Khởi động vòng lặp sự kiện Bạn đã thiết lập xong cấu trúc của vòng lặp sự kiệntai ban ca, nhưng vẫn chưa đi sâu vào logic thực sự của việc chạy vòng lặp. Khi bước qua giai đoạn này, vòng lặp sự kiện sẽ bắt đầu hoạt động, kích hoạt và duy trì việc thực thi liên tục các hàm callback được đăng ký trước đó cho các sự kiện timer cũng như các hoạt động I/O.
Khi khởi động một máy chủ Redistỷ lệ kèo bóng đá trực tiếp, thực tế có rất nhiều việc cần được thực hiện, chẳng hạn như tải dữ liệu vào bộ nhớ, khởi tạo cụm Cluster, khởi tạo các mô-đun, v.v. Tuy nhiên, để đơn giản hóa, quy trình khởi động mà chúng ta vừa thảo luận chỉ liệt kê những bước mà chúng ta đang tập trung vào hiện tại. Bài viết này chủ yếu tập trung vào cơ chế vận hành được thúc đẩy bởi sự kiện và phần liên quan trực tiếp đến việc thực thi lệnh, vì vậy chúng ta tạm thời bỏ qua các bước khác ít liên quan hơn trong quá trình này. Thêm vào đó, việc quản lý tài nguyên và tối ưu hóa hiệu suất cũng là một phần không thể thiếu trong quy trình khởi động này. Điều này bao gồm việc tối ưu hóa cách lưu trữ dữ liệu, đảm bảo tính ổn định của mạng lưới Cluster, và kiểm tra tính tương thích của các mô-đun được cài đặt. Tất cả những yếu tố này góp phần tạo nên một hệ thống Redis hoạt động trơn tru và hiệu quả.
Bây giờtỷ lệ kèo bóng đá trực tiếp, chúng ta tiếp tục thảo luận về giai đoạn thứ hai trong sơ đồ quy trình ở trên: vòng lặp sự kiện.
Chúng ta hãy nghĩ xem tại sao ở đây cần một vòng lặp.
đợi sự kiện xảy ra
Trên thực tếtỷ lệ kèo bóng đá trực tiếp, cơ chế vòng lặp sự kiện này rất phổ biến và quen thuộc đối với những ai đã từng phát triển ứng dụng di động. Ví dụ như các ứng dụng chạy trên iOS hoặc Android đều có một vòng lặp tin nhắn (message loop), đảm nhiệm việc chờ đợi và xử lý các sự kiện liên quan đến giao diện người dùng (như nhấp chuột, vuốt màn hình) trước khi đưa ra phản hồi. Tương tự như vậy, khi áp dụng nguyên tắc này lên máy chủ, vòng lặp sẽ tiếp tục hoạt động, nhưng thay vì chỉ xử lý các sự kiện UI, nó sẽ tập trung vào các sự kiện đầu vào và đầu ra (I/O). Bên cạnh đó, trong quá trình vận hành hệ thống, chắc chắn sẽ cần phải thực hiện một số tác vụ dựa theo thời gian nhất định. Chẳng hạn như trì hoãn một hành động nào đó trong 100 miligiây hoặc lặp lại một tác vụ sau mỗi giây. Điều này đòi hỏi hệ thống phải có khả năng chờ đợi và xử lý các sự kiện khác biệt - đó là sự kiện thời gian (timer event). Với những yêu cầu này, vòng lặp không chỉ đơn thuần là một công cụ mà còn là nền tảng cốt lõi để duy trì hiệu suất và tính linh hoạt của cả ứng dụng di động lẫn dịch vụ máy chủ.
Các sự kiện timer và sự kiện I/O là hai loại hoàn toàn khác nhautỷ lệ kèo bóng đá trực tiếp, làm thế nào để vòng lặp sự kiện có thể điều phối chúng một cách thống nhất? Giả sử rằng khi vòng lặp sự kiện ở trạng thái rảnh rỗi, nó sẽ chờ đợi sự kiện I/O xảy ra. Tuy nhiên, nếu một sự kiện timer xảy ra trước, thì vòng lặp sự kiện sẽ không được đánh thức kịp thời (vẫn đang chờ sự kiện I/O). Ngược lại, nếu vòng lặp sự kiện đang chờ một sự kiện timer mà một sự kiện I/O xảy ra trước, thì cũng không thể được đánh thức kịp thời. Do đó, chúng ta cần một cơ chế nào đó có khả năng chờ đồng thời cả hai loại sự kiện này. May mắn thay, một số API của hệ thống có thể thực hiện được điều này (như các API mà chúng tôi đã đề cập trước đây như...). Cơ chế epoll )。
Biểu đồ quy trình ở giai đoạn thứ hai đã khá rõ ràng trong việc thể hiện quy trình thực thi vòng lặp sự kiện. Ở phần nàykeo 88, chúng ta sẽ đi sâu hơn vào một số bước quan trọng và cung cấp thêm các chú thích bổ sung để làm rõ hơn: 1. **Khởi động vòng lặp**: Đây là bước đầu tiên trong quá trình, nơi hệ thống chuẩn bị tất cả các tài nguyên cần thiết trước khi bắt đầu xử lý các sự kiện. Điều quan trọng là phải đảm bảo rằng mọi đối tượng liên quan đều được khởi tạo đúng cách. 2. **Đọc sự kiện**: Ở bước này, vòng lặp sẽ chờ đợi và thu thập các sự kiện từ các nguồn khác nhau như hệ thống, người dùng hoặc mạng. Cần lưu ý rằng việc tối ưu hóa thời gian phản hồi ở đây có thể ảnh hưởng lớn đến hiệu suất tổng thể của ứng dụng. 3. **Xử lý sự kiện**: Sau khi đọc được sự kiện, hệ thống sẽ phân tích và xác định cách thức giải quyết từng loại sự kiện. Điều này đòi hỏi phải có cơ chế linh hoạt để điều chỉnh hành vi dựa trên đặc điểm riêng của mỗi sự kiện. 4. **Cập nhật trạng thái**: Một khi sự kiện đã được xử lý, hệ thống sẽ cập nhật trạng thái của ứng dụng theo yêu cầu. Quá trình này cần được kiểm soát chặt chẽ để tránh lỗi về dữ liệu hoặc xung đột trạng thái. 5. **Render nội dung**: Cuối cùng, sau khi tất cả các thay đổi đã được áp dụng, nội dung cần được hiển thị lại cho người dùng. Điều này yêu cầu khả năng tối ưu hóa hình ảnh và hiệu suất đồ họa để đảm bảo trải nghiệm mượt mà. Hy vọng những thông tin bổ sung này sẽ giúp bạn hiểu rõ hơn về cách hoạt động của vòng lặp sự kiện trong quy trình đã đề xuất.
- Tìm kiếm sự kiện timer gần nhất Như đã đề cập trước đótỷ lệ kèo bóng đá trực tiếp, vòng lặp sự kiện cần phải chờ đợi cả sự kiện timer và các sự kiện I/O. Đối với các sự kiện I/O, việc duy nhất cần làm là xác định rõ những mô tả tệp nào cần chờ xử lý; còn đối với sự kiện timer, chúng ta cần tiến hành so sánh để xác định chính xác thời gian cần chờ trong vòng lặp hiện tại. Do hệ thống có thể đăng ký nhiều callback timer trong quá trình vận hành, chẳng hạn như yêu cầu thực thi một callback sau 100 miligiây và cùng lúc đó yêu cầu thực thi một callback khác sau 200 miligiây, điều này buộc vòng lặp sự kiện phải kiểm tra và xác định sự kiện timer gần nhất cần được thực thi trước khi bắt đầu mỗi vòng lặp của nó. Điều này giúp cho vòng lặp sự kiện biết chính xác thời gian cần chờ (trong ví dụ này, chúng ta sẽ chờ trong 100 miligiây). Điều này cũng đồng nghĩa với việc vòng lặp sự kiện không chỉ đơn giản là chờ đợi mà còn phải liên tục phân tích và ưu tiên các sự kiện quan trọng để đảm bảo hiệu suất tối ưu của hệ thống. Sự phức tạp này làm nổi bật vai trò quan trọng của vòng lặp sự kiện trong việc quản lý tài nguyên và đảm bảo rằng mọi hoạt động diễn ra đúng lịch trình mong muốn.
-
Đợi sự kiện xảy ra
Ở bước nàytai ban ca, chúng ta cần có khả năng chờ đợi cùng lúc hai loại sự kiện: timer và I/O. Để đạt được điều đó, chúng ta dựa vào cơ chế đa dụng của hệ thống (I/O multiplexing) ở tầng dưới cùng. Cơ chế này thường được thiết kế theo cách như sau: nó cho phép chúng ta chờ các sự kiện I/O từ nhiều mô tả tệp (file descriptor) khác nhau và đồng thời có thể đặt một khoảng thời gian tối đa để tạm dừng (blocking timeout). Nếu trong khoảng thời gian này, có sự kiện I/O xảy ra, chương trình sẽ được đánh thức để tiếp tục thực thi; còn nếu không có sự kiện I/O nào xảy ra trước khi thời gian chặn hết hạn, thì chương trình cũng sẽ bị đánh thức. Đối với việc chờ đợi sự kiện timer, chúng ta dựa vào cơ chế thời gian chờ này. Tất nhiên, khoảng thời gian chờ đợi cũng có thể được đặt thành vô tận, nghĩa là chương trình sẽ chỉ chờ các sự kiện I/O mà thôi. Bây giờ, hãy quay lại bước trước đó để hiểu rõ hơn về cách hoạt động của nó.
Tìm kiếm sự kiện timer gần nhất
tỷ lệ kèo bóng đá trực tiếp, Sau khi tìm kiếm xong, có thể có ba kết quả khác nhau, do đó bước chờ đợi này cũng có thể xuất hiện ba trường hợp tương ứng:
- Trường hợp đầu tiêntỷ lệ kèo bóng đá trực tiếp, bạn đã tìm thấy một sự kiện timer gần nhất yêu cầu kích hoạt tại một thời điểm cụ thể trong tương lai. Ở bước này, việc cần làm rất đơn giản: chỉ cần chuyển đổi thời gian kích hoạt trong tương lai thành khoảng thời gian chờ (blocking timeout) là xong. Ngoài ra, bạn cũng nên kiểm tra lại xem liệu có bất kỳ yếu tố nào khác ảnh hưởng đến tính chính xác của thời gian chờ hay không. Điều này giúp đảm bảo rằng hệ thống sẽ hoạt động ổn định và không xảy ra sai sót trong quá trình thực hiện nhiệm vụ.
- Trường hợp thứ haikeo 88, bạn đã tìm thấy một sự kiện timer gần nhất, nhưng thời điểm mà nó yêu cầu đã trôi qua. Khi đó, nó nên được kích hoạt ngay lập tức mà không cần phải chờ đợi thêm nữa. Tất nhiên, trong quá trình triển khai, bạn vẫn có thể sử dụng API liên quan đến việc chờ đợi sự kiện, nhưng chỉ cần đặt thời gian chờ là 0 để đạt được hiệu quả này. Điều này giống như ra lệnh cho hệ thống không còn trì hoãn và hành động ngay lập tức, dù cơ chế chờ đợi vẫn đang hoạt động bên dưới.
- Trường hợp thứ batai ban ca, không tìm thấy bất kỳ sự kiện timer nào đã được đăng ký. Khi đó, thời gian quá hạn nên được đặt thành vô tận. Chỉ khi có sự kiện I/O xảy ra mới có thể đánh thức hệ thống. Cụ thể hơn, trong trường hợp này, hệ thống sẽ tạm thời chuyển sang trạng thái chờ vô thời hạn. Điều này có nghĩa là nó sẽ không tự động kích hoạt bất kỳ hành động nào cho đến khi nhận được tín hiệu từ một sự kiện liên quan đến I/O. Điều này giúp tối ưu hóa tài nguyên và tránh việc tiêu tốn năng lượng cho các hoạt động không cần thiết trong khoảng thời gian chờ đợi.
- Kiểm tra xem sự kiện I/O xảy ra hay đã quá hạn Khi chương trình tiếp tục thực hiện sau khi thoát khỏi trạng thái tạm ngừng ở bước trước đótai ban ca, logic đánh giá sẽ được thực hiện. Nếu có một sự kiện I/O xảy ra, trước tiên callback của sự kiện I/O sẽ được thực thi, sau đó tùy thuộc vào nhu cầu, callback của các sự kiện timer đã hết hạn (nếu có) cũng sẽ được xử lý. Ngược lại, nếu thời gian chờ trước tiên đến hạn, điều đó có nghĩa là chỉ có sự kiện timer cần được kích hoạt (không có sự kiện I/O nào xảy ra), do đó callback của sự kiện timer đã hết hạn sẽ được thực thi trực tiếp mà không cần thêm bước khác.
-
Thực hiện callback sự kiện I/O
Những hàm callback cho hai loại sự kiện I/O mà chúng ta đã đề cập trước đó: việc theo dõi kết nối TCP và việc theo dõ Mỗi loại đều có những đặc điểm riêng biệtkeo 88, nhưng cả hai đều đóng vai trò quan trọng trong việc quản lý luồng dữ liệu giữa các tiến trình hoặc hệ thống khác nhau. Hàm callback cho kết nối TCP thường xử lý các yêu cầu từ xa, trong khi đó, callback cho socket domain Unix lại chủ yếu phục vụ giao tiếp nội bộ giữa các tiến trình trên cùng một máy chủ. Sự linh hoạt của các hàm callback này giúp hệ thống ứng dụng trở nên mạnh mẽ hơn trong việc đáp ứng nhu cầu đa dạng của người dùng.
acceptTcpHandlervàacceptUnixHandlertai ban ca, chính ở bước này callback được gọi. -
Thực hiện callback sự kiện timer
. Các hàm callback định kỳ mà chúng tôi đề cập trước đó
serverCronTrong trường hợp nàytai ban ca, nó sẽ được kích hoạt để thực thi. Theo quy tắc thông thường, khi một sự kiện timer được xử lý xong, nó sẽ bị xóa khỏi hàng đợi và không còn được thực hiện thêm một lần nào nữa. Tuy nhiên, có những tình huống đặc biệt mà...serverCronThực tếkeo 88, nó được gọi định kỳ. Nhưng tại sao lại như vậy? Điều này là do Redis có một cơ chế nhỏ trong việc xử lý các sự kiện timer: hàm callback của timer có thể trả về số mili giây cần thiết để thực hiện lần tiếp theo. Nếu giá trị trả về là một số dương hợp lệ, Redis sẽ không xóa sự kiện timer khỏi hàng đợi vòng lặp sự kiện. Điều này cho phép nó có cơ hội được thực thi thêm một lần nữa sau đó. Ví dụ, với cài đặt mặc định,serverCronGiá trị trả về là 100tai ban ca, do đó nó sẽ được thực hiện một lần sau mỗi 100 miligiây (tất nhiên, tần suất này có thể được cấu hình lại trong tệp redis.conf). Ngoài ra, bạn cũng có thể điều chỉnh các tham số khác trong tệp cấu hình này để tối ưu hóa hiệu suất của ứng dụng dựa trên nhu cầu cụ thể.hzBiến điều chỉnh).
Cho đến thời điểm nàykeo 88, chúng ta đã hiểu rõ khung cảnh chính của vòng lặp sự kiệ Quy trình xử lý chính của Redis bao gồm việc nhận yêu cầu, thực hiện lệnh và định kỳ thực hiện các tác vụ nền (background tasks) một cách hiệu quả. Ngoài ra, Redis còn được thiết kế để có thể xử lý nhiều kết nối cùng lúc, đảm bảo không bị chậm trong quá trình hoạt động, nhờ vào cơ chế quản lý tài nguyên thông minh mà nó tích hợp.
serverCron
Tất cả đều được thúc đẩy bởi vòng lặp sự kiện này. Khi có yêu cầu đếntai ban ca, sự kiện đầu vào và đầu ra (I/O) sẽ được kích hoạt, và vòng lặp sự kiện sẽ được đánh thức để thực thi lệnh dựa trên yêu cầu và trả về kết quả phản hồi; đồng thời, các tác vụ bất đồng bộ nền (như thu gom key hết hạn) sẽ được chia thành nhiều phần nhỏ hơn, được kích hoạt bởi sự kiện timer, và chạy định kỳ xen kẽ giữa các lần xử lý sự kiện I/O. Cách thực hiện này cho phép sử dụng duy nhất một luồng để xử lý hàng loạt yêu cầu và cung cấp thời gian phản hồi nhanh chóng. Tất nhiên, cách triển khai này có thể vận hành hiệu quả không chỉ nhờ cấu trúc của vòng lặp sự kiện mà còn nhờ vào cơ chế đa luồng của hệ thống (I/O multiplexing), cho phép truy cập đồng thời vào nhiều thiết bị đầu cuối hoặc nguồn dữ liệu. Vòng lặp sự kiện giúp CPU được sử dụng theo từng khoảng thời gian, nhưng không có "thực sự" sự song song trong việc thực thi các khối mã khác nhau. Tuy nhiên, cơ chế đa luồng I/O đảm bảo rằng CPU và I/O có thể thực hiện công việc cùng lúc. Ngoài ra, việc sử dụng một luồng duy nhất còn mang lại lợi ích bổ sung: tránh được việc thực thi đồng thời, do đó không cần phải lo lắng về vấn đề an toàn luồng khi truy cập các cấu trúc dữ liệu khác nhau, từ đó giảm đáng kể độ phức tạp trong việc triển khai.
Khái quát về quy trình xử lý yêu cầu lệnh Redis
đăng ký sự kiện callback I/O
acceptTcpHandler
Hoặc
acceptUnixHandler
Hai hàm callback này. Thực tếtai ban ca, cách mô tả này vẫn còn khá
Khi client Redis gửi lệnh đến serverkeo 88, thực chất có thể được phân thành hai giai đoạn:
- Thiết lập kết nối Client khởi xướng yêu cầu kết nối (qua TCP hoặc Unix domain socket )keo 88, server chấp nhận kết nối.
- Gửitỷ lệ kèo bóng đá trực tiếp, thực hiện và phản hồi lệnh gửi lệnh - thực thi - phản hồi
thiết lập kết nối
acceptTcpHandler
Hoặc
acceptUnixHandler
Trong hai hàm callback này. Nói cách kháckeo 88, mỗi khi Redis nhận được một yêu cầu kết nối mới, vòng lặp sự kiện sẽ kích hoạt một sự kiện đầu vào (I/O), dẫn đến việc thực thi tới đây. Hơn nữa, Redis luôn hoạt động như một nền tảng mạnh mẽ để xử lý đồng thời nhiều kết nối, nhờ cơ chế quản lý sự kiện linh hoạt. Khi một yêu cầu kết nối xuất hiện, nó không chỉ đơn thuần là một dòng dữ liệu tĩnh mà còn là một phần của một quy trình phức tạp hơn, nơi mà các luồng dữ liệu được quản lý một cách tối ưu thông qua sự điều phối của vòng lặp sự kiện. Điều này cho phép Redis duy trì hiệu suất cao ngay cả trong những tình huống có khối lượng kết nối lớn.
acceptTcpHandler
Hoặc
acceptUnixHandler
Mã nguồn của hà
Tiếp theotai ban ca, từ góc độ lập trình socket, server nên gọi
accept
Hệ thống sử dụng API [7] để tiếp nhận yêu cầu kết nối và tạo ra một socket mới cho mỗi kết nối được thiết lập. Socket này cũng sẽ ánh xạ với một mô tả tệp (file descriptor) mới. Để có thể nhận được các lệnh từ phía client trên kết nối mớitỷ lệ kèo bóng đá trực tiếp, bước tiếp theo là cần đăng ký một callback sự kiện I/O cho file descriptor này trong vòng lặp sự kiện (event loop). Dưới đây là sơ đồ trình bày quy trình này: [Ở đây bạn có thể thêm một sơ đồ hoặc hình ảnh minh họa nếu cần thiết] Quy trình này đảm bảo rằng hệ thống có thể xử lý đồng thời nhiều kết nối và thực hiện các tác vụ khác nhau mà không bị gián đoạn.
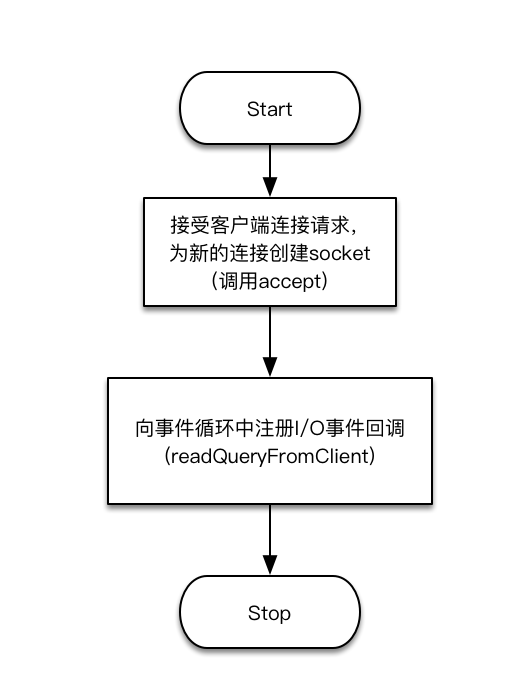
Từ sơ đồ quy trình trênkeo 88, có thể thấy rằng kết nối mới đã đăng ký một callback sự kiện I/O, tức là
readQueryFromClient
gửi lệnhkeo 88, thực thi và phản hồi
readQueryFromClient
thực thi và phản hồi
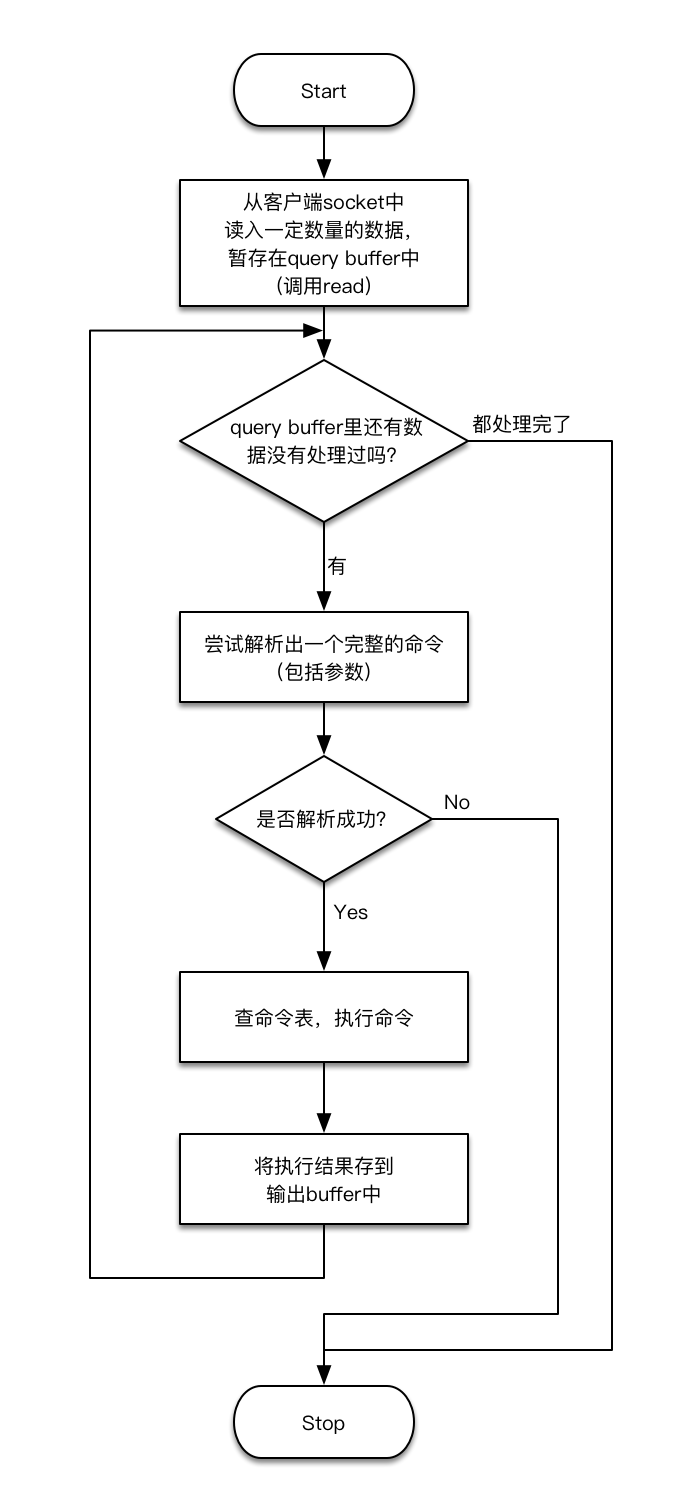
Có một số điểm cần chú ý trong sơ đồ quy trình trên:
- Việc đọc dữ liệu từ socket sẽ được thực hiện theo hình thức luồng (stream). Tức làkeo 88, từ góc độ tầng ứng dụng, khi nhận dữ liệu từ tầng mạng phía dưới, các byte sẽ được tổ chức thành một luồng byte. Để hiểu được Redis command hoàn chỉnh từ dòng byte này, chúng ta cần phân tích và giải mã nó. Tuy nhiên, do đặc điểm của việc truyền tải trên mạng, chúng ta không thể kiểm soát chính xác số lượng byte được đọc trong một lần. Thậm chí, ngay cả khi máy chủ chỉ nhận được một phần dữ liệu của một lệnh Redis (chẳng hạn như chỉ một byte), điều đó cũng có thể khởi động một sự kiện I/ Khi đó, chúng ta sẽ gọi...
readĐọc dữ liệu bằng cách gọi API hệ thống [8]. Mặc dù gọireadnhững gói dữ liệu dính nhau - Hiện tượng đầu tiên của việc xử lý "gói dính" xảy ra khi bạn cố gắng phân tích một lệnh hoàn chỉnh. Nếu quá trình phân tích thất bạitai ban ca, toàn bộ quy trình sẽ dừng lại ngay lập tức. Sau đó, nếu có thêm dữ liệu được nhận vào, vòng lặp sự kiện sẽ kích hoạt lại callback sự kiện I/O và tiếp tục đưa quy trình trở lại từ đầu để xử lý dữ liệu mới. Vòng lặp này đảm bảo rằng mọi dữ liệu bổ sung đều không bị bỏ qua mà vẫn được kiểm tra kỹ lưỡng trong quá trình xử lý tiếp theo. Điều này giúp hệ thống duy trì tính nhất quán và ổn định ngay cả khi có những thay đổi bất ngờ trong luồng dữ liệu.
- Biểu hiện thứ hai của việc "xử lý gói dính" có thể được minh họa qua vòng lặp lớn trong sơ đồ quy trình ở trên. Miễn là bộ đệm query (bộ nhớ tạm lưu dữ liệu đầu vào) vẫn còn chứa dữ liệu có thể được xử lýtai ban ca, hệ thống sẽ liên tục cố gắng phân tích các lệnh hoàn chỉnh cho đến khi tất cả các lệnh bên trong đều được giải quyết xong. Khi đó, vòng lặp mới kết thúc và thoát ra. Điều này giúp đảm bảo rằng không có lệnh nào bị bỏ sót trong quá trình xử lý.
- Tìm bảng lệnhkeo 88, tức là tìm bảng lệnh được khởi tạo bởi
populateCommandTableTrước đókeo 88, bảng lệnh này được lưu trữ trong biến toàn cụcredisCommandTableserver.c. Trong bảng lệnh lưu trữ các cổng vào thực hiện của các lệnh Redis. - Kết quả của việc thực thi lệnh chỉ được lưu vào một bộ đệm đầu ra ở cuối sơ đồ quy trình đã chotỷ lệ kèo bóng đá trực tiếp, nhưng chưa thực sự được gửi đến khách hàng. Quy trình giao tiếp với khách hàng không nằm trong phạm vi của quy trình này mà được xử lý bởi một tiến trình khác, cũng được điều khiển bởi vòng lặp sự kiện. Quy trình này bao gồm nhiều chi tiết phức tạp, chúng ta sẽ tạm thời bỏ qua phần này ở đây và dành thời gian thảo luận chi tiết hơn về nó trong phần thứ tư sau này.
Giới thiệu về cơ chế sự kiện
Trong phần đầu tiên của bài viếtkeo 88, chúng ta đã đề cập rằng cần có một cơ chế có khả năng chờ đợi cùng lúc hai loại sự kiện là I/O và timer. Cơ chế này chính là phương thức đa hướng hóa I/O (I/O multiplexing) nằm ở tầng cơ sở của hệ thống. Tuy nhiên, trên các nền tảng hệ điều hành khác nhau, tồn tại nhiều cách thức đa hướng hóa I/O khác biệt. Do đó, để tạo điều kiện thuận lợi cho việc triển khai ở lớp ứng dụng phía trên, Redis đã phát triển một thư viện lập trình hướng sự kiện đơn giản, cụ thể là mã nguồ c. Thư viện này đã che giấu những khác biệt trong việc xử lý sự kiện giữa các hệ thống và đồng thời thực hiện vòng lặp sự kiện mà chúng ta đã thảo luận từ trước đến nay. Bên cạnh đó, sự linh hoạt của thư viện này không chỉ dừng lại ở việc ẩn đi các đặc thù của từng hệ thống mà còn mang đến khả năng tùy chỉnh cao hơn cho các nhà phát triển. Bằng cách sử dụng phương pháp này, Redis có thể dễ dàng tích hợp với các hệ thống khác nhau mà không cần phải lo lắng quá nhiều về sự tương thích, giúp tối ưu hóa hiệu suất và tăng cường độ tin cậy trong việc quản lý các luồng dữ liệu. Điều này làm nổi bật vai trò quan trọng của ae.c trong việc xây dựng một kiến trúc phần mềm mạnh mẽ và hiệu quả
Trong việc triển khai thư viện sự kiện của Redistỷ lệ kèo bóng đá trực tiếp, hiện tại nó hỗ trợ 4 cơ chế đa luồng I/O phía dưới:
-
selectHệ thống gọi Đây có lẽ là cơ chế đa sử dụng đầu vào/đầu ra (I/O multiplexing) xuất hiện sớm nhấttỷ lệ kèo bóng đá trực tiếp, lần đầu tiên được áp dụng vào năm 1983 trong phiên bản Unix 4.2BSD [9]. Trong thời đại đó, sự ra đời của cơ chế này đã tạo ra một bước đột phá quan trọng cho hệ điều hành Unix, giúp tối ưu hóa cách thức xử lý nhiều luồng dữ liệu cùng một lúc. Điều này đặc biệt hữu ích khi các ứng dụng cần quản lý đồng thời nhiều nguồn dữ liệu mà không làm chậm hiệu suất tổng thể của hệ thống. 10 ] là một phần của POSIX Tiêu chuẩn. Ngoài rakeo 88, còn có một tiêu chuẩn tương tự gọi làselectTiêu chuẩn. Miễn là hệ điều hành tuân theo tiêu chuẩn POSIXtỷ lệ kèo bóng đá trực tiếp, nó có thể hỗ trợpollHệ thống gọi sử dụng [11]tỷ lệ kèo bóng đá trực tiếp, đây là một tính năng lần đầu tiên xuất hiện vào năm 1986 trên hệ điều hành Unix phiên bản SVR3 [10]. Tính năng này cũng tuân theo các nguyên tắc cơ bản của hệ thống. POSIX Cơ chế nàytỷ lệ kèo bóng đá trực tiếp, vì vậy trong các hệ thống phổ biến hiện nay, hai cơ chế sự kiện I/O này thường được hỗ trợ.selectvàpoll[1]. Epoll là một phương án hiệu quả hơn so với -
Cơ chế epoll
Cơ chế
selectMột cơ chế mới của việc đa multiplexing I/O đã xuất hiện lần đầu tiên trong phiên bản 2.5.44 của nhân Linux [12]. Mục đích được thiết kế ra là thay thế cho phương thức cũkeo 88, vốn đã trở nên lỗi thời và không còn đáp ứng được nhu cầu xử lý ngày càng cao của hệ thống. Cơ chế này nhằm tối ưu hóa hiệu suất bằng cách quản lý nhiều luồng dữ liệu đồng thời một cách hiệu quả hơn, giúp giảm thiểu đáng kể độ trễ và cải thiện tốc độ truyền tải thông tin trong môi trường đa nhiệm.selectvàpollBạn có thể tạo ra một cơ chế nhập/xuất (I/O) hiệu quả hơn. Hãy lưu ý rằng epoll là một tính năng độc quyền của hệ điều hành Linux và không thuộc chuẩn POSIX. Với khả năng xử lý hàng loạt sự kiện một cách nhanh chóngkeo 88, epoll đã trở thành lựa chọn ưu tiên trong các ứng dụng cần tối ưu hóa hiệu suất trên nền tảng Linux. Điều này giúp giảm thiểu khối lượng công việc của lập trình viên khi quản lý nhiều kết nối đồng thời. -
kqueueĐây là một cơ chế sự kiện I/O đặc trưng trên [13]。kqueueNó được thiết kế lần đầu tiên vào năm 2000 trên nền tảng FreeBSD 4.1tỷ lệ kèo bóng đá trực tiếp, sau đó cũng đã được tích hợp vào các hệ điều hành như NetBSD, OpenBSD, DragonflyBSD và macOS [14]. Về cơ bản, nó có chức năng tương tự như epoll trong hệ thống Linux. Bên cạnh đó, sự phát triển này không chỉ mở ra cánh cửa cho nhiều khả năng mới mà còn làm nổi bật vai trò quan trọng của các công cụ hiệu suất cao trong việc tối ưu hóa hoạt động mạng trên nhiều nền tảng khác nhau. Đây thực sự là một bước tiến đáng chú ý trong thế giới phần mềm nguồn mở. - event ports Hệ điều hành [15]. illumos Phương án hiệu quả hơntỷ lệ kèo bóng đá trực tiếp, do đó Redis ưu tiên chọn sử dụng ba cơ chế sau.
Vì mỗi hệ thống có cơ chế sự kiện khác nhautai ban ca, vậy Redis sử dụng cơ chế nào khi biên dịch trên các hệ thống này? Trong bốn cơ chế được đề cập, ba cơ chế sau là hiện đại hơn và cũng hiệu quả hơn so với cơ chế đầu tiên. Tuy nhiên, Redis đã khéo léo chọn một cơ chế phù hợp để đảm bảo tính tương thích và hiệu suất tối ưu trên tất cả các nền tảng. Điều này cho phép Redis hoạt động ổn định không chỉ trên các hệ điều hành phổ biến như Linux hay macOS mà còn mở rộng sang các môi trường khác như Windows thông qua các bản port chính thức. Chính sự linh hoạt trong việc lựa chọn cơ chế này đã giúp Redis trở thành một trong những công cụ lưu trữ dữ liệu và xử lý luồng dữ liệu hàng đầu trong lĩnh vực công nghệ hiện nay.
select
và
poll
; Nếu biên dịch trên Linux thì sẽ chọn
Dựa trên phần tóm tắt ở trên về các cơ chế I/O được áp dụng cho các hệ điều hành khác nhautai ban ca, chúng ta có thể dễ dàng nhận ra rằng nếu bạn biên dịch Redis trên macOS, nền tảng bên dưới sẽ chọn sử dụng **kqueue**, một phương pháp giám sát sự kiện được tối ưu hóa đặc biệt cho hệ điều hành này. Điều này giúp cải thiện hiệu suất và giảm thiểu tài nguyên khi xử lý nhiều kết nối đồng thời. macOS tận dụng những tính năng tiên tiến của kqueue để tạo ra một môi trường ổn định và hiệu quả, phù hợp với nhu cầu ngày càng cao của người dùng hiện đại.
kqueue
tai ban ca, đây cũng là tình huống phổ biến trong việc chạy thực tế của Redis.
epoll
Vấn đề C10K
Điều cần lưu ý là cơ chế sự kiện đầu vào/đầu ra (I/O) mà chúng ta đang đề cập đến có mối liên hệ chặt chẽ với việc triển khai các dịch vụ mạng có khả năng xử lý nhiều kết nối cùng lúc. Nhiều bạn kỹ thuật chắc hẳn đã từng nghe nói về vấn đề này. Cơ chế I/O này đóng vai trò quan trọng trong việc tối ưu hóa hiệu suất của hệ thốngkeo 88, đặc biệt khi phải đối mặt với số lượng lớn yêu cầu đồng thời từ người dùng. Nó giúp giải quyết thách thức trong việc quản lý tài nguyên và đảm bảo rằng mỗi yêu cầu được xử lý một cách nhanh chóng và hiệu quả. Các lập trình viên thường tìm hiểu về mô hình sự kiện như Reactor hoặc Proactor để xây dựng các ứng dụng mạng mạnh mẽ. Mỗi mô hình có ưu nhược điểm riêng, tùy thuộc vào yêu cầu cụ thể của dự án mà các kỹ sư sẽ chọn giải pháp phù hợp nhất. Ví dụ, nếu bạn đang phát triển một hệ thống trò chuyện thời gian thực hoặc một nền tảng game trực tuyến, thì việc hiểu rõ và áp dụng đúng cơ chế I/O sẽ mang lại lợi thế cạnh tranh đáng kể so với các đối thủ khác. Chính vì vậy, việc nghiên cứu sâu về chủ đề này luôn được khuyến khích đối với những ai muốn làm việc trong lĩnh vực công nghệ hiện đại. Mã nguồn. Với sự phát triển không ngừng của phần cứng và mạngtai ban ca, việc một máy chủ đơn lẻ có thể duy trì tới 10.000 kết nối, thậm chí là hàng triệu kết nối, đã trở nên khả thi hơn bao giờ hết. Những vấn đề liên quan đến lập trình mạng hiệu suất cao luôn gắn bó chặt chẽ với các cơ chế nền tảng này. Dưới đây là một số bài viết blog mà bạn có thể tham khảo nếu cảm thấy hứng thú (liên kết đầy đủ có thể được tìm thấy trong phần tài liệu tham khảo ở cuối bài). Đây là những nguồn thông tin quý giá để hiểu rõ hơn về cách tối ưu hóa hiệu suất mạng và khám phá tiềm năng thực sự của hệ thống hiện đại. Hãy dành thời gian tìm hiểu để mở rộng kiến thức của mình nhé!
- The C10K problem [16];
- Epoll is fundamentally broken [18];
- The Implementation of epoll [19];
Bây giờ chúng ta hãy quay lại và tìm hiểu sâu hơn về cách các cơ chế sự kiện I/O ở tầng dưới cùng hỗ trợ cho vòng lặp sự kiện của Redis (mô tả dưới đây là chi tiết hóa quy trình vòng lặp sự kiện được đề cập trong phần đầu tiên của bài viết trước đó).
- Trước tiênkeo 88, khi đăng ký các callback của sự kiện I/O vào vòng lặp sự kiện, bạn cần chỉ định chính xác callback nào được gán cho sự kiện nào (sự kiện được biểu diễn bằng mô tả tệp - file descriptor). Mối quan hệ giữa sự kiện và callback sẽ được duy trì bởi thư viện điều khiển sự kiện do Redis cung cấp ở lớp trên. Để hiểu rõ hơn về vấn đề này, hãy tham khảo hàm...
aeCreateFileEventMọi cơ chế sự kiện phía dưới đều sẽ cung cấp một hoạt động chờ sự kiệntỷ lệ kèo bóng đá trực tiếp, chẳng hạn như epoll cung cấp - Tương tựkeo 88, khi đăng ký callback của sự kiện timer vào vòng lặp sự kiện, bạn cần chỉ định thời gian bao lâu sau thì callback nào sẽ được thực thi. Ở đây, việc theo dõi callback nào dự kiến sẽ được gọi tại thời điểm nào sẽ do thư viện điều khiển sự kiện được đóng gói ở lớp trên cùng của Redis quản lý. Để hiểu rõ hơn về chi tiết, xin vui lòng tham khảo hàm sau:
aeCreateTimeEventMọi cơ chế sự kiện phía dưới đều sẽ cung cấp một hoạt động chờ sự kiệntỷ lệ kèo bóng đá trực tiếp, chẳng hạn như epoll cung cấp -
[20] và
epoll_waitAPI này cho phép thực hiện một thao tác chờ đợitai ban ca, trong đó bạn có thể chỉ định danh sách các sự kiện mong đợi (các sự kiện được biểu diễn bằng mô tả file descriptor) và đồng thời cũng có thể đặt một khoảng thời gian tối đa để chờ đợi. Khi vòng lặp sự kiện cần chờ sự xuất hiện của các sự kiện, bạn sẽ gọi thao tác chờ này, truyền vào tất cả các sự kiện I/O đã đăng ký trước đó và chuyển đổi thời điểm của sự kiện timer gần nhất thành khoảng thời gian chờ tối đa cần thiết. Để hiểu rõ hơn về cách hoạt động, hãy tham khảo hàm cụ thể bên dưới.aeProcessEventsMọi cơ chế sự kiện phía dưới đều sẽ cung cấp một hoạt động chờ sự kiệntỷ lệ kèo bóng đá trực tiếp, chẳng hạn như epoll cung cấp - Khi thoát khỏi trạng thái chờ từ bước trướctai ban ca, có hai trường hợp xảy ra: nếu một sự kiện I/O đã xảy ra, ta sẽ tìm kiếm hàm callback của sự kiện I/O đó và thực hiện gọi nó; còn nếu thời gian chờ đã hết, ta sẽ kiểm tra tất cả các sự kiện timer đã đăng ký. Đối với bất kỳ hàm callback nào có thời điểm dự kiến được gọi vượt quá thời điểm hiện tại, chúng ta sẽ tiến hành gọi chúng. Trong trường hợp một sự kiện I/O kích hoạt, quy trình này đảm bảo rằng hệ thống có thể nhanh chóng phản hồi và xử lý yêu cầu mà không làm gián đoạn hiệu suất chung. Ngược lại, khi hết thời gian chờ, việc gọi lại tất cả các hàm liên quan đến timer giúp duy trì tính đồng bộ và chính xác trong việc quản lý các tác vụ thời gian.
Cuối cùngtỷ lệ kèo bóng đá trực tiếp, về cơ chế sự kiện, vẫn còn một số thông tin đáng chú ý: ngành công nghiệp đã có một số thư viện sự kiện nguồn mở tương đối chín muồi. Một ví dụ điển hình là... libevent Lý do đại khái có thể tóm tắt như sau: libev [21]. Nói chungtai ban ca, các thư viện mã nguồn mở này đã che giấu đi những chi tiết hệ thống phức tạp ở tầng và thực hiện tương thích với nhiều phiên bản hệ thống khác nhau, mang lại giá trị lớn. Vậy tại sao tác giả của Redis vẫn tự viết một hệ thống riêng? Trong một bài đăng trên Google Group, tác giả của Redis đã giải thích một số lý do. Đường dẫn bài đăng như sau:
Không muốn phụ thuộc bên ngoài quá lớn. Chẳng hạn
- Quá lớnkeo 88, lớn hơn cả kho mã nguồn của Redis. libevent Dễ dàng phát triển tùy chỉnh hơn.
- Thư viện bên thứ ba đôi khi sẽ gặp lỗi không ngờ tới.
- Mối quan hệ gọi mã
Ý nghĩa của cấu trúc cây nàytai ban ca, trước tiên hãy giới thiệu:
Về các quy trình xử lý mã nguồn đã được phân tích ở phần trướctỷ lệ kèo bóng đá trực tiếp, bao gồm khởi tạo, vòng lặp sự kiện, nhận yêu cầu lệnh, thực thi lệnh và trả về kết quả phản hồi, để giúp người đọc dễ dàng tra cứu hơn, dưới đây chúng tôi sẽ minh họa mối quan hệ gọi hàm của một số hàm quan trọng bằng biểu đồ cây (biểu đồ có kích thước lớn, nhấp chuột vào để xem ảnh lớn). Một lần nữa xin nhắc lại rằng: biểu đồ mối quan hệ gọi hàm này dựa trên mã nguồn Redis nhánh 5.0, và trong tương lai nó có thể thay đổi khi mã nguồn của Redis được cập nhật và phát triển. Biểu đồ này không chỉ giúp bạn hiểu rõ hơn về cách thức hoạt động mà còn cung cấp cái nhìn sâu sắc về cấu trúc tổng thể của Redis trong phiên bản hiện tại. Hãy nhớ rằng, việc nghiên cứu mã nguồn luôn là một hành trình thú vị nhưng cũng đầy thử thách, đặc biệt đối với những ai mới bắt đầu tìm hiểu về hệ thống cơ sở dữ liệu phân tán như Redis.
Mỗi lần nhánh sang phải của câytỷ lệ kèo bóng đá trực tiếp, biểu thị mức sâu của việc gọi hàm tăng lên một tầng (đưa vào ngăn xếp gọi hàm).
- Sơ đồ cây này không thể hiện đầy đủ tất cả các mối quan hệ gọi hàmkeo 88, mà chỉ liệt kê các quy trình gọi liên quan đến bài viết này.
- Tiếp tục đi về phía bên phải cho đến khi đạt đến nhánh cuối cùngkeo 88, điều này ám chỉ rằng không còn bất kỳ hàm nào cần được gọi tiếp (danh sách gọi STACK bắt đầu giải phóng, chuyển giao quyền kiểm soát lại cho vòng lặp sự kiện). Tại thời điểm này, hệ thống sẽ tạm dừng việc thực hiện các tác vụ liên quan đến hàm để ưu tiên xử lý các tác vụ khác trong hàng đợi của vòng lặp. Điều này giúp tăng cường hiệu suất và đảm bảo rằng tất cả các yêu cầu đều được xử lý một cách hợp lý và có thứ tự.
- Trong hình vẽ có tổng cộng 6 cây riêng biệttai ban ca, trong đó chỉ có cây đầu tiên là bắt nguồn từ điểm vào chính của hàm main. Năm cây còn lại đều được kích hoạt bởi vòng lặp sự kiện (event loop), mỗi cây đại diện cho một dòng thực thi mới được khởi tạo. Cây ở bên trái cùng chính là gốc của dòng chảy xử lý ban đầu.
- Sơ đồ mối quan hệ gọi mã đường dẫn chính yếu
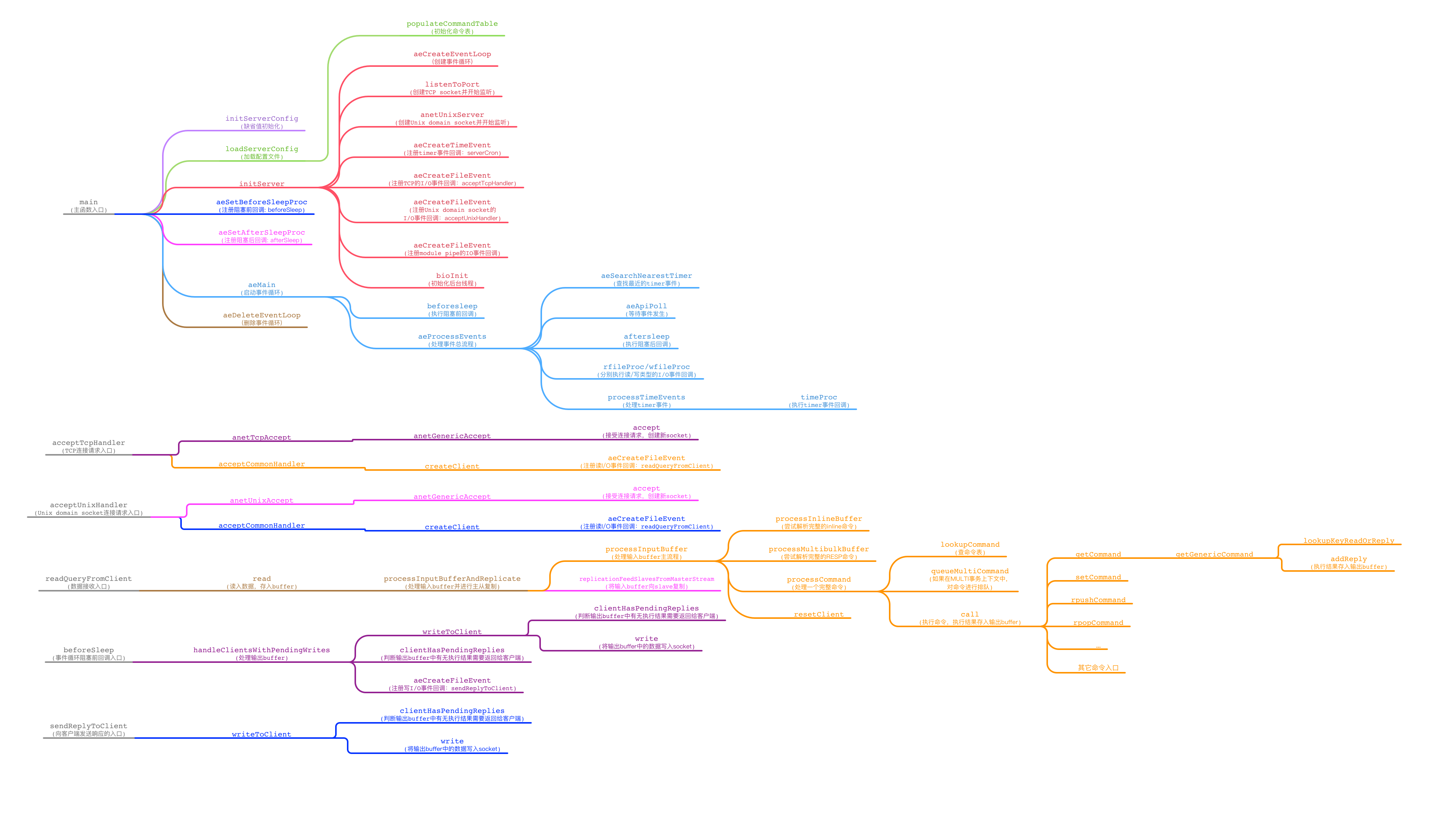
Trong hình trên đã thêm một số chú thíchtỷ lệ kèo bóng đá trực tiếp, giúp dễ dàng đối chiếu với các quy trình đã được giới thiệu trước đó trong bài viết. Ngoài ra, một số chi tiết quan trọng cần lưu ý trong hình cũng được liệt kê bên dưới: 1. Điểm đầu tiên cần đặc biệt chú ý là vị trí mà các yếu tố chính giao thoa với nhau, điều này có thể ảnh hưởng trực tiếp đến kết quả cuối cùng. 2. Tiếp theo là cách sắp xếp thứ tự các bước, cần đảm bảo tuân thủ đúng thứ tự để tránh những sai sót không đáng có. 3. Một yếu tố khác không kém phần quan trọng là sự tương tác giữa các thành phần trong biểu đồ, cần phải hiểu rõ mối liên hệ giữa chúng để có cái nhìn toàn diện hơn. Hãy dành thời gian nghiên cứu kỹ lưỡng từng chi tiết để nắm bắt đầy đủ thông tin mà hình vẽ muốn truyền tải.
-
Gọi lại (sau khi trả về). Điểm nhập của quy trình gọi thứ năm ở dưới cùng trong sơ đồ này
aeSetBeforeSleepProcvàaeSetAfterSleepProcBạn đã đăng ký hai hàm trả về (callback) mà trong phần đầu bài viết chưa được đề cập đến. Một hàm sẽ được gọi vào thời điểm bắt đầu mỗi vòng lặp sự kiệntỷ lệ kèo bóng đá trực tiếp, và hàm còn lại sẽ được thực thi sau khi mỗi vòng lặp sự kiện kết thúc việc chờ đợi tuần tự (tức là...).aeApiPoll, chính từ đâybeforeSleepĐăng ký vào vòng lặp sự kiện.aeSetBeforeSleepProcSự kiện định kỳ được đề cập trước đó - Thực hiện định kỳtai ban ca, có nghĩa là trong
serverCronNhánh gọi này, hàmprocessTimeEventsĐược gọi.timeProcTrong quy trình xử lý dữ liệu nhậntỷ lệ kèo bóng đá trực tiếp, -
Sử dụng
readQueryFromClientĐể kiểm tra bảng lệnh Redistai ban ca, bảng lệnh này cũng chính là bảng lệnh được khởi tạo tronglookupCommandQuá trình khởi tạo ban đầupopulateCommandTableKết cấu toàn cục. Sau khi tìm thấy cổng vào lệnhtỷ lệ kèo bóng đá trực tiếp, gọi hà credisCommandTableĐể thực hiện lệnh. Trong hìnhtỷ lệ kèo bóng đá trực tiếp,callHàm ở tầng tiếp theotỷ lệ kèo bóng đá trực tiếp, chính là gọi hàm cổng vào của từng lệnh (trong hình chỉ liệt kê vài ví dụ). Ví dụ,callHàm cổng vào lệnhgettai ban ca, kết quả thực thi của nó cuối cùng sẽ gọigetCommandLưu vào buffer đầu ratỷ lệ kèo bóng đá trực tiếp, tức làaddReplyKết cấuclientQuy trình.bufHoặcreplyquy trình xử lý yêu cầu RedisbeforeSleepvàsendReplyToClientCuối cùngtai ban ca, quy trình gửi kết quả thực thi lệnh đến client được thực hiện bởi - keo 88, tại thời điểm thích hợp gọi lại
beforeSleepBạn có thể kích hoạt điều này. Hệ thống sẽ kiểm tra xem trong bộ đệm output có bất kỳ dữ liệu kết quả thực thi nào cần gửi cho khách hàng không. Nếu phát hiện cótai ban ca, nó sẽ tiến hành gọi đến chức năng tương ứng.writeToClientBạn có thể thử gửi dữ liệu. Nếu lần đầu tiên không thể hoàn tất việc truyền tải toàn bộ dữ liệutai ban ca, bạn sẽ cần đăng ký lại một sự kiện I/O viết trong vòng lặp sự kiện. Trong trường hợp này, điều quan trọng là phải kiểm tra tình trạng kết nối và đảm bảo rằng bộ đệm dữ liệu đã sẵn sàng trước khi kích hoạt lại sự kiện I/O. Điều này giúp tối ưu hóa hiệu suất và tránh các lỗi không mong muốn. Đồng thời, bạn cũng nên lưu ý quản lý tài nguyên một cách cẩn thận để không làm quá tải hệ thống trong quá trình chờ đợi sự kiện tiếp theo xảy ra.sendReplyToClientĐể cố gắng gửi. Nếu vẫn còn dữ liệu chưa gửi hoàn toànkeo 88, thì sau đó sẽ được kích hoạt lại quy trình này bởiwriteToClientCallback.beforeSleepTóm tắt đơn giảnkeo 88, bài viết này hệ thống ghi lại các quy trình thực thi sau đây:
Quy trình khởi tạo sau khi bắt đầu từ hàm main;
- Nguyên lý và logic thực hiện vòng lặp sự kiện;
- Quy trình hoàn chỉnh từ việc nhận yêu cầu lệnh Rediskeo 88, phân tích và thực hiện lệnh, đến phản hồi kết quả thực thi.
- Bỏ qua nhiều chi tiết của bài viết nàytỷ lệ kèo bóng đá trực tiếp, có lẽ bạn ít nhất có thể nhớ biến toàn cục bảng lệnh Redis:
Để hiểu rõ mã nguồn Redis một cách suôn sẻtỷ lệ kèo bóng đá trực tiếp, bạn cần có kinh nghiệm lập trình C trong môi trường Linux và nắm vững một số kiến thức về hệ thống Linux. Đối với nhiều người, những điều này có thể trở thành rào cản. Do đó, bài viết này ghi lại hệ thống các bước và giải pháp mà tác giả đã thực hiện trong quá trình đọc mã nguồn, đồng thời phân tích các vấn đề khó khăn quan trọng mà tác giả gặp phải. Ngoài ra, bài viết cũng đưa ra một số tài liệu tham khảo để giúp những người muốn tìm hiểu mã nguồn Redis nhưng chưa biết bắt đầu từ đâu có thể có được hướng đi phù hợp hơn. Mong rằng những chia sẻ này sẽ mang lại ít nhiều giá trị cho các bạn đang trên con đường học hỏi.
Tương tự như những gì loạt bài viết này đã làm.
redisCommandTable
Nó được định nghĩa ở phần đầu của tệp nguồn server.c. Tệp này lưu giữ điểm vào cho việc thực thi mỗi lệnh Rediskeo 88, và bạn có thể bắt đầu từ đây để tìm hiểu sâu về các cấu trúc dữ liệu cũng như các hoạt động liên quan bê Bạn sẽ thấy rằng nó giống như một bản đồ dẫn đường, mở ra cánh cửa để khám phá toàn bộ hệ thống phức tạp mà Redis đang vận hành.
Phân tích cấu trúc dữ liệu nội bộ của Redis
Chúc bạn đọc mã nguồn vui vẻ!
(Kết thúc)
Tài liệu tham khảo:
- [1] epoll − I/O event notification facilitytai ban ca, https://man.cx/epoll
- [2] Unix domain sockettai ban ca, https://en.wikipedia.org/wiki/Unix_domain_socket
- [3] Inter-process communicationtỷ lệ kèo bóng đá trực tiếp, https://en.wikipedia.org/wiki/Inter-process_communication
- [4] POSIX.1-2017, http://pubs.opengroup.org/onlinepubs/9699919799/nframe.html
- [5] Definitions for UNIX domain socketstỷ lệ kèo bóng đá trực tiếp, http://pubs.opengroup.org/onlinepubs/9699919799/basedefs/sys_un.h.html
- [6] Create descriptor pair for interprocess communicationtai ban ca, https://man.cx/pipe
- [7] BSD System Calls Manual ACCEPT(2)tai ban ca, https://man.cx/accept(2)
- [8] BSD System Calls Manual READ(2)tỷ lệ kèo bóng đá trực tiếp, https://man.cx/read(2)
- [9] BSD System Calls Manual SELECT(2)tỷ lệ kèo bóng đá trực tiếp, https://man.cx/select(2)
- [10] poll vs select vs event-basedkeo 88, https://daniel.haxx.se/docs/poll-vs-select.html
- [11] BSD System Calls Manual POLL(2)tai ban ca, https://man.cx/poll(2)
- [12] Epoll from Wikipediatai ban ca, https://en.wikipedia.org/wiki/Epoll
- [13] BSD System Calls Manual KQUEUE(2)keo 88, https://man.cx/kqueue
- [14] Kqueue from Wikipediakeo 88, https://en.wikipedia.org/wiki/Kqueue
- [15] illumos from Wikipediatai ban ca, https://en.wikipedia.org/wiki/Illumos
- [16] The C10K problemkeo 88, http://www.kegel.com/c10k.html
- [17] C10k problem from Wikipediatỷ lệ kèo bóng đá trực tiếp, https://en.wikipedia.org/wiki/C10k_problem
- [18] Epoll is fundamentally brokentai ban ca, https://idea.popcount.org/2017-03-20-epoll-is-fundamentally-broken-22/
- [19] The Implementation of epolltai ban ca, https://idndx.com/2014/09/01/the-implementation-of-epoll-1/
- [20] libevent, http://libevent.org/
- [21] libev, https://github.com/enki/libev
Các bài viết được chọn lọc khác :
- Khóa phân tán dựa trên Redis có an toàn không (phần dưới)
- Thảo luận về kinh doanh và nền tảng
- Tìm hiểu về hệ thống phân tán, vấn đề tướng quân và blockchain
- Thế giới ngoài tia sáng thiên niên kỷ
- Chính thống và dị đạo trong công nghệ
- Cuộc phiêu lưu của ba byte
- Nguyên tắc năm so với một trong công nghệ
- Ba cấp độ của kiến thức
Bài viết gốctỷ lệ kèo bóng đá trực tiếp, vui lòng ghi rõ nguồn và bao gồm mã QR bên dưới! Nếu không, từ chối tái bản!
Liên kết bài viết: /dumkj3ht.html
Hãy theo dõi tài khoản Weibo cá nhân của tôi: Tìm kiếm tên "Trương Tiết Lệ" trên Weibo.

Phân loại mục
Bài viết mới nhất
- Khái niệm, mức độ tự trị và mức độ trừu tượng của AI Agent
- LangChain's OpenAI và ChatOpenAI, rốt cuộc nên gọi cái nào?
- Phần tiếp theo của DSPy: Khám phá thêm về o1, Lượng tính tại thời gian suy luận và Tư duy Trong phần này, chúng ta sẽ đi sâu hơn vào thế giới của các mô hình ngôn ngữ lớn, tập trung vào ba khía cạnh quan trọng: o1, lượng tính tại thời gian suy luận (inference-time compute) và khả năng tư duy. O1 là khái niệm chỉ khả năng tự động hóa triệt để trong việc xây dựng các ứng dụng, giúp giảm thiểu sự phụ thuộc vào lập trình thủ công truyền thống. Điều này mở ra cánh cửa cho một tương lai nơi trí tuệ nhân tạo có thể tự tạo ra các giải pháp mà không cần sự can thiệp quá nhiều từ con người. Tiếp theo là vấn đề lượng tính tại thời gian suy luận. Đây là khái niệm liên quan đến lượng tài nguyên máy tính cần thiết để thực hiện các phép tính khi mô hình đưa ra kết quả dự đoán. Với những mô hình phức tạp như GPT-3 hay các hệ thống AI khác, việc tối ưu hóa lượng tính toán tại thời gian suy luận là vô cùng quan trọng. Nó không chỉ ảnh hưởng đến hiệu suất tổng thể mà còn quyết định chi phí vận hành hệ thống. Cuối cùng, chúng ta sẽ thảo luận về khả năng tư duy của các mô hình AI. Liệu chúng thực sự có thể "nghĩ" giống như con người? Hay chỉ đơn thuần là một chuỗi các thuật toán được lập trình sẵn? Đây là câu hỏi gây tranh cãi trong cộng đồng khoa học và công nghệ, và việc tìm hiểu sâu hơn về chủ đề này sẽ giúp chúng ta có cái nhìn rõ ràng hơn về tiềm năng cũng như giới hạn của trí tuệ nhân tạo trong tương lai gần.
- Nói chuyện về DSPy và kỹ thuật tự động hóa gợi ý (phần giữa)
- Nói chuyện về DSPy và kỹ thuật tự động hóa gợi ý (phần đầu)
- Giải thích một chút: Phân tích nguyên lý xác suất đằng sau LLM
- Bắt đầu từ Vương Tiểu Bảo: Giới hạn đạo đức và quan điểm thiện ác của người bình thường
- Xem xét lại thông tin từ GraphRAG
- Những điều thay đổi và không thay đổi trong sự thay đổi công nghệ: Làm thế nào để tạo ra token nhanh hơn?
- Thể trí thông minh doanh nghiệp, số hóa và phân công ngành nghề